标签:style blog class code java tar
声明:1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究。
2)本小实验工作环境为Ubuntu操作系统,hadoop1-2-1,jdk1.8.0。
3)统计词频工作在单节点的伪分布上,至于真正实际集群的配置操作还没有达到,希望能够由本文抛砖引玉。
(一)Hadoop的配置修正
按照网上教程,这一部分的设置很乱,有时候我还不成功,所以我琢磨了几天,然后决定修正前辈们的教程,决定用下面的方法步骤实现。
输入生成ssh钥匙的指令后,会遇到三行的提示。
当遇到提示输入文件名或是密码的地方不用管,只需按回车键即可。完成之后,在/home/username("username"是登录名)目录下会有生成 一个".ssh"目录,"ls .ssh"之后会发现里面有两个文件,一个是id_rsa,另一个是id_rsa.pub,前者是私钥,后者是公钥。
在终端输入
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
建立信任连接列表
在终端输入
ssh localhost
如果有错误提示,类似"ssh: connect to host localhost port 22: Connection refused",说明你没有安装ssh-client。
此时只需要在终端输入
sudo apt-get install openssh-client
安装完成后,再输入"ssh localhost"就应该没有问题了。按照提示输入相关信息就可以了。
登入时,显示update,记得登出!
输入exit登出即可。
再执行一次登入登出,则以后ssh无密码。
export JAVA_HOME=/usr/lib/jvm/jvm1.7.0_25
export HADOOP_HOME=/usr/hadoop-1.2.1
export PATH=$PATH: /usr/hadoop-1.2.1
若提示export路径错误,请给上面的路径加上双引号。
并source 此sh文件
若出现Warning: $HADOOP_HOME is deprecated.
(1)注释掉hadoop-config.sh里的上面给出的这段if fi配置(不推荐)
(2)在当前用户home/.bash_profile里增加一个环境变量:
export HADOOP_HOME_WARN_SUPPRESS=1
注:修改完.bash_profile后需要执行source操作使其生效
(二)伪分布启动
bin/hadoop namenode –format
bin/start-all.sh
如果配置没什么问题,那么hadoop就启动了,启动过程中,有一些信息打印出来,告诉你日志的输出目录。
bin/hadoop fs -put conf input
这个命令的意思是将当前目录下的conf目录的内容拷贝到hdfs文件系统的input目录。
|
web界面 下面是默认地址和端口 NameNode http://localhost:50070/ JobTracker http://localhost:50030/ NameNode界面,主要显示以下信息: 启动时间 编译时间 版本 HDFS文件目录结构 NameNode日志信息 分布式集群节点信息,如果死亡的节点,活动的节点,HDFS空间大小和使用率以及存储状态 JobTracker界面,其实是一个MapReduce管理界面,里面描述了以下信息 分布式计算的任务调度信息 集群分布式计算信息 如 正在运行的计算 已经完成的计算 失败的计算 本地的日志 |
注意:此指令意思是在分布式系统内新建一个input目录,然后把本机上的conf目录里的文件复制到分布式input目录里,所以会有两个推论:
1)只有在分布式里才能看得见input目录,即浏览器打开的MapReduce网址里,点开链接才能看得见input目录和里面的conf零碎文件,对照一下,发现是一样的,所以是复制过来的。值得一提的是input在分布式里的路径是/user/root/input
2)如果指令写成
bin/hadoop fs -put bin newfile
那么意思就是把本机的bin文件里的文件复制到分布式的新建一个目录,名叫newfile里。
bin/hadoop jar hadoop-*-examples.jar grep input output ‘dfs[a-z.]+‘
请注意,你的bin文件夹有没有这个demo例程,如果没有这条指令就没有用,那就意味着不会有程序的输入输出,所以下一个指令,有可能不成功,因为你没有程序的输出结果,自然不会有output
bin/hadoop fs -get output output 这句意思是将hdfs文件系统的output目录你内容拷贝到本地的output目录
cat output/* 打印本地output目录内容,其实就是打印执行结果拉。
或者直接在hdfs文件系统上查看:
bin/hadoop fs -cat output/*
如果保证确有demo,而且运行了,那么才有output目录,这些命令才能成功。假设你没有demo,简单修改一下指令即可,修改如下:
bin/hadoop fs -get intput output
这么修改的原因,我也是猜测的,我猜测input所在的命令位置是出于分布式里的源文件,后面的output位置表示本机的output目录。这样根据命令,它会自动寻找HDFS系统的里input目录,然后复制到本机上。
bin/stop-all.sh
(三)DEMO尝试
bin/hadoop namenode -format
1)执行bin/hadoop fs -put conf input时提示error,如下
Target input/conf is a directory
竟然不允许我复制,令人惊讶的是,之前首次测试我用的就是这个指令啊?首次可以,第二次不可以?
