标签:
(使用 pika 0.9.8 Python客户端)
在第二篇教程中,我们学习了如何使用工作队列在多个workers之间分发耗时的任务。
但是假使我们需要在一台远程的计算机上执行一个函数并等待结果呢?那就将是一件不同的事情了。这种模式通常被称为远程过程调用或RPC。
在这份教程中,我们将使用RabbitMQ来构建一个RPC系统:一个客户端和一个可伸缩的RPC服务器。由于我们没有任何耗时的任务值得分发,我们将创建一个虚拟的RPC服务来返回Fibonacci数。
为了描述如何使用一个RPC服务,我们将创建一个简单的客户端类。它将暴露一个名为call的方法,而该方法将发送一个RPC请求,并阻塞直到接到回答。
fibonacci_rpc = FibonacciRpcClient() result = fibonacci_rpc.call(4) print "fib(4) is %r" % (result,)
尽管RPC是计算领域一个相当常见的模式,但它常常受到批评。问题来自于程序员没有意识到一个函数调用是否是本地的时或如果它是一个慢RPC。困扰诸如导致了一个不可预知的系统并增加了不必须的调试复杂性。不仅没能简化软件,误用RPC还可能导致不可维护的意大利面条式的代码。
牢记,考虑下面的建议:
有疑问时避免使用RPC。如果可以,你应该使用一个异步的管道 - 而不是RPC - 如阻塞,结果被异步地推进下一个计算步骤。
回调队列
通常基于RabbitMQ执行RPC很简单。一个客户端发送一个请求消息,而一个服务器以一个响应消息来应答。为了接收一个响应,客户端需要在请求中发送一个‘callback‘队列地址。让我们來试一下:
result = channel.queue_declare(exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange=‘‘,
routing_key=‘rpc_queue‘,
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)
# ... and some code to read a response message from the callback_queue ...
AMQP协议预定义了伴随一个消息一起发送的14种属性。大多数属性很少被用到,除了如下的这些:
在上面出现的方法中我们为每个RPC请求创建了一个callback队列。那相当没有效率,幸运地是有一个更好的方式 - 让我们为每个客户端创建一个单独的callback 队列。
那产生了一个新的问题,在那个队列中接收的响应到底属于哪个请求不是很清楚。那正是correlation_id属性应用的场合。我们将为每个请求设置一个唯一的值。稍后,当我们从callback队列中接收一条消息时,我们将查看这个属性,基于它我们将能够把一个响应与一个请求匹配起来。如果我们看到一个未知的correlation_id值,我们可以安全地丢弃消息 - 它不属于我们的请求。
你可能会问,我们为什么要忽略callback队列中的未知消息,而不是以一个error而failing?那是由于可能会在服务器端产生一个race condition。尽管可能性不大,RPC服务器可能在将答案发送给我们之后,但在为请求发送一个确认消息之前就死掉。如果发生了那种事,则重启后的RPC服务器将再次处理请求。那就是为什么在客户端上,我们必须优雅地处理重复的响应,而RPC应该是理想地幂等的。
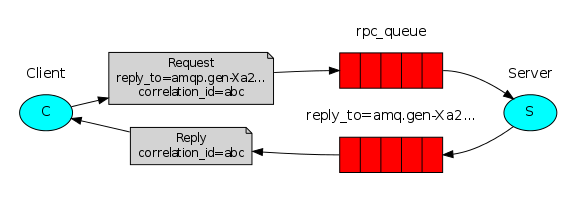
我们的RPC将像这样来工作:
rpc_server.py的代码:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host=‘localhost‘))
channel = connection.channel()
channel.queue_declare(queue=‘rpc_queue‘)
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print " [.] fib(%s)" % (n,)
response = fib(n)
ch.basic_publish(exchange=‘‘,
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue=‘rpc_queue‘)
print " [x] Awaiting RPC requests"
channel.start_consuming()
服务器端的代码相当直接:
rpc_client.py的代码:
#!/usr/bin/env python
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host=‘localhost‘))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange=‘‘,
routing_key=‘rpc_queue‘,
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print " [x] Requesting fib(30)"
response = fibonacci_rpc.call(30)
print " [.] Got %r" % (response,)
客户端代码要稍微复杂一点:
我们的RPC服务现在准备好了。我们可以启动服务器:
要请求一个Fibonacci数,则执行客户端:
当前的设计不是一个RPC服务仅有的可能的实现,但它有一些重要的优势:
我们的代码仍然是过分简化了的,而没有去解决更复杂(但重要)的问题,比如:
此种方式实现的RPC,是否可以应对,同一个客户端同时发出多个RPC请求的情况?
(rpc_client.py和rpc_server.py 的完整代码)。
Done。
原文地址。
标签:
原文地址:http://my.oschina.net/wolfcs/blog/466459