标签:
接着上一讲留下的关子,机器学习是否可行与假设集合H的数量M的关系。
机器学习是否可行的两个关键点:
1. Ein(g)是否足够小(在训练集上的表现是否出色)
2. Eout(g)是否与Ein(g)足够接近(在训练集上的表现能否迁移到测试集上)

(1)如果假设集合数量小(M小),可知union bound后,Ein与Eout是接近的;但由于可选择的假设集合少,Ein(g)效果可能不佳;
(2)如果假设集合数量大(M大),有可能Ein(g)会获得更多的选择,测试集上效果更好;但由于M数量过大,训练集和测试集的表现差距可能比较大;
因此,这里存在一个trade-off,如何选择合适的M非常重要。因此有了如下的目标:

如何把union bound产生的M用mH来代替,把无限变成有限,找到合适的trade-off的M取值。
要想把M用mH来代替,回顾一下M是如何来的。

union bound是把假设集合中的所有假设出现BAD event的概率直接加起来,P(A+B)≤P(A)+P(B) 这种形式得来的。
这里就有一个缺陷,如果这些BAD event有重叠的部分,那么union bound就大大地不准确了,就是这个bound太大了。如下图所示:

上面的抽象描述还不够直观,下面举了一个具体的例子。
H = {all lines in R²} 假设集合是二维平面上所有的直线。显然直线有无数条,因此这里的M是正无穷大。
接下来换了一个视角,不看线而是来看平面上的一个点。
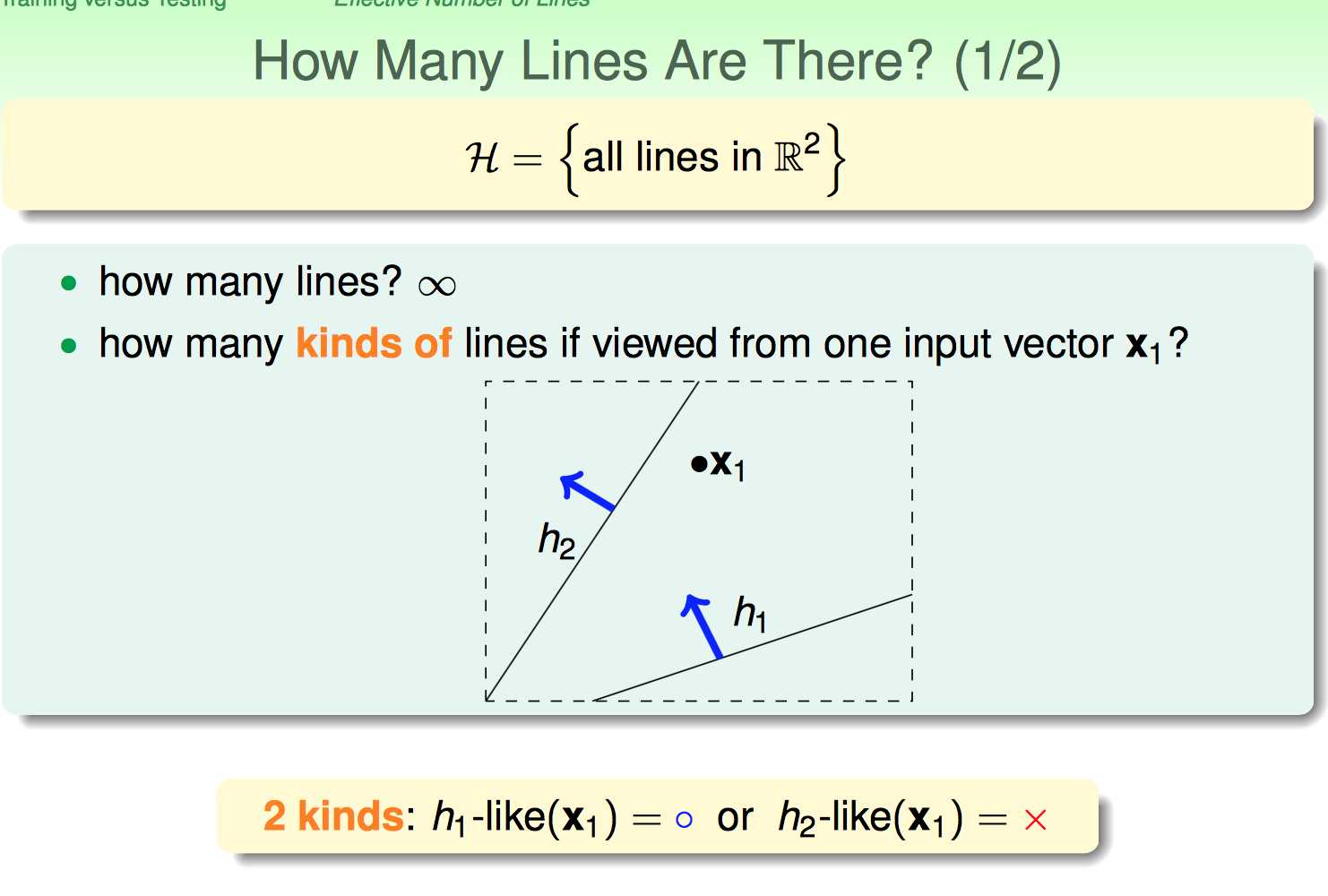
如果问题是binary classification,那么以某个点的视角来看,一条线要么把其划分为+1要么划分为-1。
这样一来,无限多个假设集合在x1这个点看来,就变成两类了。
以此类推,可以得到binary classification的Effective Number of Lines:

对于binary classification来说,就找到了替代M的方式,即无限缩减为有限了。
下面给这种假设集合的分类起一个正规的名字Dichotomies: Mini-hypotheses

这里就可以用某个假设集合在N个样本点下的dichotomies的数量来代替M。
但是这里有一个限制,就是dichotomies的在H,N的取值,是取决于具体取了哪N个样本点的。
现在只想与N有关,不想与哪N个样本点有关;因此再次定义了一个Growth Function:

Growth Function的核心意思是说:在所有可能的N个点当众,Growth Function取的那N个点是可以让dichotomies最大的N个点(如果是binary classification)。
这样,相当于与具体哪N个点无关了,只要保证这个N个点能产生的Growth Function值最大,记为mH(N):
m 表示取代M
H 表示是假设集合的一个函数
N 表示与样本点的数量有关(但是与哪N个点解耦了)
接下来,分析了几个Growth Functions的例子,

有的是polynomial的;有的是exponential的,如果是多项式的就不错了,如果是幂指数的那还是随着N的增大太大了。
以binary classification来说,2的N次幂确实是upper bound;
但是我们可以清晰地看到,在2D perceoptrons中,如果N大于等于4,显然mH(4)无法达到16(见上上个图)。
给这里的‘N=4’起一个名字——Break Point of H。
如果对于假设集合H,我们能找到某个Break Point(其值记为k),是否可以猜测,mH(N)可以被N的k-1次幂bound住呢?(即,mH(N)是N的多项式形式,多项式最大的幂是k-1)
【Training versus Testing】林轩田机器学习基石
标签:
原文地址:http://www.cnblogs.com/xbf9xbf/p/4589229.html