标签:
参考资料:
http://ir.dlut.edu.cn/NewsShow.aspx?ID=291
http://www.douban.com/note/298095260/
word2vec是NLP领域的重要算法,它的功能是将word用K维的dense vector来表达,训练集是语料库,不含标点,以空格断句。因此可以看作是种特征处理方法。
主要优点:
google的开源版本比较权威,地址( http://word2vec.googlecode.com/svn/trunk/ ),不过我以spark版本学习的。
I.背景知识
Distributed representation,word的特征表达方式,通过训练将每个词映射成 K 维实数向量(K 一般为模型中的超参数),通过词之间的距离(比如 cosine 相似度、欧氏距离等)来判断它们之间的语义相似度。
语言模型:n-gram等。
II.模型
0.word window构成context,对于一个单词i,以$u_i$表示,它作为别的单词的context时用$v_i$表示(也即它作为context的表示是不同的)。只有word window内的word才被认为是context,并且是顺序无关的。
1.概率模型为\[ P=\sum lot p(u_i) \],i表示位置(或单词),也即各单词出现概率的累积函数。
2.以skip gram为例(CBOW条件概率反过来),则位置i的单词出现概率为
\[ p(u_i)=\sum_{-c\leq j\leq c,j\neq 0} p(v_{i+j}|u_{i}) \]
表示位置i只和其context有关。
3.条件概率$p(v_{i+j}|u_i)$ 通过softmax实现K维向量到概率的转化表达。
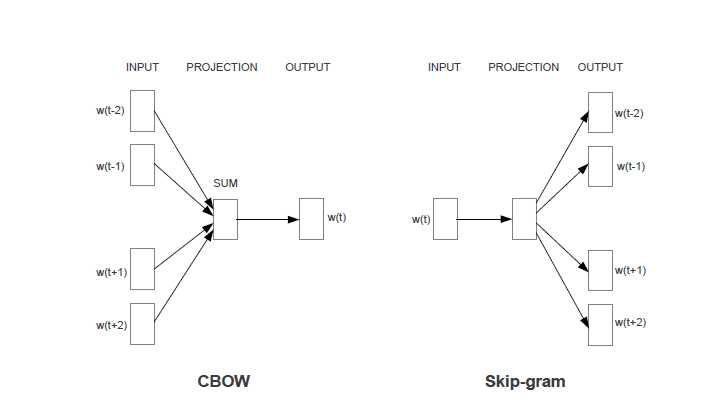
III.优化
最开始使用神经网络,后来用层次softmax来降低时间复杂度。还用了很多trick,比如ExpTable。
IV.spark源码分析
1 /** 2 * Licensed to the Apache Software Foundation (ASF) under one or more 3 * contributor license agreements. See the NOTICE file distributed with 4 * this work for additional information regarding copyright ownership. 5 * The ASF licenses this file to You under the Apache License, Version 2.0 6 * (the "License"); you may not use this file except in compliance with 7 * the License. You may obtain a copy of the License at 8 * 9 * http://www.apache.org/licenses/LICENSE-2.0 10 * 11 * Unless required by applicable law or agreed to in writing, software 12 * distributed under the License is distributed on an "AS IS" BASIS, 13 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 14 * See the License for the specific language governing permissions and 15 * limitations under the License. 16 */ 17 18 package org.apache.spark.mllib.feature 19 20 import java.lang.{Iterable => JavaIterable} 21 22 import com.github.fommil.netlib.BLAS.{getInstance => blas} 23 import org.apache.spark.Logging 24 import org.apache.spark.SparkContext._ 25 import org.apache.spark.annotation.Experimental 26 import org.apache.spark.api.java.JavaRDD 27 import org.apache.spark.mllib.linalg.{Vector, Vectors} 28 import org.apache.spark.rdd.RDD 29 import org.apache.spark.util.Utils 30 import org.apache.spark.util.random.XORShiftRandom 31 import scala.collection.JavaConverters._ 32 import scala.collection.mutable 33 import scala.collection.mutable.ArrayBuffer 34 35 36 /** 37 * Entry in vocabulary 38 */ 39 private case class VocabWord( 40 var word: String, 41 var cn: Int, 42 var point: Array[Int], 43 var code: Array[Int], 44 var codeLen:Int 45 ) 46 47 /** 48 * :: Experimental :: 49 * Word2Vec creates vector representation of words in a text corpus. 50 * The algorithm first constructs a vocabulary from the corpus 51 * and then learns vector representation of words in the vocabulary. 52 * The vector representation can be used as features in 53 * natural language processing and machine learning algorithms. 