标签:
Licstar的文章开头这么提到:语言(词、句子、篇章等)属于人类认知过程中产生的高层认知抽象实体,而语音和图像属于较为底层的原始输入信号。
语音、图像数据表达不需要特殊的编码,而且有天生的顺序性和关联性,近似的数字会被认为是近似特征。然而语言就麻烦了。
比如通俗的One-hot Representation就是一种不是很好的编码方式,编出来的数据比图像、语音的信号表达方式差很多。
还可以对比的是:统计数据。为什么数据挖掘模型简单?因为统计数据是人工build出来的,特征维度特低,是经过人脑这个大杀器提炼出来的超浓缩特征。
所以数据挖掘不需要深度学习啊,特征提取啊什么的,而且也没法这么做。大数据下,你跑个十几层的神经网络试试?
在NLP中,表达一个句子很简单。比如CV loves NLP,只要我们对所有单词建立一个词库。
那么CV loves NLP 可以表示成二进制编码[0,1,0,0,0,1,0,0,1],即出现的词是1,不出现为0。
这就是著名的One-hot Representation特征表示法,用它能完成NLP中的很多任务,然而就这么满足了?
那么问题来了,NLP loves CV和CV loves NLP不是一坨了?这是致命问题之一:语序
通常一个词库的大小是10^5,如果继续用二进制编码。那么一个句子的维度是10^5。
要知道,AlexNet的一张图片维度才256*256=65536, 就得拿GPU算好久,10^5基本得完蛋了。
实际上,10^5里,大部分都是维度都是废的,真正有用的特征就藏在那么几个维度中。
这说明,One-hot Representation表达的特征维度过高,需要降维。然而,这还不是最坑爹的缺陷。
Bengio在2003年的A neural probabilistic language model中指出,维度过高,导致每次学习,都会强制改变大部分参数。
由此发生蝴蝶效应,本来很好的参数,可能就因为一个小小传播误差,就改的乱七八糟。
实际上,传统MLP网络就是犯了这个错误,1D全连接的神经元控制了太多参数,不利于学习到稀疏特征。
CNN网络,2D全连接的神经元则控制了局部感受野,有利于解离出稀疏特征。
吴军博士写的《数学之美》里面科普了著名的N-Gram模型(N元模型)。
在一个句子当中,一个单词的T出现的概率,和其前N个单词是有关的。$P(t|t-1,t-2,....t-N)$
当然数学之美中并没有提及词向量,早期的N-Gram模型是用来求解一个句子的信度的。
即:把每个单词的概率连乘,谁的概率大,哪个句子就可信。$\max\prod _{t=1}^{T}P(t|t-1,t-2...t-N)$
为了计算$P(t|t-1,t-2,....t-N)$,最简单的是基于词频统计计算联合概率。
麻烦之处,在于低频词概率过小,甚至为0,导致模型不平滑。
于是,最先提出来的卡茨退避法用于人工修正出平滑模型,放在今天,略显笨拙。
因为我们有强大的基于统计模型的Adaptive Perception的神经网络。
• I like deep learning.
• I like NLP.
• I enjoy flying.
假设有这么3个句子成为我们的语料库,并且我们注意到了词之间关联性问题。
使用一种新的编码来形成一个离散统计矩阵,取上下文关联词数目=1。
| 统计 | I |
like | enjoy | deep | learning | NLP | flying | . |
| I | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 |
