标签:
1. 来源和特点
源自于Google的MapReduce论文 :
发表于2004年12月
Hadoop MapReduce是Google MapReduce克隆版
特点:
易于编程
良好的扩展性
高容错性
适合PB级以上海量数据的离线处理
不擅长的方面:
实时计算
像MySQL一样,在毫秒级或者秒级内返回结果
流式计算
MapReduce的输入数据集是静态的,不能动态变化
MapReduce自身的设计特点决定了数据源必须是静态的(为了容错性)
DAG计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出
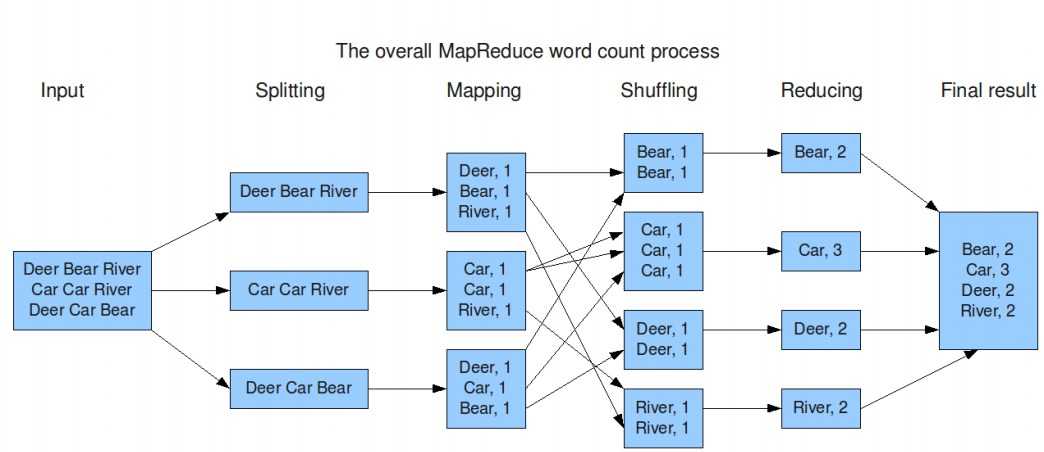
2. MapReduce 过程分析 —— wordcount
1. Input : 一系列key/value对
用户提供两个函数实现:map(k,v) --> list(k1,v1) ; reduce(k1,list(v1)) --> v2
2. output: (k2, v2)
详细见下图:
具体组件:
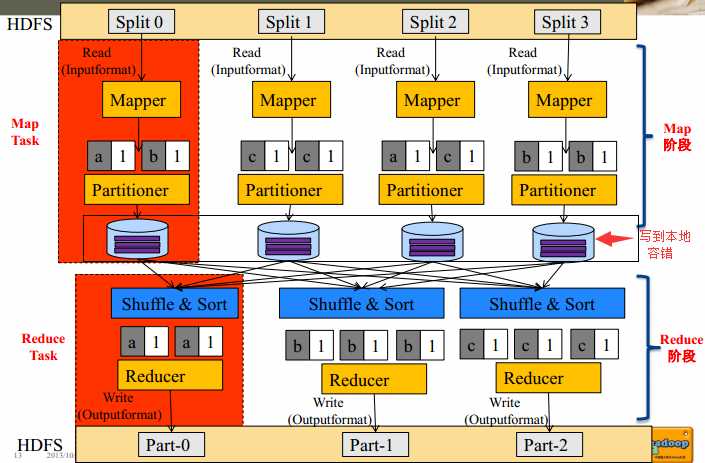
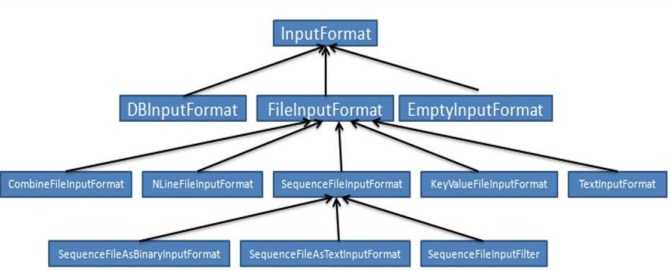
1. InputFormat :
文件分片(InputSplit)方法
处理跨行问题
将分片数据解析成key/value对
默认实现是TextInputFormat
TextInputFormat
Key是行在文件中的偏移量,value是行内容
若行被截断,则读取下一个block的前几个字符
2. Split 与 Block :
Block
HDFS中最小的数据存储单位,默认是64MB
Spit
MapReduce中最小的计算单元
默认与Block一一对应
Block与Split
Split与Block是对应关系是任意的,可由用户控制
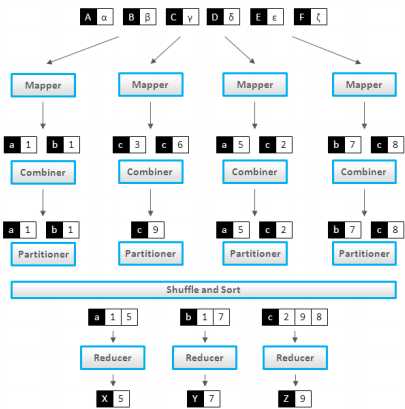
3. Combiner (local reduce)
Combiner可做看local reducer
合并相同的key对应的value(wordcount例子)
通常与Reducer逻辑一样
好处
减少Map Task输出数据量(磁盘IO)
减少Reduce-Map网络传输数据量(网络IO)
4. Partitioner
Partitioner决定了Map Task输出的每条数据交给哪个Reduce Task处理
默认实现:hash(key) mod R
R是Reduce Task数目,允许用户自定义
很多情况需自定义Partitioner
比如“hash(hostname(URL)) mod R”确保相同域名的网页交给同一个Reduce Task处理
5. 总结
Map阶段
InputFormat(默认TextInputFormat)
Mapper
Combiner(local reducer)
Partitioner
Reduce阶段
Reducer
OutputFormat(默认TextOutputFormat
4. MapReduce
标签:
原文地址:http://www.cnblogs.com/51runsky/p/fa4edf8bf3387103685eff494981daad.html