54 * 55 * We used skip-gram model in our implementation and hierarchical softmax 56 * method to train the model. The variable names in the implementation 57 * matches the original C implementation. 58 * 59 * For original C implementation, see https://code.google.com/p/word2vec/ 60 * For research papers, see 61 * Efficient Estimation of Word Representations in Vector Space 62 * and 63 * Distributed Representations of Words and Phrases and their Compositionality. 64 */ 65 @Experimental 66 class Word2VectorEX extends Serializable with Logging { 67 68 private var vectorSize = 100 69 private var startingAlpha = 0.025 70 private var numPartitions = 1 71 private var numIterations = 1 72 private var seed = Utils.random.nextLong() 73 74 /** 75 * Sets vector size (default: 100). 76 */ 77 def setVectorSize(vectorSize: Int): this.type = { 78 this.vectorSize = vectorSize 79 this 80 } 81 82 /** 83 * Sets initial learning rate (default: 0.025). 84 */ 85 def setLearningRate(learningRate: Double): this.type = { 86 this.startingAlpha = learningRate 87 this 88 } 89 90 /** 91 * Sets number of partitions (default: 1). Use a small number for accuracy. 92 */ 93 def setNumPartitions(numPartitions: Int): this.type = { 94 require(numPartitions > 0, s"numPartitions must be greater than 0 but got $numPartitions") 95 this.numPartitions = numPartitions 96 this 97 } 98 99 /** 100 * Sets number of iterations (default: 1), which should be smaller than or equal to number of 101 * partitions. 102 */ 103 def setNumIterations(numIterations: Int): this.type = { 104 this.numIterations = numIterations 105 this 106 } 107 108 /** 109 * Sets random seed (default: a random long integer). 110 */ 111 def setSeed(seed: Long): this.type = { 112 this.seed = seed 113 this 114 } 115 116 private val EXP_TABLE_SIZE = 1000 117 private val MAX_EXP = 6 118 private val MAX_CODE_LENGTH = 40 119 private val MAX_SENTENCE_LENGTH = 1000 120 121 /** context words from [-window, window] */ 122 private val window = 5 //context 范围限定 123 124 /** minimum frequency to consider a vocabulary word */ 125 private val minCount = 5 //过滤单词阈值 126 127 private var trainWordsCount = 0 //语料库总共词量(计重复出现) 128 private var vocabSize = 0 //词表内单词总数 129 private var vocab: Array[VocabWord] = null //词表 130 private var vocabHash = mutable.HashMap.empty[String, Int] //词表反查索引 131 132 private def learnVocab(words: RDD[String]): Unit = { //构造词表,统计更新上面四个量 133 vocab = words.map(w => (w, 1)) 134 .reduceByKey(_ + _) 135 .map(x => VocabWord( 136 x._1, 137 x._2, 138 new Array[Int](MAX_CODE_LENGTH), 139 new Array[Int](MAX_CODE_LENGTH), 140 0)) 141 .filter(_.cn >= minCount) 142 .collect() 143 .sortWith((a, b) => a.cn > b.cn) 144 145 vocabSize = vocab.length 146 var a = 0 147 while (a < vocabSize) { 148 vocabHash += vocab(a).word -> a 149 trainWordsCount += vocab(a).cn 150 a += 1 151 } 152 logInfo("trainWordsCount = " + trainWordsCount) 153 } 154 155 private def createExpTable(): Array[Float] = { //指数运算查表 156 val expTable = new Array[Float](EXP_TABLE_SIZE) 157 