| like | 2 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| enjoy | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| deep | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| learning | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| NLP | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| flying | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| . | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
对这个矩阵进行SVD奇异值分解后,得到三个矩阵U阵(n*r)、S阵(r*r)、VT阵(r*m)
传统的PCA使用的是特征值分解来降维,比较麻烦。
其实奇异值分解SVD也可以。若要用奇异值降维,则取U阵即可,n为数据个数,r为降维的新维度。
Python中代码如下:
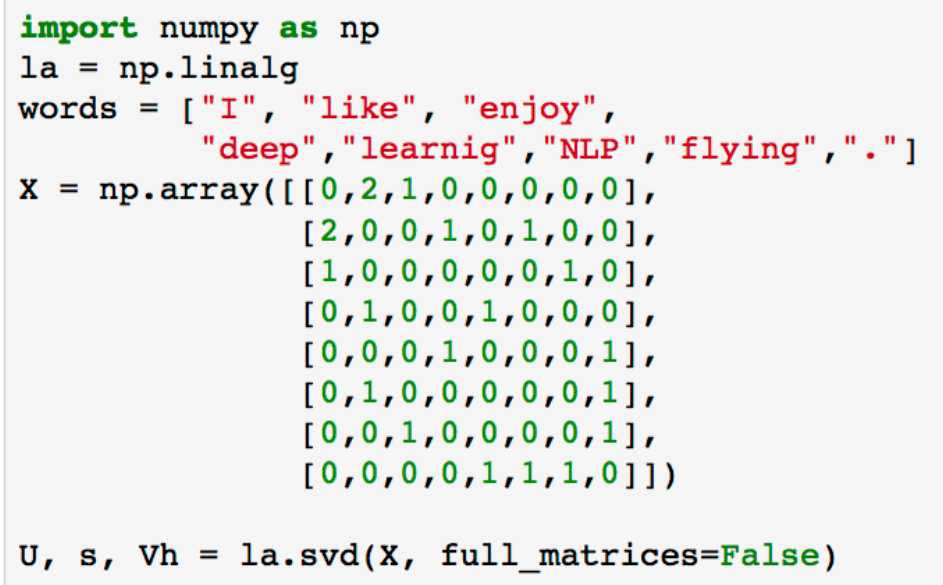
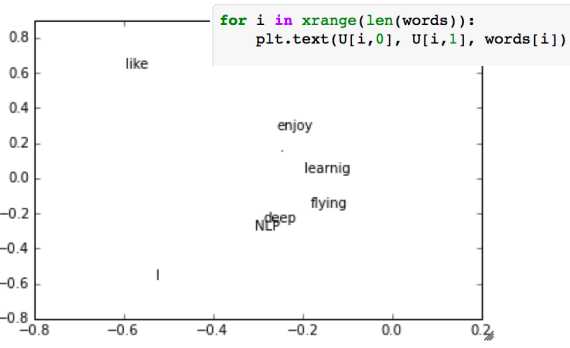
将U阵前两维度画出来之后,大概是这个样子
可以看到,从9维降到2维之后,一些语意、语法比较近的词被聚在了一起。
这说明,词向量的特征可以控制在较低的维度。
最早提出用神经网络做NLP是华裔牛人徐伟(原Facebook,现百度IDL研究院),提出了NN训练2-Gram的方法。
正式训练N-Gram的模型由Bengio在2001&2003年提出,即前面的A neural probabilistic language model。
其结构就是简单的MLP网络+Softmax回归,有点今天DL味道。(早期MLP的输出层是不用Softmax的)。
Bengio把训练出来的词向量称之为Distributed Represention,对抗One-hot Representation。
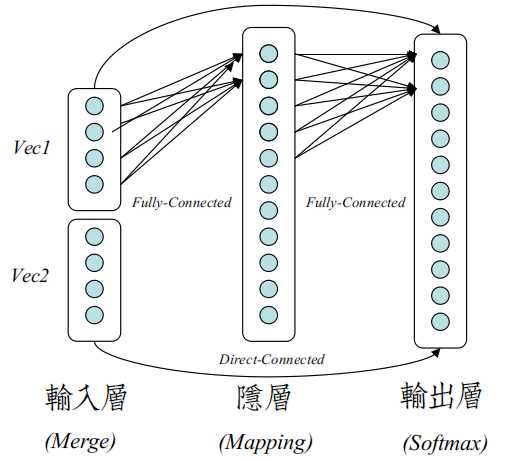
在输入层中,每个Word被定义成一个维度$|M|$ (100 or 200 or 300)固定的低维连续性向量。
在一个句子当中,跑到第$i$个词时,把前n个词向量连在一起,组成一个$|N|*|M|$的输入向量。
在隐层中,将输入映射到高层空间,并通过Sigmoid函数激活。
在输出层,是一个大小为$|V|$的输出层,V是整个词库大小(通常10^5)。
目标函数:$arg\max\limits_{Vec\&W}\prod _{t=1}^{T}P(t|t-1,t-2...t-N)$, T一个句子中的词数。
即基于前N个词,预测当前词,使得预测当前词的Softmax概率分支最大,$P(t|t-1,t-2...t-N)=\frac{e^{W_{t}X+b_{t}}}{\sum_{i=1}^{V}e^{W_{i}X+b_{i}}}$
即需要训练输入层的词向量参数,隐层的W&b,Softmax的W&b。
和传统NN不同之处,除了多训练词向量之外,还多了输入层到输出层线性直连边(Direct-Connected)。
原因是BP算法的通病:Gradient Vanish问题,误差经过隐层到输入层时候,梯度已经丢失太多,影响训练速度,所以引入直连边,加速训练。
Bengio在当时论文中这么描述到 "然而并没有什么卵用(it would not add anything useful)",不过,这个直连边倒是催生了Word2Vec的诞生。
神经网络方法训练出来的$P(t|t-1,t-2...t-N)$自带平滑,完全符合了Hinton提出的Adaptive Perception(自适应感知)原则。
其实下一个词预测是否准确和词向量训练关系并不大。Licstar的文章后续介绍了Collobert&Weston的SENNA模型。
Collobert&Weston都是NLP和神经计算方面的年轻学者,Jason Weston还受邀在CS224d开了一节宣传课,讲他的Mermory Networks.