2)启动伪分布后,namenode的活跃节点显示为零,我就明白了伪分布没有真正的启动。
|
有时数据结构出现问题会产生无法启动datanode的问题。 然后用 hadoop namenode -format 重新格式化后仍然无效,/tmp中的文件并没有清除。 其实还需要清除/tmp/hadoop*里的文件。 执行步骤: 一、先删除hadoop:/tmp bin/hadoop fs -rmr /tmp 二、停止 hadoop bin/stop-all.sh 三、删除/tmp/hadoop* rm -rf /tmp/hadoop* 四、格式化hadoop bin/hadoop namenode -format 五、启动hadoop bin/start-all.sh 之后即可解决这个datanode没法启动的问题 |
1)要有源程序,貌似这是句废话,但是只有实践了才知道这句话是多么的痛的领悟!源程序的获取,我遇到两个问题:
一是Ubuntu系统下javac编译源程序,总是报编码错误,经过我修改指令后,要么UTF8错误,要么Unicode错误。我修改的指令如下:
javac –encoding GBK WordCount.java (GBK换成其他的编码也可以)
结论就是无尽的失败,怎么编译就是得不到class文件,最终解决方法就是我找了一个class文件的源程序。
二是class程序在Ubuntu又打不开,什么剧情?!java后缀文件可以打开,编译不了,class后缀文件打开不了却可以用。对Ubuntu的指令程序模式很佩服,但对于缺少界面的操作,习惯了Windows下利用有界面的软件可以反复调试,现在缺少交互界面,很是伤脑筋!
2)利用class程序进行打包,以备Hadoop可以调用该打包好的jar。结果我又遇到问题:
打包没有问题,指令如下:
jar cvf WordCount.jar WordCount.class
该死的Jar包无法识别,使用如下指令时,报出程序代码的本身错误:
bin/hadoop jar WordCount.jar WordCount HDFSWordCount Output
先需要声明一下上面的指令含义,虽然执行失败,但是后面会提到相关的意义。上面的指令,按照顺序的含义就是,使用hadoop程序的jar shell去调用本机的某个jar包,具体调用的是这个jar包里面某个类,然后最后两个参数,前面是分布式的输入目录,后者是分布式的输出目录。
解决的问题关键在于,这个WordCount程序不能割裂开来,单独打包,因为我寻找的这个程序在编写时已经集成在jar里,被我单独提取出来,反而导致问题。因此我直接使用example.jar。
3)解决上述问题的方式就是寻找了一个集成的jar包,这个jar包里有很多程序,其中就有统计词频的。我选择的是Hadoop安装包里的Hadoop-examples-1.2.1.jar包里的,网上都可以搜索下载的。甚至是你如果有hadoop1-2-1安装包程序,在安装包里就有这个jar包。
此时再执行指令:
bin/hadoop jar Hadoop-examples-1.2.1.jar WordCount HDFSWordCount Output
请注意:仍然失败!后修改成为如下,再次执行
bin/hadoop jar Hadoop-examples-1.2.1.jar WordCount.class HDFSWordCount Output
请注意:又是失败!怨念四起!
