标签:
文件系统的核心问题是存储。这里面隐含2个问题:1)存储什么?2)存储到哪里?文件系统中的各种技术手段都是如何高效的解决这2个问题。ubifs用node标准化每一个存储对象,用lprops描述每一个逻辑块空间,用TNC组织管理所有的node对象,用LPT组织管理所有的lprops对象。
node
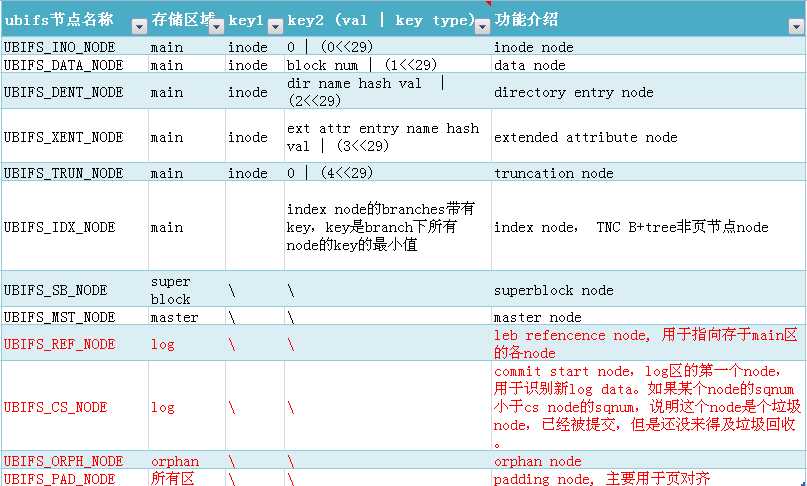
ubifs中除了存储用户数据,还要存储索引节点、目录项、超级块等数据。这些数据结构各异,差异很大,为了统一数据视图,便于管理,ubifs标准化了所有数据的表现形式,所有数据以node表示呈现。并根据不同用途对node进行分类、存储和组织。ubifs的node汇总介绍如下。
黑色部分为通用的文件系统数据,红色部分为ubifs专有的文件系统数据。
TNC
因为 UBIFS_INO_NODE,UBIFS_DATA_NODE,UBIFS_DENT_NODE,UBIFS_XENT_NODE,UBIFS_TRUN_NODE节点数量巨大,ubifs采用 B+树用于管理这些节点。各节点在树中的index为(inode, key2),如上图所示,不同的node有不同的key2。其目的就是能根据index快速找到叶节点数据所在的位置,但是B+树的index节点数量多,更新很慢,如果这个过程中被打断,叶节点文件就丢失了。所以在commit tnc前,先把叶节点文件的数据信息commit到log区,这样既提高了速度,也保证在tnc commit失败的情况下,叶节点文件也能通过log区找到,并replay到tnc。
journal replay
从数据的角度看,recovery的过程就是将(leb, offs) list进过加工处理,映射成{key: [leb, offs, len]} B+tree的过程。
日志回放的详细过程如下:
从log区中获取ref node((leb, offs) ),从ref node获取bud所在位置信息(leb:offs),构造内存对象bud,并根据此信息 scan这一段leb,筛选出无效的node,将有效的node加入sleb->nodes,以备后面replay,如果是最后一个bud并需要recovery,将leb:0-offs这段异地备份到另一个peb上。
把sleb->nodes上的node处理成replay_entry,并加入到c->replay_list,然后根据replay_list,构造成ubifs_zbranch({key: [leb, offs, len]})对象更新到TNC B+树上,然后将已replay的buds leb块的free和dirty空间、dirty标记等lprop属性信息
sync
如果在unclean reboot前,没有调用sync,buf中的数据由于没有同步到flash,将可能破坏ubifs文件系统。
sync会调用ubifs_run_commit进行所有的数据提交。
如果调用sync过程中断电,
如果在wbuf commit前或者过程中断电,文件将丢失,这需要应用层主动调用sync来保证。但wbuf commit很快,这是小概率事件;
如果在log commit前断电,文件将丢失,这需要应用层主动调用sync来保证。
如果在log commit过程中断电,文件还是会丢失。但log commit很快,这是小概率事件;
其他情况下,比如gc commit前、或者tnc commit前或者过程中断电,文件不会丢失,因为可以从log区replay。
lprops
ubifs用node对象解决存储对象的问题,用lprops对象解决存储位置问题。要决定新的对象存储到哪里,就需要获取整个存储空间的使用视图数据以辅助决策。
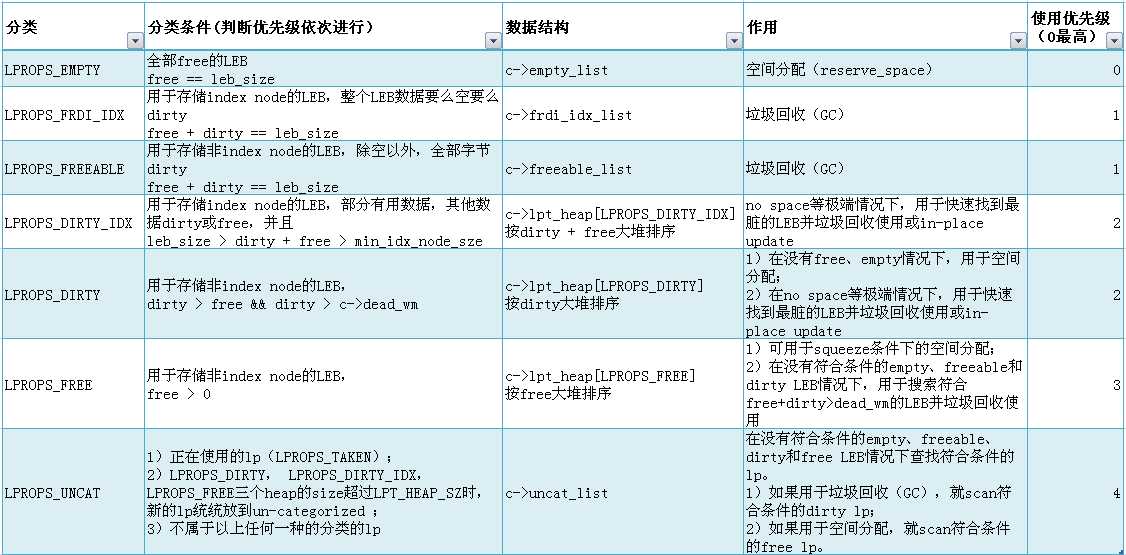
lprops对象用(lnum,free,dirty)元组信息完成对一个逻辑块的使用视图的描述。通过把所有的lprops对象组织成LPT B+tree,可以快速查询更新某个lnum逻辑块的使用视图信息。因为LPT的key是lnum,所有无法快速查询到most free或most dirty的逻辑块,在这种需求基础上,ubifs对lprops进行分类组织,满足对free lnum(空间分配)或dirtry lnum(垃圾回收)的快速查询需求。
LPT
lpt B+tree用于管理ubifs逻辑块属性对象 lprops,B+tree的index为lnum。其目的就是根据lnum,快速查询、更新逻辑块的信息(主要是free、dirty等信息)。
--EOF--
ubifs核心对象 -- TNC和LPT
标签:
原文地址:http://www.cnblogs.com/wahaha02/p/4583873.html
.png)