SENNA模型中,目标函数不再是预测下一个词,而是换成了单个输出神经元,正负采样为下一个词打分,做回归分析。
显然,最后神经网络会训练成,为合理句子打高分,不合理的句子打低分。结果,他们仍然训练出了出色的词向量。不过只是附带品。
那么词向量究竟和什么有关,答案是$Context$,即上下文。只要训练模型中带有上下文,那么网络就会自动往训练句子方向跑。如:
• I like CV
• I like NLP
在训练I like NLP的时候,由于上下文关系,NLP的误差修正会近似于CV的误差修正。
这样,CV和NLP这两个语法相近的词,会被无监督的聚在一起。
Richard Socher在他的Deep Learning for NLP Leture4中说到:词向量的训练类似于深度学习中的Pre-Training,
词向量本身可以看成是个PCA,这个PCA还能自我学习,自我学习的PCA不就是RBM&AutoEncoder吗?可以参考这篇科普。
为什么可以看成是Pre-Training,而不是放到实际分类&回归模型中训练的原因,他举了下面这个例子:
•假定:训练一个二分类模型,语料来源:电影评论,任务:分析评论的情感
•情况:训练集负类中出现TV、telly,测试集中负类出现television (估计评论者是想骂:这电影怎么垃圾得就像电视剧一样)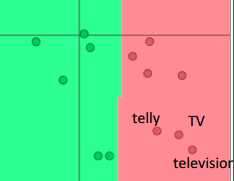
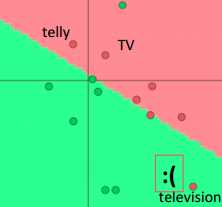
左图是词向量无监督Pre-training后,再监督Fine-Tuning的测试结果,右图则是直接Train。
尽管television没有参加分类训练,但是由于其预训练的词向量和telly、TV比较近,所以容易被分对。
这就是为什么词向量方法是属于Deep Learning阵营的原因。
Richard Socher在他的Deep Learning for NLP Leture4提到,单独训练词向量的另一个原因就是词库$|V|$过大。
不适合在NLP任务中计算。实际上,词向量训练作为Pre-Training部分,最较特殊的地方在于其输入是可训练的。
对于一般的固定输入的模式识别问题,裸线性神经网络模型(Logistic&Softmax回归)早已被废弃多年。
原因是,除了一些统计数据,基本很少有数据是呈线性相关的,必须加上隐层(或支持向量)获得处理非线性数据能力。
但是词向量的输入可变,也就是说,我用线性模型,肯定有误差,要是顺着误差把输入也给一锅端了。
那么输入数据会被强制修改成线性相关,这是Bengio当年没有想到的,因为当初大家都认为非线性模型训练出来的参数好。
来自Google的年轻学者Tomas Mikolov就发现了这一点,将Bengio模型中的隐层移除,结果得出来向量呈大量线性相关。
于是有了下面的神奇之处:$Vec(King)-Vec(Man)+Vec(Woman)\approx Vec(Queen)$
如果把线性的词向量输入到超级非线性的神经网络会怎么样?实际上这是非常赞的一件事。
因为即便是神经网络,基本计算也不过是输入间乘以W再加加减减,没有必要把输入卡成多么复杂的非线性奇葩。
线性就好,非线性部分应当交给神经网络去做,这样兼顾了速度和精度。
这样的流程大概就是:词向量线性Pre-Traning=>神经网络非线性Pre-Traning=>神经网络Fine-Tuning
Deep Learning正式向NLP发起战斗的炮火!
标签:
原文地址:http://www.cnblogs.com/neopenx/p/4570648.html