标签:
提升方法的基本思路
在概率近似正确(probably approximately correct,PAC)学习的框架中,
一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的;
一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。
Schapire后来证明强可学习与弱可学习是等价的,也就是说,在PAC学习的框架下,
一个概念是强可学习的充分必要条件是这个概念是弱可学习的。
?
对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易得多。
提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。
大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。
?
对提升方法来说,有两个问题需要回答:
一是在每一轮如何改变训练数据的权值或概率分布;
二是如何将弱分类器组合成一个强分类器。
第1个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。
那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注。于是,分类问题被一系列的弱分类器"分而治之"。
第2个问题,即弱分类器的组合,AdaBoost采取加权多数表决的方法。
加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,‘
减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
?
AdaBoost算法
训练数据集
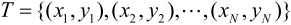
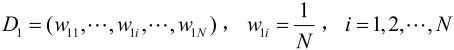
使用具有权值分布Dm的训练数据集学习,得到基本分类器:
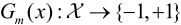
计算Gm(x)在训练数据集上的分类误差率:
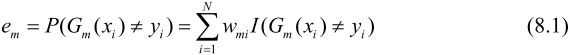
计算Gm(x)的系数

更新训练数据集的权值分布:
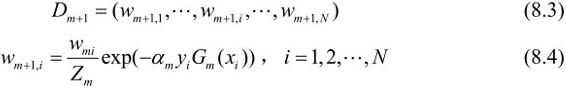
Zm是规范化因子:
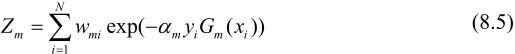

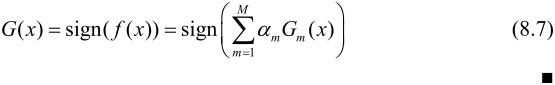
AdaBoost说明:
这一假设保证第1步能够在原始数据上学习基本分类器G1(x)
1.使用当前分布Dm加权的训练数据集,学习基本分类器Gm(x)。
2.计算基本分类器Gm(x)在加权训练数据集上的分类误差率:
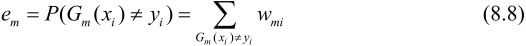
这里,wmi表示第m轮中第i个实例的权值.
这表明,Gm(x)在加权的训练数据集上的分类误差率是被Gm(x)误分类样本的权值之和,
由此可以看出数据权值分布Dm与基本分类器Gm(x)的分类误差率的关系
3. 计算基本分类器Gm(x)的系数am。am表示Gm(x)在最终分类器中的重要性。
当em≤1/2时,am≥0,并且am随着em的减小而增大,
所以分类误差率越小的基本分类器在最终分类器中的作用越大。
4.更新训练数据的权值分布为下一轮作准备
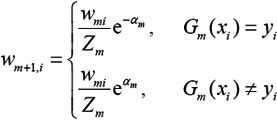
被基本分类器Gm(x)误分类样本的权值得以扩大,而被正确分类样本的权值却得以缩小
误分类样本在下一轮学习中起更大的作用。
不改变所给的训练数据,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用
?
AdaBoost的例子
弱分类器由x<v或x>v产生, 其阈值v使该分类器在训练数据集上分类误差率最低.

初始化数据权值分布
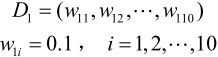
对于m=1
在权值分布为D1的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为
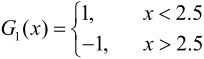
G1(x)在训练数据集上的误差率e1=P(G1(xi)≠yi)=0.3。
计算G1(x)的系数:
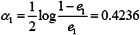
更新训练数据的权值分布:
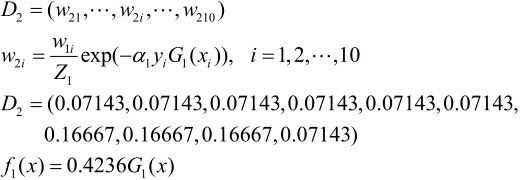
分类器sign[f1(x)]在训练数据集上有3个误分类点。
对于m= 2
在权值分布为D2的训练数据上,阈值v是8.5时分类误差率最低,基本分类器为
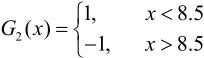
G2(x)在训练数据集上的误差率e2=0.2143
计算a2=0.6496
更新训练数据权值分布:
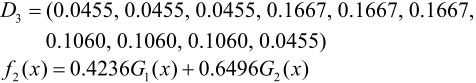
分类器sign[f2(x)]在训练数据集上有3个误分类点。
对于m = 3:
在权值分布为D3的训练数据上,阈值v是5.5时分类误差率最低,基本分类器为
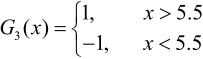
计算a3=0.7514
更新训练数据的权值分布
D4=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
得到:
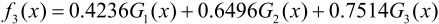
?
?
AdaBoost算法的训练误差分析
AdaBoost算法最终分类器的训练误差界为:
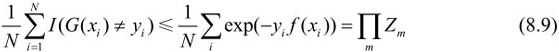


这表明在此条件下AdaBoost的训练误差是以指数速率下降的
?
?
AdaBoost算法的解释
可以认为AdaBoost算法是
模型为加法模型
损失函数为指数函数
学习算法为前向分步算法
的二分类学习方法
?
加法模型

其中b(x;γm)为基函数的参数,βm是基函数的系数。

如上式所示为一加法模型。
在给定训练数据及损失函数L(Y,f(X))的条件下,学习加法模型f(x)成为经验风险极小化即损失函数极小化问题:
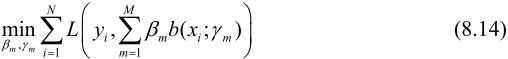
前向分步算法(forward stagewise algorithm)求解这一优化问题的想法是
因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,
逐步逼近优化目标函数式(8.14),那么就可以简化优化的复杂度。
就是优化如下函数:

初始化f0(x)=0,对m=1,2,…,M,极小化损失函数
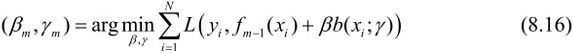
计算得到γm ,βm
更新fm
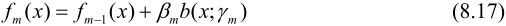
获得加法模型
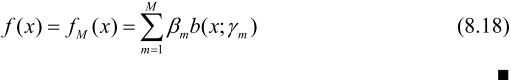
?
前向分步算法与AdaBoost
由前向分步算法可以推导出AdaBoost
AdaBoost算法是前向分歩加法算法的特例。
这时,模型是由基本分类器组成的加法模型,损失函数是指数函数。
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
标签:
原文地址:http://www.cnblogs.com/LauenWang/p/4574079.html