标签:
作为一名从事Linux运维行业多年的运维人员,分享一下曾经在运维过程中遇到过的荆手的故障分析,供大家分享,如果你在使用云计算中有什么问题,可以根据以下方式来查找 是
否有日志可以查看?. (比如Logstack系统笔记的云日志服务
)最后两个是最方便的信息来源,特别是日志系统,作为运维人员要善于和擅长查看日志,日志往往是你在没有头绪的时候给你最大的帮助,其实很多问题都在日志
系统中暴露出来,比较方便的是使用系统笔记 ,是的,云日志系统往往是你没有头绪最好的帮手,可以访问www.logstack.cn获得免费服务
是
否有日志可以查看?. (比如Logstack系统笔记的云日志服务
)最后两个是最方便的信息来源,特别是日志系统,作为运维人员要善于和擅长查看日志,日志往往是你在没有头绪的时候给你最大的帮助,其实很多问题都在日志
系统中暴露出来,比较方便的是使用系统笔记 ,是的,云日志系统往往是你没有头绪最好的帮手,可以访问www.logstack.cn获得免费服务 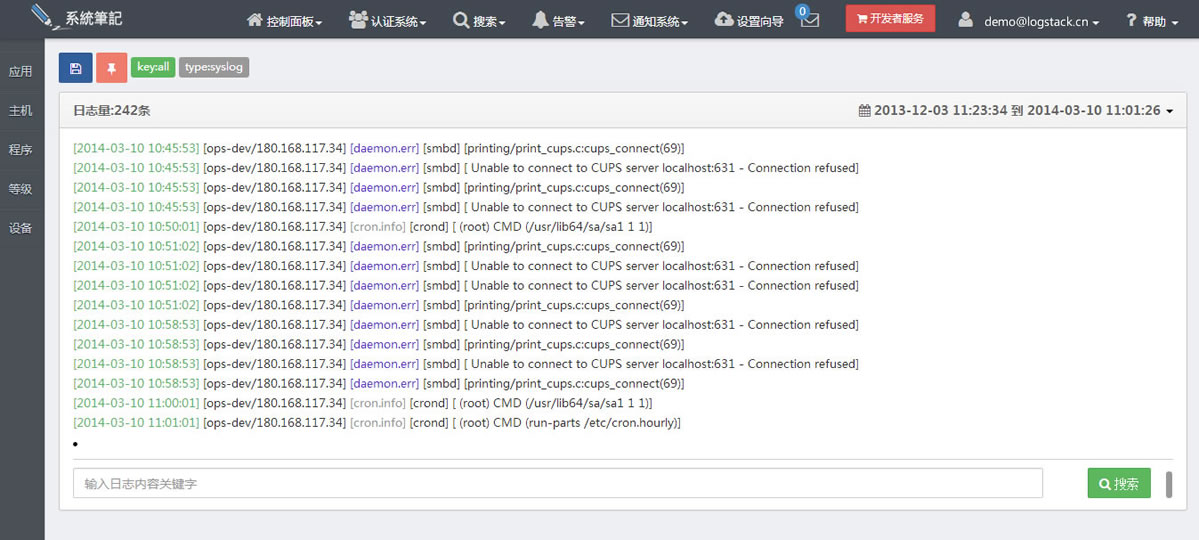

标签:
原文地址:http://my.oschina.net/maczhao/blog/468628