首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
其他好文
> 详细
4.1 MapReduce架构(1.0)
时间:
2015-06-12 20:48:18
阅读:
173
评论:
0
收藏:
0
[点我收藏+]
标签:
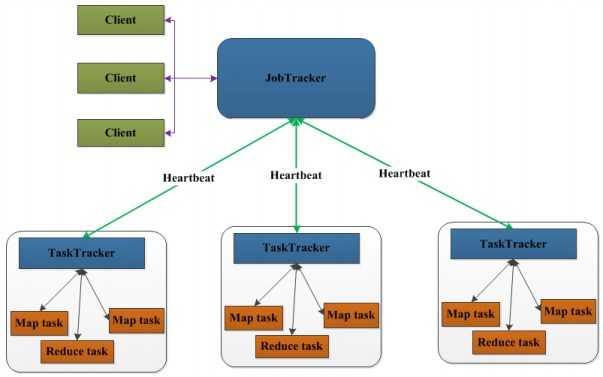
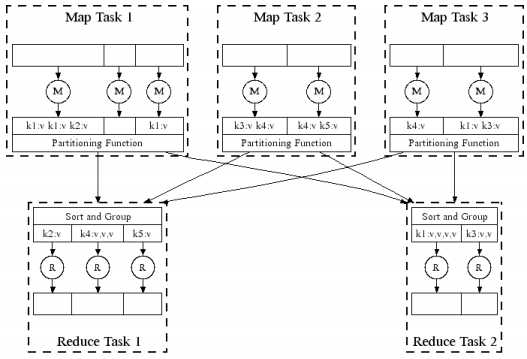
1. MapReduce架构:
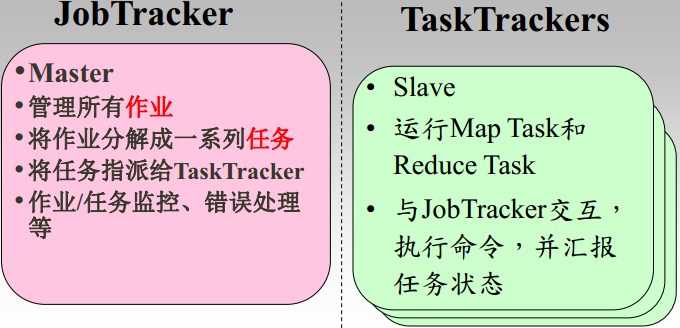
各个角色的功能:
2. MapReduce——容错性:
JobTracker
单点故障,一旦出现故障,整个集群不可用
TaskTracker
周期性向JobTracker汇报心跳
一旦出现故障,上面所有任务将被调度到其他节
点上
MapTask/ReduceTask
运行失败后,将被调度到其他节点上重新执行
3. MapReduce—资源组织方式:
机器用“slot”描述资源数量
由管理员配置slot数目(一般根据CPU,如一个cpu运行两个进程)
分为map slot和reduce slot两种,
从一定程度上,可看做“任务运行并发度”
Map slot
可用于运行Map Task的资源
每个Map Task可使用一个或多个map slot
Reduce slot
可用于运行ReduceTask的资源
每个Reduce Task可使用一个或多个reduce slot
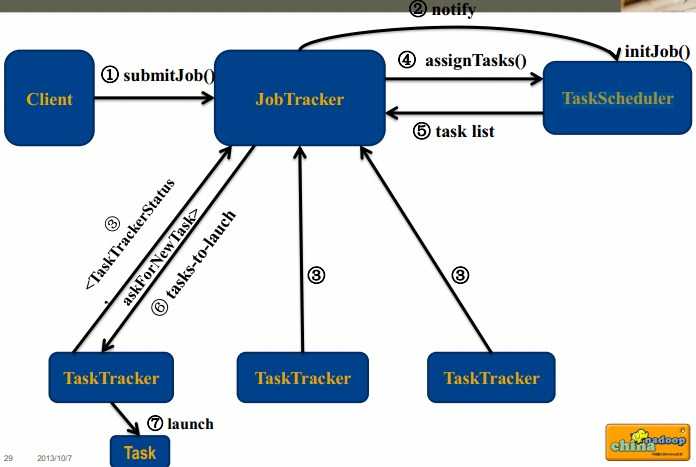
4. MapReduce—TaskScheduler(任务调度)
基本作用
根据节点资源(slot)使用情况和作业的要求,将
任务调度到各个节点上执行
调度器考虑的因素
作业优先级
作业提交时间
作业所在队列的资源限制
作业调度流程图
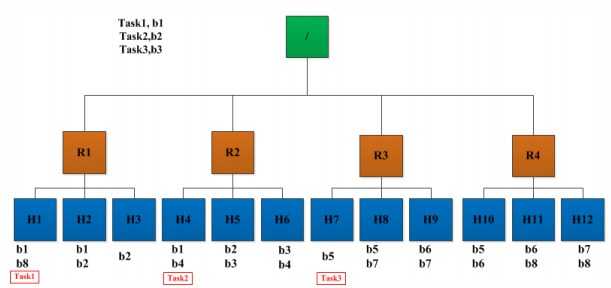
5. MapReduce—数据本地性
什么是数据本地性(data locality)
如果任务运行在它将处理的数据所在的节点,则称该任务
具有“数据本地性”
本地性可避免跨节点或机架数据传输,提高运行效率
数据本地性分类
同节点(node-local)
同机架(rack-local)
其他(off-switch)
6. MapReduce—任务并行执行
7. MapReduce—推测执行机制
作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map任务和Reduce任务构成,
因硬件老化、软件Bug等,某些任务可能运行非常慢
推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度
为拖后腿任务启动一个备份任务,同时运行
谁先运行完,则采用谁的结果
不能启用推测执行机制
任务间存在严重的负载倾斜
特殊任务,比如任务向数据库中写数据
来自为知笔记(Wiz)
4.1 MapReduce架构(1.0)
标签:
原文地址:http://www.cnblogs.com/51runsky/p/4572428.html
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
分布式事务
2021-07-29
OpenStack云平台命令行登录账户
2021-07-29
getLastRowNum()与getLastCellNum()/getPhysicalNumberOfRows()与getPhysicalNumberOfCells()
2021-07-29
【K8s概念】CSI 卷克隆
2021-07-29
vue3.0使用ant-design-vue进行按需加载原来这么简单
2021-07-29
stack栈
2021-07-29
抽奖动画 - 大转盘抽奖
2021-07-29
PPT写作技巧
2021-07-29
003-核心技术-IO模型-NIO-基于NIO群聊示例
2021-07-29
Bootstrap组件2
2021-07-29
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!