a.collection:List(ArrayList,LinkedList)和Set(HashSet,TreeSet,LinkedHashSet)
注意:List,Set,Map将持有对象一律视为Object型别。
Collection、List、Set、Map都是接口,不能实例化。
继承自它们的 ArrayList, Vector, HashTable, HashMap是具象class,这些才可被实例化。
2.Collection是最基本的集合接口,声明了适用于JAVA集合(只包括Set和List)的通用方法。 Set 和List 都继承了Conllection,Map。
(1)List
特点:有序,每个元素带有idx,存入元素可重复
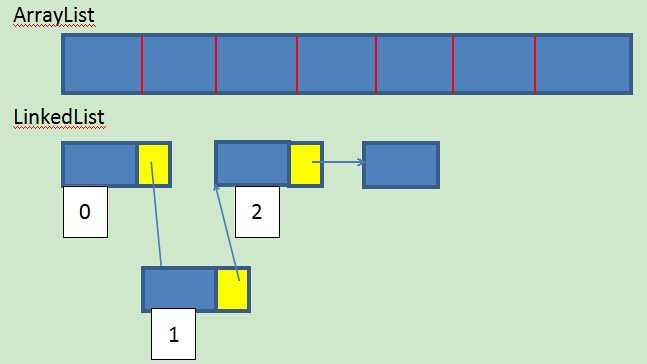
- ArrayList:有序(即输出时按索引顺序输出),每个元素带有index,可增长的数组
- LinkedList:有序(即输出时按索引顺序输出),每个元素带有index,可增长的数组,采用链表结构,提高插入、删除、修改元素的性能
add()/get(idx)
iterator()/remove(idx)
remove(Object obj)
addFirst()/addLast()
getFirst()/getLast()
removeFist()/removeLast()
size()
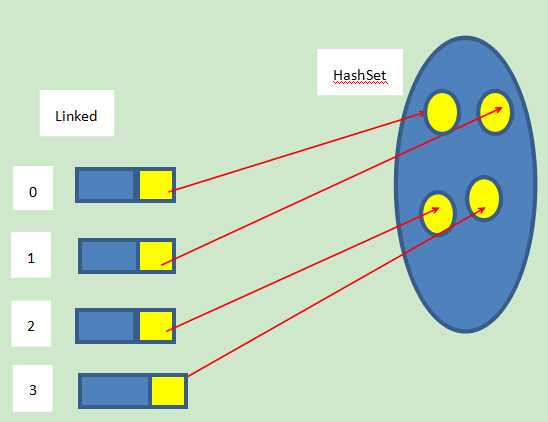
(2)Set是最简单的一种集合。集合中的对象不按特定的方式排序,并且没有重复对象。
特点:无序,对值不允许重复,只有存的方法add(),没有取得方法,其取值只能用Iterator迭代器实现
- HashSet: HashSet类按照哈希算法来存取集合中的对象,存取速度比较快;当值重复时,先比对hashCode 再比对equals
- LinkedHashSet:对顺序访问进行了优化,向List中间插 入与删除的开销并不大。随机访问则相对较慢。(使用ArrayList代替。)
还具有下列方 法:addFirst(), addLast(), getFirst(), getLast(), removeFirst() 和 removeLast(), 这些方法 (没有在任何接口或基类中定义过)使得LinkedList可以当作堆栈、队列和双向队列使用。
通过(Linked)链表达到有序,自身数据存储是无序
- TreeSet:TreeSet类实现了SortedSet接口,能够对集合中的对象进行排序。 有序(即输出时按索引顺序输出)
- 常用方法:
add()/size()
iterator()
remove(Object)
isEmpty()
3.Map(映射) 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
- HashMap: Map基于散列表的实现。插入和查询“键值对”的开销是固定的。可以通过构造器设置容量capacity和负载因子load factor,以调整容器的性能。
- TreeMap: 基于红黑树数据结构的实现。查看“键”或“键值对”时,它们会被排序(次序由Comparabel或Comparator决定)。TreeMap的特点在 于,你得到的结果是经过排序的。TreeMap是唯一的带有 subMap()方法的Map,它可以返回一个子树。
- LinkedHashMap: 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,或者是最近最少使用(LRU)的次序。只比HashMap慢一点。而在迭代访问时发而更快,因为它使用链表维护内部次序。
二.迭代器
1.常用的函数
next():当前所指行是否有数据,有的话取得当前行的数据(boolean)
hasnext():当前所指行的下一行是否有数据(boolean)
2.Map的三种迭代方法
public static void main(String[] args) {
// TODO Auto-generated method stub
//map(),以键值对的形式存储数据,其中键是唯一标识
Map map= new HashMap();
map.put(1, new News("1", "title1","张三" ,new Date()));
map.put(2, new News("2", "title2","李四" ,new Date()));
map.put(3, new News("3", "title3","张三" ,new Date()));
map.put(3, new News("3", "title4","张三" ,new Date()));
//注释:此时title4会覆盖title3
News news=(News)map.get(2);
System. out.println(news.getNo()+"-->" +news.getTitle());
System. out.println(map.size());
System. out.println("==================" );
//第一种迭代方法---取键
Set keys=map.keySet();/返回集合Set,此集合存放map集合中的所有的键值
Iterator i=keys.iterator();
while(i.hasNext()){
int key=(Integer)i.next();
News item=(News)map.get(key);
