标签:
在《Kafka实战-实时日志统计流程》一文中,谈到了Storm的相关问题,在完成实时日志统计时,我们需要用到Storm去消费Kafka Cluster中的数据,所以,这里我单独给大家分享一篇Storm Cluster的搭建部署。以下是今天的分享目录:
下面开始今天的内容分享。
Twitter将Storm开源了,这是一个分布式的、容错的实时计算系统,已被贡献到Apache基金会,下载地址如下所示:
http://storm.apache.org/downloads.html
[hadoop@dn1 ~]$ tar -zxvf apache-storm-0.9.4.tar.gz
export STORM_HOME=/home/hadoop/storm-0.9.4 export PATH=$PATH:$STORM_HOME/bin
########### These MUST be filled in for a storm configuration storm.zookeeper.servers: - "dn1" - "dn2" - "dn3" storm.zookeeper.port: 2181 nimbus.host: "dn1" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 storm.local.dir: "/home/hadoop/data/storm"
下面我们来看Storm的角色分配,如下图所示: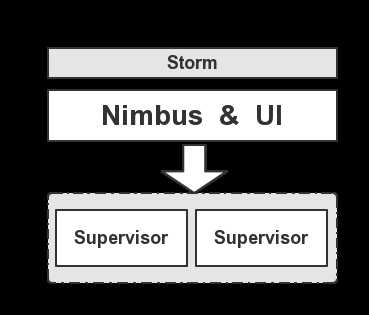
在配置完成相关文件后,我们使用scp命令将文件分发到各个节点,命令如下所示:
[hadoop@dn1 ~]$ scp -r storm-0.9.4/ hadoop@dn2:~/ [hadoop@dn1 ~]$ scp -r storm-0.9.4/ hadoop@dn3:~/
# 分别在三个节点依次启动zk的服务 [hadoop@dn1 ~]$ zkServer.sh start [hadoop@dn2 ~]$ zkServer.sh start [hadoop@dn3 ~]$ zkServer.sh start
# 在nimbus节点启动nimbus服务
[hadoop@dn1 ~]$ storm nimbus &