var i = 0 158 while (i < EXP_TABLE_SIZE) { 159 val tmp = math.exp((2.0 * i / EXP_TABLE_SIZE - 1.0) * MAX_EXP) 160 expTable(i) = (tmp / (tmp + 1.0)).toFloat 161 i += 1 162 } 163 expTable 164 } 165 166 private def createBinaryTree(): Unit = { 167 val count = new Array[Long](vocabSize * 2 + 1) 168 val binary = new Array[Int](vocabSize * 2 + 1) 169 val parentNode = new Array[Int](vocabSize * 2 + 1) 170 val code = new Array[Int](MAX_CODE_LENGTH) 171 val point = new Array[Int](MAX_CODE_LENGTH) 172 var a = 0 173 while (a < vocabSize) { 174 count(a) = vocab(a).cn 175 a += 1 176 } 177 while (a < 2 * vocabSize) { 178 count(a) = 1e9.toInt 179 a += 1 180 } 181 var pos1 = vocabSize - 1 182 var pos2 = vocabSize 183 184 var min1i = 0 185 var min2i = 0 186 187 a = 0 188 while (a < vocabSize - 1) { 189 if (pos1 >= 0) { 190 if (count(pos1) < count(pos2)) { 191 min1i = pos1 192 pos1 -= 1 193 } else { 194 min1i = pos2 195 pos2 += 1 196 } 197 } else { 198 min1i = pos2 199 pos2 += 1 200 } 201 if (pos1 >= 0) { 202 if (count(pos1) < count(pos2)) { 203 min2i = pos1 204 pos1 -= 1 205 } else { 206 min2i = pos2 207 pos2 += 1 208 } 209 } else { 210 min2i = pos2 211 pos2 += 1 212 } 213 count(vocabSize + a) = count(min1i) + count(min2i) 214 parentNode(min1i) = vocabSize + a 215 parentNode(min2i) = vocabSize + a 216 binary(min2i) = 1 217 a += 1 218 } 219 // Now assign binary code to each vocabulary word 220 var i = 0 221 a = 0 222 while (a < vocabSize) { 223 var b = a 224 i = 0 225 while (b != vocabSize * 2 - 2) { 226 code(i) = binary(b) 227 point(i) = b 228 i += 1 229 b = parentNode(b) 230 } 231 vocab(a).codeLen = i 232 vocab(a).point(0) = vocabSize - 2 233 b = 0 234 while (b < i) { 235 vocab(a).code(i - b - 1) = code(b) 236 vocab(a).point(i - b) = point(b) - vocabSize 237 b += 1 238 } 239 a += 1 240 } 241 } 242 243 /** 244 * Computes the vector representation of each word in vocabulary. 245 * @param dataset an RDD of words 246 * @return a Word2VecModel 247 */ 248 def fit[S <: Iterable[String]](dataset: RDD[S]): Word2VectorModel = { 249 250 val words = dataset.flatMap(x => x) //拉成词序列,句话断点通过Iterable来表征 251 252 learnVocab(words) //学习词库 253 254 createBinaryTree() 255 256 val sc = dataset.context 257 258 val expTable = sc.broadcast(createExpTable()) 259 val bcVocab = sc.broadcast(vocab) 260 val bcVocabHash = sc.broadcast(vocabHash) 261 262 val sentences: RDD[Array[Int]] = words.mapPartitions { iter => //按句子划分,单词以Int表征 263 new Iterator[Array[Int]] { 264 def hasNext: Boolean = iter.hasNext 265 266 def next(): Array[Int] = { 267 var sentence = new ArrayBuffer[Int] 268 var sentenceLength = 0 269 while (iter.hasNext && sentenceLength < MAX_SENTENCE_LENGTH) { 270 val word = bcVocabHash.value.get(iter.next()) 271 word match { 272 case Some(w) => 273 sentence += w 274 sentenceLength += 1 275 case None => 276 } 277 } 278 sentence.toArray 279 } 280 } 281 } 282 283 //Hierarchical Softmax 284 val newSentences = sentences.repartition(numPartitions).cache() 