System. out.println(item.getNo()+"--" +item.getTitle());
}
System. out.println("-------------------" );
//第二种迭代方法---取值
Collection values=map.values();
Iterator j=values.iterator();
while(j.hasNext()){
News news1=(News)j.next();
System. out.println(news1.getNo()+"--" +news1.getTitle());
}
System. out.println("¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥" );
//第三种迭代方法---entrySet取得map集合中的键和值
Set entrySet=map.entrySet();
Iterator iterator=entrySet.iterator();
while(iterator.hasNext()){
Entry e=(Entry ) iterator.next();
int key=(Integer)e.getKey();//取键
News value=(News)e.getValue(); ////取值
System. out.println("key:" +key+"\nvalue:" +value.getTitle());
}
}
参考网址:http://www.cnblogs.com/jbelial/archive/2013/03/30/2990935.html
所谓泛型就是允许在定义类、接口时指定类型形参,这个类型形参将在声明变量、创建对象时确定。增加了泛型支持后的集合,完全可以记住集合中元素的类型,并可以在编译时检查集合中元素的类型。即解决一些安全问题;同时还可以让代码变得更加简洁。
1.使用泛型
泛型的格式:通过<>来定义要操作的引用数据类型。
public class GenericDemo {
public static void main(String[] args)
{
//创建一个只能保存字符串的List 集合
List<String> strList = new ArrayList<String>() ;
strList.add("Generic") ;
//如果存放其他对象这回出现编译错误。
System.out.println(strList);
}
}
2.了解泛型
ArrayList<E> 类定义和ArrayList<Integer> 类引用中涉及的术语:
> 整个称为ArrayList<E> 泛型类型。
> ArrayList<E> 中的E称为类型变量或类型参数。
> 整个ArrayList<Integer> 称为参数化的类型。
> ArrayList<Integer> 中的Integer 称为类型参数的实例或实际类型参数。
> ArrayList<Integer> 中的<> 念着typeof
> ArrayList 称为原始类型
3.定义泛型类
除了Java提供了一些类增加了泛型支持外,我们可以定义泛型支持的类。那么在什么时候定义泛型类呢?
当类中操作的引用数据类型不确定时可以定义泛型类。
格式如下:
class Tools<T>{}
4.泛型方法
泛型类定义的泛型,在整个类中有效,如果被方法使用,那么泛型类的对象明确要操作的具体类型后,所有要操作的类型就已经固定了。为了让不同方法可以操作不同类型,而且类型还不确定,那么可以将泛型定义在方法上。
定义泛型方法格式如下:
public <T> void show(T t){} 注意:<>放在修饰符后面,返回值前面
总结
1. 如果涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
2. 如果程序在单线程环境中,或者访问仅仅在一个线程中进行,考虑非同步的类,其效率较高,如果多个线程可能同时操作一个类,应该使用同步的类。
3. 在除需要排序时使用TreeSet,TreeMap外,都应使用HashSet,HashMap,因为他们 的效率更高。
4. 要特别注意对哈希表的操作,作为key的对象要正确复写equals和hashCode方法。
5. 容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。一旦将对象置入容器内,便损失了该对象的型别信息。
6. 尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变。这就是针对抽象编程。
注意:
1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
2、Set和Collection拥有一模一样的接口。
3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)
4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。
5、Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
6、Map中元素,可以将key序列、value序列单独抽取出来。
使用keySet()抽取key序列,将map中的所有keys生成一个Set。
使用values()抽取value序列,将map中的所有values生成一个Collection。
为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。