#在supervisor节点分别启动supervisor服务 [hadoop@dn2 ~]$ storm supervisor & [hadoop@dn3 ~]$ storm supervisor &
[hadoop@dn1 ~]$ storm ui &
[hadoop@dn1 storm-0.9.4]$ jps 2098 Jps 1983 core 1893 QuorumPeerMain 1930 nimbus
[hadoop@dn2 storm-0.9.4]$ jps 1763 worker 1762 worker 1662 QuorumPeerMain 1765 worker 1692 supervisor 1891 Jps
[hadoop@dn3 storm-0.9.4]$ jps 2016 QuorumPeerMain 2057 supervisor 2213 Jps
由于,集群我做过测试,提交过Topology,所以截图中会有提交记录,从上面的dn2节点的进程中也可以看出,有相应的worker进程,若是首次安装,未提交任务是不会有对应的显示的,下面附上Storm UI中相关的截图预览,如下图所示:
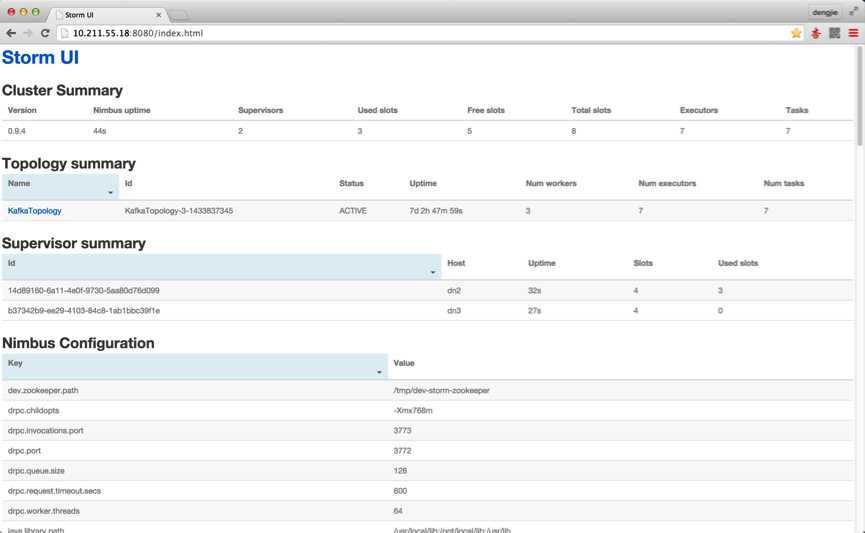
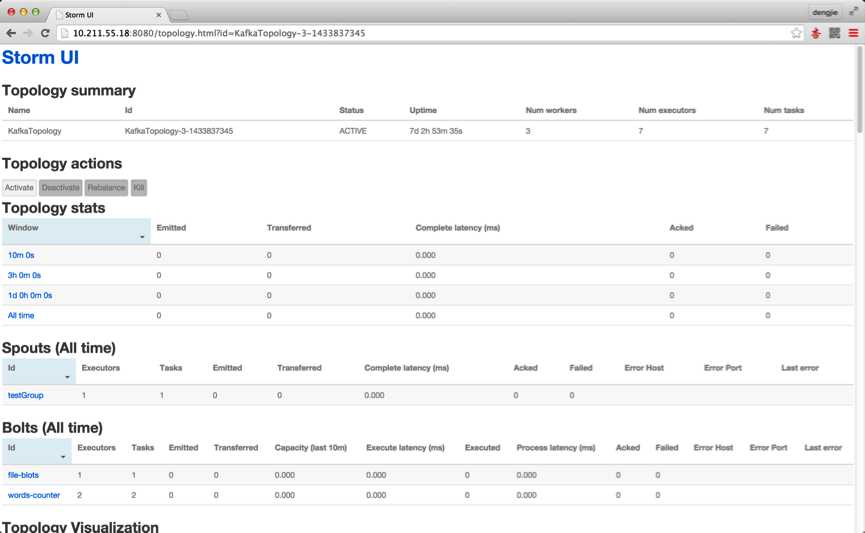
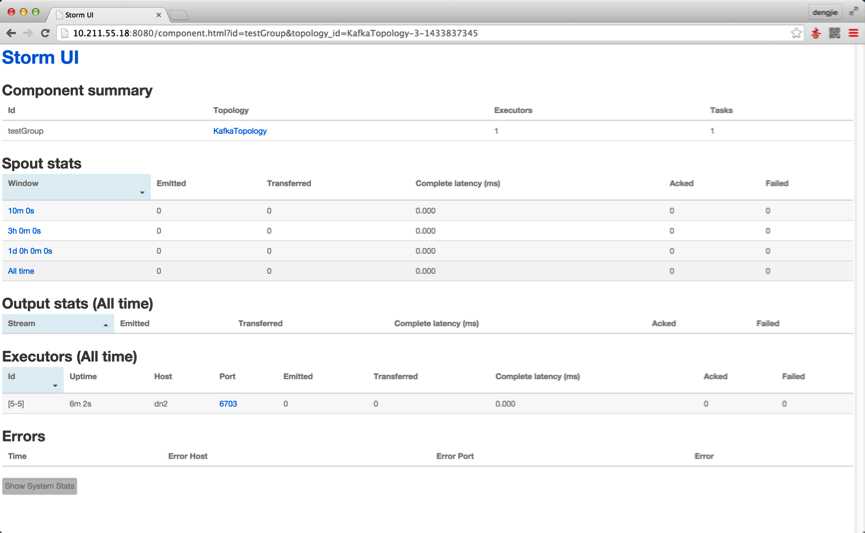
这就是本篇为大家介绍的Storm Cluster的搭建部署,从上面的Storm的分布图中我们可以细心的发现,Storm的分布存在单点问题,国外已经有Storm HA版本,不过这个非官方版本,目前Storm提供了一些机制来保证即使在节点挂了或者消息被丢失的情况下也能正确的进行数据处理,可以参考官方给出的解决方案,地址如下所示:
http://storm.apache.org/documentation/Guaranteeing-message-processing.html
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
标签:
原文地址:http://www.cnblogs.com/smartloli/p/4585268.html