标签:
|
参考教程
http://zhaolinjnu.blog.sohu.com/264905210.html
http://www.360doc.com/content/13/0217/13/11619026_266124504.shtml
http://f.dataguru.cn/thread-352611-1-1.html 4.Lucene分词器之庖丁解牛(屈) http://blog.csdn.net/ld_flex/article/details/7681943 5. 在项目中使用paoding分词(jar包路径问题和mapper类如何修改) http://blog.csdn.net/wauwa/article/details/7940509
http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html
http://blog.csdn.net/yeruby/article/details/21973629
http://blog.csdn.net/pc620/article/details/6280489
http://blog.csdn.net/lengyuhong/article/details/5993316
|
简单步骤可以参考小镜镜的博客,此处不再赘述。
http://www.cnblogs.com/Athrun29/articles/4358863.html
https://code.google.com/p/paoding/downloads/list
解压后找到以下四个jar包,第一个包解压即可看到,后面三个jar包在lib文件夹中里。
lucene-analyzers-2.2.0.jar
lucene-core-2.2.0.jar
paoding-analysis.jar
commons-logging.jar
使用二中方法三的代码,加以修改。首先在工程里新建一个lib文件夹(注意是文件夹,不是userlib,这样后面才能将四个jar一起打包),将四个jar包复制粘贴进去,在右键add to build path。
从解压的文件中找到dic文件夹,分别上传到三个主机的/home/hadoop/hadoop-2-5-2中,然后stop HDFS,再在hadoop-env.sh文件末尾配置庖丁字典的环境变量:
添加export PAODING_DIC_HOME=/home/hadoop/dic
添加完后重启HDFS
2. 关于编码问题,由于还未弄明白,暂时不写。主要涉及两方面的编码,一是eclipse的编码,另一是centOS的编码。
具体问题可见后面的第五个问题。
注:centOS里修改设置文件后,可以不重启,用source命令使之立即生效。
3. 修改mapper类,将庖丁的设置放在里面。
|
package twoWordCount;
import java.io.ByteArrayInputStream; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.Reader; import net.paoding.analysis.analyzer.PaodingAnalyzer;
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.Token; import org.apache.lucene.analysis.TokenStream;
public class myMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(LongWritable ikey, Text value, Context context) throws IOException, InterruptedException { /* *将字符串解析成Key-Value的形式 * ikey 偏移量 * value 内容 * context 上下文 */ byte[] bt = value.getBytes(); InputStream ip = new ByteArrayInputStream(bt); Reader read = new InputStreamReader(ip); Analyzer analyzer = new PaodingAnalyzer(); TokenStream tokeStream = analyzer.tokenStream(word.toString(), read); Token t; while ((t=tokeStream.next())!=null) { word.set(t.termText()); context.write(word, one); } }
} |
myDriver里可以将
Job job = Job.getInstance(conf, "EnglishWordCount");
中的EnglishWordCount修改为ChineseWordCount
4. 上传一个中文文件到HDFS系统中(此时文件的格式和最好的结果是否能够查看到中文可见后面的第五个问题中的表格)
再分别在eclipse上和hadoop上运行即可。运行方法同实验2-2.
遇到的问题
第一个问题:打包jar包时已经指定了主函数,而运行时无需在指定
此时main()函数相关代码为
|
Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } (中间省略) FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); //文件输入 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //文件输出 |
2. 使用陈娜的打包执行时,系统报错:
Usage: wordcount <in> <out>
此时main()函数相关代码为
|
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } (中间省略) FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); //文件输入 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //文件输出 |
3. 将上述代码改成
|
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } (中间省略) FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); //文件输入 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //文件输出 |
则系统又报1中错误:输出路径已经存在(区别是一个是自己写的,一个是陈娜的,其实是同样的情况。)
4. 将上述代码改成
|
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } (中间省略) FileInputFormat.setInputPaths(job, new Path(otherArgs[1])); //文件输入 FileOutputFormat.setOutputPath(job, new Path(otherArgs[2])); //文件输出 |
则报错:otherArgs[2]溢出??
