标签:
Trie,来源于(retrieval,取回,数据检索),是一种多叉树,用来存储字母表上的单词非常有用。
Trie经常用来存储动态集合(dynamic set)或者关联数组(associative array),其中的key通常是字符串。跟二叉搜索树不同的是,树中的结点不存储相关的key,而是靠结点在树中的位置来定义key。
在单词拼写检查或者一些能理解自然语言的程序中可以用来存储单词字典。
树中一个结点的所有子孙具有公共前缀。根结点root代表的是空字符串。不是所有的结点都有值。叶子结点和一部分非叶子结点关联着key,也就是所谓的值。
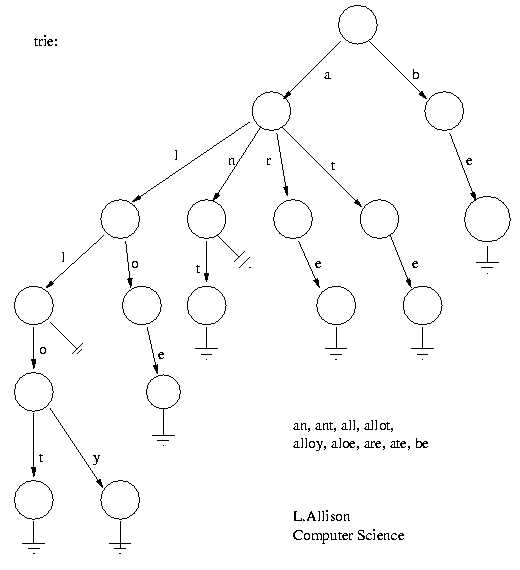
给定数据:
an,ant,all,allot,alloy,aloe,are,ate,be
相应的trie:
如果字符串的字符集仅是a-z,那么一个节点最多有27个孩子结点(26个字母+1个终止符)。
实现
1、快速但浪费空间,在靠近树的底部将会有大量的null子树,这将浪费大量空间。
type trie = ^ node;
node = record
subtrie :array[‘a‘..‘z‘] of trie;
IsEndOfWord :boolean
end;
2、每个结点用一个长度最长为27的链表来表示,链表中的元素用键值对<char,trie>来表示。在这种情况下,在叶子结点处浪费的空间比较少。
function find(word:string; length:integer; t:trie):boolean;
function f(level:integer; t:trie):boolean;
begin if level=length+1 then
f:=t^.IsEndOfWord
else if t^.subtrie[word[level]]=nil then
f:=false
else f:=f(level+1, t^.subtrie[word[level]])
end{f};
begin find := f( 1, t )
end{find}
查找
def find(node, key):
for char in key:
if char not in node.children:
return None
else:
node = node.children[char]
return node.value
插入
algorithm insert(root : node, s : string, value : any):
node = root
i = 0
n = length(s)
while i < n:
if node.child(s[i]) != nil:
node = node.child(s[i])
i = i + 1
else:
break
(* append new nodes, if necessary *)
while i < n:
node.child(s[i]) = new node
node = node.child(s[i])
i = i + 1
node.value = value
作为hash table的替换
相对于hash table,具有如下优点:
1、在最坏情况下查找也具有O(m)(m是字符串的长度)的时间复杂度。优于hash table在最坏情况下(碰撞)的O(N)。
2、Trie没有碰撞。
3、当更多的key加入到Trie中时,不需要提供或者替换hash函数。
4、Trie可以提供按字母表排序的词条条目。
当然,也同样有缺点:
1、如果数据保存在随机访问速度比主存慢的硬盘或者一些辅存中,Tries在查找数据时会比hash tables慢。
2、对于浮点数这种key,将会导致很长一串没什么意义的前缀。
3、一些Tries要求的空间比hash table大。因为在Trie中都是为单个的字符单独分配空间,而hash table为整个条目分配一个数据块。
排序
对一个集合的字典序排序可以通过Trie来实现:
1、将所有keys插入Trie。
2、先序遍历输出所有的keys。
这也是一种基数排序。
参考资料
wikipedia
Tries前缀树
标签:
原文地址:http://www.cnblogs.com/codetravel/p/4574230.html