285 val initRandom = new XORShiftRandom(seed) 286 val syn0Global = 287 Array.fill[Float](vocabSize * vectorSize)((initRandom.nextFloat() - 0.5f) / vectorSize) 288 val syn1Global = new Array[Float](vocabSize * vectorSize) 289 var alpha = startingAlpha 290 for (k <- 1 to numIterations) { 291 val partial = newSentences.mapPartitionsWithIndex { case (idx, iter) => 292 val random = new XORShiftRandom(seed ^ ((idx + 1) << 16) ^ ((-k - 1) << 8)) //随机梯度下降 293 val syn0Modify = new Array[Int](vocabSize) 294 val syn1Modify = new Array[Int](vocabSize) 295 val model = iter.foldLeft((syn0Global, syn1Global, 0, 0)) { 296 case ((syn0, syn1, lastWordCount, wordCount), sentence) => 297 var lwc = lastWordCount 298 var wc = wordCount 299 if (wordCount - lastWordCount > 10000) { 300 lwc = wordCount 301 // TODO: discount by iteration? 302 alpha = 303 startingAlpha * (1 - numPartitions * wordCount.toDouble / (trainWordsCount + 1)) 304 if (alpha < startingAlpha * 0.0001) alpha = startingAlpha * 0.0001 305 logInfo("wordCount = " + wordCount + ", alpha = " + alpha) 306 } 307 wc += sentence.size 308 var pos = 0 309 while (pos < sentence.size) { 310 val word = sentence(pos) 311 val b = random.nextInt(window) 312 // Train Skip-gram 313 var a = b 314 while (a < window * 2 + 1 - b) { 315 if (a != window) { 316 val c = pos - window + a 317 if (c >= 0 && c < sentence.size) { 318 val lastWord = sentence(c) 319 val l1 = lastWord * vectorSize 320 val neu1e = new Array[Float](vectorSize) 321 // Hierarchical softmax 322 var d = 0 323 while (d < bcVocab.value(word).codeLen) { 324 val inner = bcVocab.value(word).point(d) 325 val l2 = inner * vectorSize 326 // Propagate hidden -> output 327 var f = blas.sdot(vectorSize, syn0, l1, 1, syn1, l2, 1) 328 if (f > -MAX_EXP && f < MAX_EXP) { 329 val ind = ((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2.0)).toInt 330 f = expTable.value(ind) 331 val g = ((1 - bcVocab.value(word).code(d) - f) * alpha).toFloat 332 blas.saxpy(vectorSize, g, syn1, l2, 1, neu1e, 0, 1) 333 blas.saxpy(vectorSize, g, syn0, l1, 1, syn1, l2, 1) 334 syn1Modify(inner) += 1 335 } 336 d += 1 337 } 338 blas.saxpy(vectorSize, 1.0f, neu1e, 0, 1, syn0, l1, 1) 339 syn0Modify(lastWord) += 1 340 } 341 } 342 a += 1 343 } 344 pos += 1 345 } 346 (syn0, syn1, lwc, wc) 347 } 348 val syn0Local = model._1 349 val syn1Local = model._2 350 // Only output modified vectors. 351 Iterator.tabulate(vocabSize) { index => 352 if (syn0Modify(index) > 0) { 353 Some((index, syn0Local.slice(index * vectorSize, (index + 1) * vectorSize))) 354 } else { 355 None 356 } 357 }.flatten ++ Iterator.tabulate(vocabSize) { index => 358 if (syn1Modify(index) > 0) { 359 Some((index + vocabSize, syn1Local.slice(index * vectorSize, (index + 1) * vectorSize))) 360 } else { 361 None 362 } 363 }.flatten 364 } 365 val synAgg = partial.reduceByKey { case (v1, v2) => 366 blas.saxpy(vectorSize, 1.0f, v2, 1, v1, 1) 367 v1 368 }.collect() 369 