5. 将1中代码改成
|
Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } (中间省略) for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length - 1])); |
则系统将命令中的主函数当成输入路径,报输入路径不存在的错误
思考可能的原因:
猜想:
原因可能是打包jar包时已经指定了主函数,而运行时又指定了一遍,系统就将命令中的主函数当成输入路径,输入路径当输出路径来处理了。
后:
猜想得到证实。
第二个问题:出现主类中什么找不到的问题
报错说主函数中的某语句里的maper类找不到,确认程序无误,用try catch包围了出错类的上一个语句,莫名其妙程序就能运行了。。。。。坑。
然后删掉try catch程序依然没问题。。。。。。。。。。。。。。。。。。。。。。。。。。神坑
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。究竟是什么原因,至今不明
估计可能是在打包时回头了一下怎么地,重新打包即可。
第三个问题:
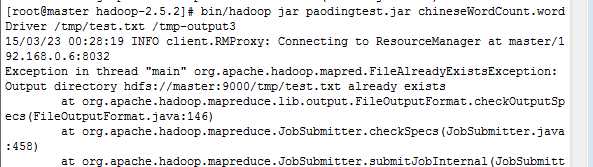
打包后在hadoop上可以运行,但在Eclipse中运行报错如下:

检查后得知庖丁的jar包的路径中不可以有空格,检查我的路径如下图:
路径中无空格。考虑是中文乱码问题,将四个包存放到无中文无空格的路径,并在build path中添加,则问题得到解决,但是这种方式打包的时候无法打包这四个jar,同理,如果将这四个文件放到配置的hadoop库中,在打包时也是打包不进去的(hadoop本身也不需要被打包),最后采取的解决办法是改变工作空间的路径,换成无中文无空格的路径。
思考:若是适当改变Eclipse的编码,使其在辨认jar包路径的时候能够识别中文,此方案是否可行?
第四个问题:庖丁dic目录找不到
将程序打包并上传到客户端执行,报错如下:
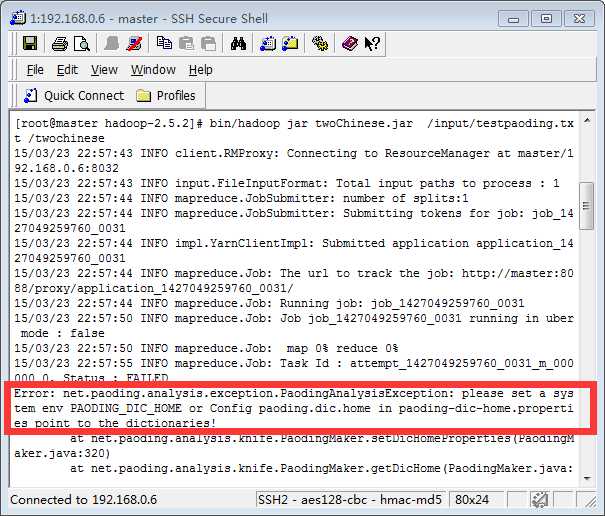
可能的原因是,要么属性文件进行了配置,没有寻找环境变量,要么是环境变量没有配置好。(复杂的原因详见下图中的文件,可在该文件中find报错的那句话,找到相应位置再分析)
第一次出现这个问题,是因为环境变量配在了虚拟机文件而不是hadoop系统。
应该在三台主机的hadoop-env.sh文件末尾添加(路径是自己上传到三台主机的路径)
export PAODING_DIC_HOME=/home/hadoop/Hadoop-2.5.2/dic
配置前最好先stop hadoop系统——配置——strat hadoop系统,这样安全。
(注意linux认大小写,千万不要把export写成Export)
问题解决
第二次出现这个问题,并且情况比较复杂,是有时候报这个错,有时候却能成功。
原因:
1.之前的配置被改掉了,而且不是所有的机子都被改了。只有两台slave的配置被删掉了,是哪个亲不小心干的啊!哼
2.没有报错是因为正好在master上运行吗?
