标签:
聚类算法,无监督学习的范畴,没有明确的类别信息。
给定n个训练样本{x1,x2,x3,...,xn}
kmeans算法过程描述如下所示:
1.创建k个点作为起始质心点,c1,c2,...,ck
i
2.重复以下过程直到收敛
遍历所有样本x
j
遍历所有质心c
记录质心与样本间的距离
将样本分配到距离其最近的质心
对每一个类,计算所有样本的均值并将其作为新的质心
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。
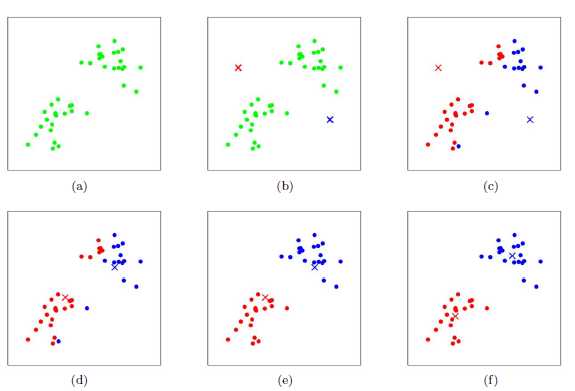
需要注意的几点:
k个点怎么取
1.选择距离尽可能远的k个点
首先随机选一个点p1作为第一个簇的质心,然后选距离这个点p1最远的点p2作为第二个簇的质心,
再选择距离前面p1和p2最短距离的最大值的点作为第三个簇的质心。max(min(d(p1),d(p2)))
以此类推,选k个点。
2.选用层次聚类或者Canopy算法先进行初始聚类,利用这些类簇的中心点作为Kmeans初始类簇的质心
要求:样本相对较小,例如数百到数千(层次聚类开销较大);K相对于样本大小较小
k值怎么确定
ps:每个类称为簇,则簇的直径:簇内任意两点间的最大距离,簇的半径:簇内点到簇质心的最大距离
给定一个合适的簇指标,可以是簇平均半径、簇平均直径、或者平均质心距离的加权平均值(权重可以为簇内点的个数)
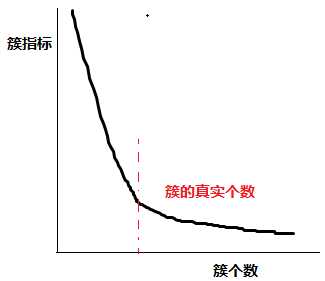
分别取k值在1,2,4,8,16....
基本会符合下图,当簇个数低于真实个数时,簇指标会随簇个数的增长快速下降,当簇个数高于真实个数时,簇指标会趋于平稳
找到图中所示转折点,先确定k的大致范围,再通过二分查找确定k的值
算法停止条件
1.规定一个迭代次数,达到即停止
2.目标函数收敛

参考:http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
标签:
原文地址:http://www.cnblogs.com/smallby/p/4589340.html