var i = 0 370 while (i < synAgg.length) { 371 val index = synAgg(i)._1 372 if (index < vocabSize) { 373 Array.copy(synAgg(i)._2, 0, syn0Global, index * vectorSize, vectorSize) 374 } else { 375 Array.copy(synAgg(i)._2, 0, syn1Global, (index - vocabSize) * vectorSize, vectorSize) 376 } 377 i += 1 378 } 379 } 380 newSentences.unpersist() 381 382 val word2VecMap = mutable.HashMap.empty[String, Array[Float]] 383 var i = 0 384 while (i < vocabSize) { 385 val word = bcVocab.value(i).word 386 val vector = new Array[Float](vectorSize) 387 Array.copy(syn0Global, i * vectorSize, vector, 0, vectorSize) 388 word2VecMap += word -> vector 389 i += 1 390 } 391 392 new Word2VectorModel(word2VecMap.toMap) 393 } 394 395 /** 396 * Computes the vector representation of each word in vocabulary (Java version). 397 * @param dataset a JavaRDD of words 398 * @return a Word2VecModel 399 */ 400 def fit[S <: JavaIterable[String]](dataset: JavaRDD[S]): Word2VectorModel = { 401 fit(dataset.rdd.map(_.asScala)) 402 } 403 404 } 405 406 /** 407 * :: Experimental :: 408 * Word2Vec model 409 */ 410 @Experimental 411 class Word2VectorModel private[mllib] ( 412 private val model: Map[String, Array[Float]]) extends Serializable { 413 414 private def cosineSimilarity(v1: Array[Float], v2: Array[Float]): Double = { 415 require(v1.length == v2.length, "Vectors should have the same length") 416 val n = v1.length 417 val norm1 = blas.snrm2(n, v1, 1) 418 val norm2 = blas.snrm2(n, v2, 1) 419 if (norm1 == 0 || norm2 == 0) return 0.0 420 blas.sdot(n, v1, 1, v2,1) / norm1 / norm2 421 } 422 423 /** 424 * Transforms a word to its vector representation 425 * @param word a word 426 * @return vector representation of word 427 */ 428 def transform(word: String): Vector = { 429 model.get(word) match { 430 case Some(vec) => 431 Vectors.dense(vec.map(_.toDouble)) 432 case None => 433 throw new IllegalStateException(s"$word not in vocabulary") 434 } 435 } 436 437 /** 438 * Find synonyms of a word 439 * @param word a word 440 * @param num number of synonyms to find 441 * @return array of (word, similarity) 442 */ 443 def findSynonyms(word: String, num: Int): Array[(String, Double)] = { 444 val vector = transform(word) 445 findSynonyms(vector,num) 446 } 447 448 /** 449 * Find synonyms of the vector representation of a word 450 * @param vector vector representation of a word 451 * @param num number of synonyms to find 452 * @return array of (word, cosineSimilarity) 453 */ 454 def findSynonyms(vector: Vector, num: Int): Array[(String, Double)] = { 455 require(num > 0, "Number of similar words should > 0") 456 // TODO: optimize top-k 457 val fVector = vector.toArray.map(_.toFloat) 458 model.mapValues(vec => cosineSimilarity(fVector, vec)) 459 .toSeq 460 .sortBy(- _._2) 461 .take(num + 1) 462 .tail 463 .toArray 464 } 465 466 467 def getModel(): Map[String, Array[Float]] = { 468 model 469 } 470 471 472 }
标签:
原文地址:http://www.cnblogs.com/aezero/p/4586605.html