第五个问题:eclipse编码方式,输入文件编码方式,centOs主机编码方式
问题描述:在hadoop上运行没报错,成功,但是结果文件为空。这个问题出现是在换了工作空间之后,未更改eclipse编码方式的时候,在eclipse上打包jar丢到hadoop上运行,且输入文件是无编码方式的时候。
回忆:在原工作空间的改变了eclipse编码方式为utf-8的时候,在hadoop上运行是有结果的,结果文件不为空。所以问题在于编码方式,输入文件的编码方式和eclipse本身的编码方式。
|
关于eclipse本身的编码方式对运行结果的影响,这个昨天总结的时候没有注意到。 |
|
centOs主机编码方式,已将#vi /etc/sysconfig/i18n,把LANG的值改成zh_CN.UTF-8,但是所有文件均为乱码。 |
|
改变eclipse编码方式为UTF-8后,Eclipse中原来的注释是乱码,现在新的注释不是乱码。 |
|
输入文件格式和输出文件格式与eclipse和hadoop centOs的关系 |
--------------------------------------上述问题之后还需要细细研究。
关于编码方式
输入文件在eclipse上查看
Eclipse编码方式为UTF-8 Eclipse编码方式未改
无编码方式 Test1 乱码 test2-2乱码 Test1 中文 test2-2中文
UTF-8 Test2中文 test1-1中文 Test2乱码 test1-1乱码
结论:在eclipse上查看的输入文件只有与eclipse当前编码方式相同才不会为乱码。
所有运行结果在未改变eclipse编码方式的eclipse中查看均为乱码。
|
以下运行结果均为在未改变编码方式的eclipse下运行或打包的,在改变了编码方式为UTF-8的eclipse下看。 me-hadoop UTF-8 test1-1 48b 中文 test2 342b 中文 无 test1 0b 无内容 test2-2 6b 乱码 me-eclipse UTF-8 test1-1 69b 乱码 test2 826b 乱码 无 test1 48b 中文 test2-2 342b 中文 nana-hadoop UTF-8 test1-1 48b 中文 test2 342b 中文 无 test1 0b 无内容 test2-2 6b 乱码
结论:以下在Eclipse上查看结果,Eclipse编码方式均为UTF-8 文件用记事本不调格式,在eclipse上运行结果是中文,在hadoop上运行结果为乱码,且结果大小几乎可以忽略; 文件用UTF-8无bom格式,在hadoop上运行结果是中文,在eclipse上运行结果是乱码,且结果大小均大于hadoop上运行结果 |
第六个问题:
其实就是上述两个问题搅在一起。有时候报错dic,成功,无结果。有时候无报错,完全成功。有时候报错dic,成功,结果文件夹为空。有时候不报错,成功,结果文件夹为空。
第七个问题:打包
目前Eclipse(原工作空间)中的project(这部分是写给自己看的):
|
其他程序 chineseWordCount 陈娜的程序直接导入,缺少hadoop的各种包,报错 paoding_analysis 庖丁的src文件直接导入,原来是用于更改其dic目录的设置文件,后无需更改而无用
英文词频统计 MR0 网上找的程序1 两个包,两个类可以运行,程序内没有指定输入输出 在Eclipse和客户端均可执行
WordCount2 网上找的程序2 一个包,三个类可以运行,程序内指定输入输出 在Eclipse和客户端均可执行
twoWordCount 自己写的第一个英文词频统计 一个包,三个类可以运行,程序内没有指定输入输出 在Eclipse和客户端均可执行
中文词频统计 paodingTest 自己写的第一个中文词频统计。 一个包,三个类可以运行,程序内指定输入输出
paodingTest2 我操作的使用陈娜的代码
wordcount 刘雯操作的使用陈娜的代码
twoWordCount2 自己写的第二个中文词频统计,在自己写的第一个英文词频统计的基础上得来 |
标签:
原文地址:http://www.cnblogs.com/qianqianjun/p/4579362.html