最后琢磨一下,明白了,立刻得到最后的正确答案,就是如下指令:
bin/hadoop jar Hadoop-examples-1.2.1.jar wordcount HDFSWordCount Output
成功!
并显示作业流程,具体的统计词频结果,由于你的指令,生成在分布式的Output目录里呢,如何查看?可以执行如下指令:
bin/hadoop fs –cat Output/part-r-00000
哈哈,就可以看到程序的具体统计结果啦!
1)做实验的统计词频,当然是需要测试数据集,自行建立一个TXT,然后随便写点单词之类的东西上去就成。
2)这个JAVA程序写得很不错,甚至对于我这样的技术菜鸟来说,我感到很牛。因为,我担心程序读入时产生错误,原因是大家都知道C/C++读入东西,切割开词组需要用空格或者很多分隔符,写起来很麻烦的。那么之所以能够两个TXT都能读取,原因在于Hadoop的分布式,为什么MapReduce的任务数是2,不仅仅是因为两个文本,更重要的是如果不设置MapReduce的参数,默认按照文件的数量来划分块,所以为什么看到每个文件(即使是几KB的小文件),占据着64M的文件块。所以在优化上,还有待学习提高。
3)下一阶段我的目标是要租借几个云服务器,实现自己的分布式小程序。由于上述教程贴图实在是破坏排版,所以我把上面实验的一些结果图全部粘贴在本文末尾。
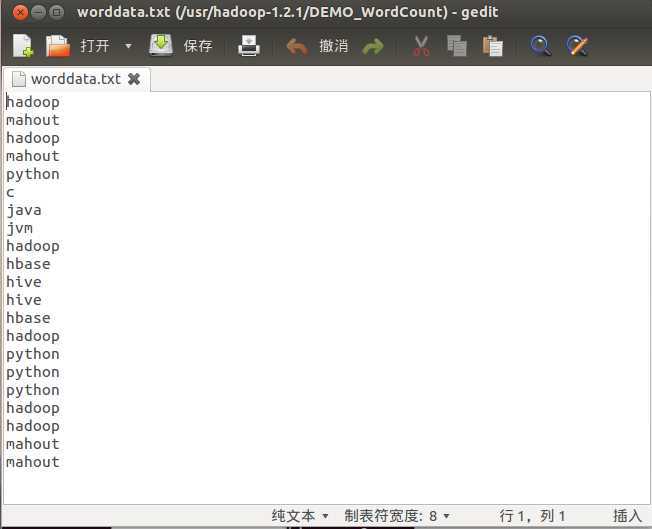
上图为词频统计的输入样本(一共两个,这是第一个)
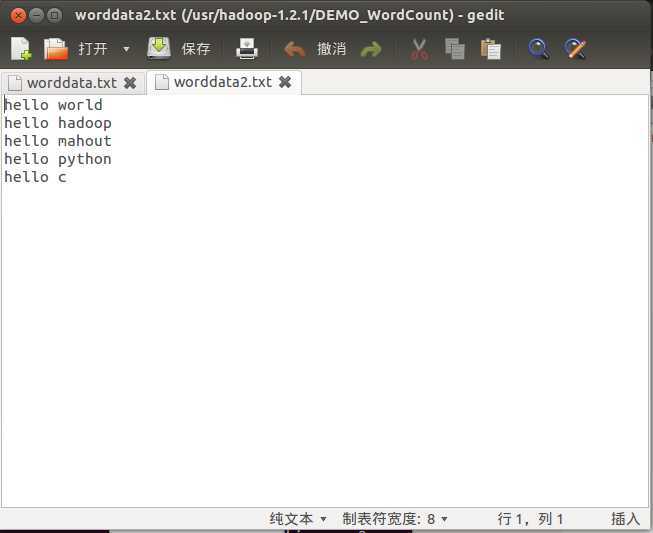
上图为词频统计的输入样本(一共两个,这是第二个)
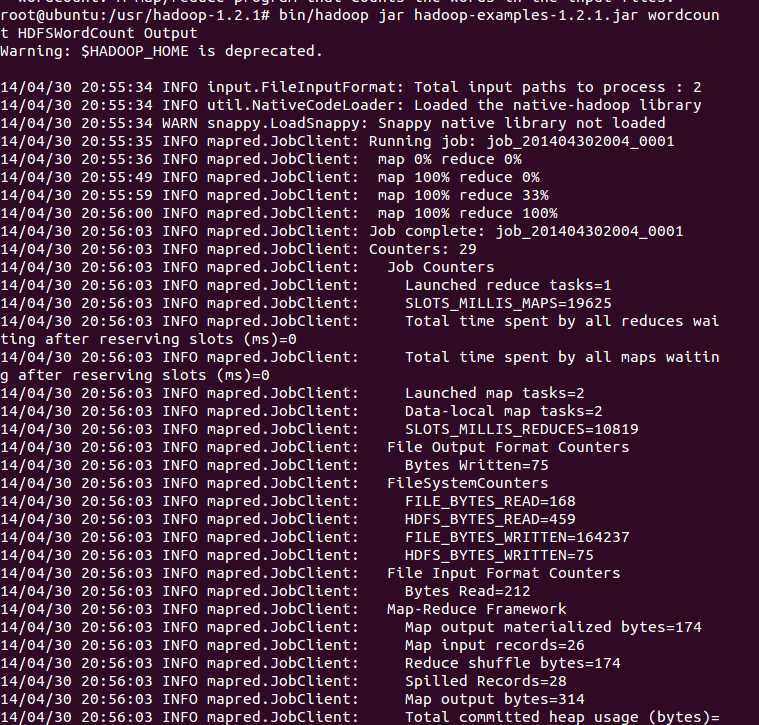
上图为通过Hadoop执行词频统计jar包的流程示意图
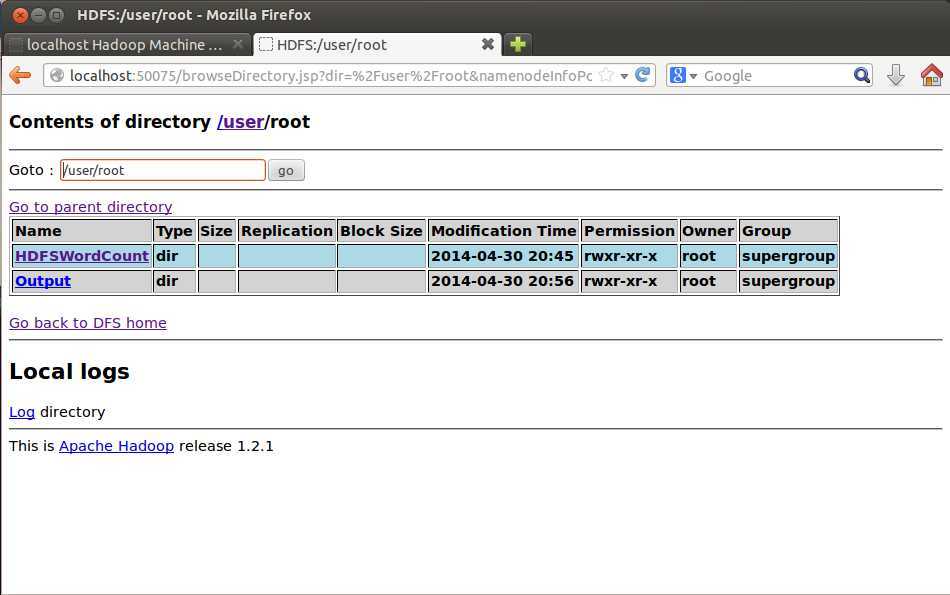
上图为,输入目录(即样本所在目录位HDFSWordCount),根据指令生成保存输出结果的目录为Output
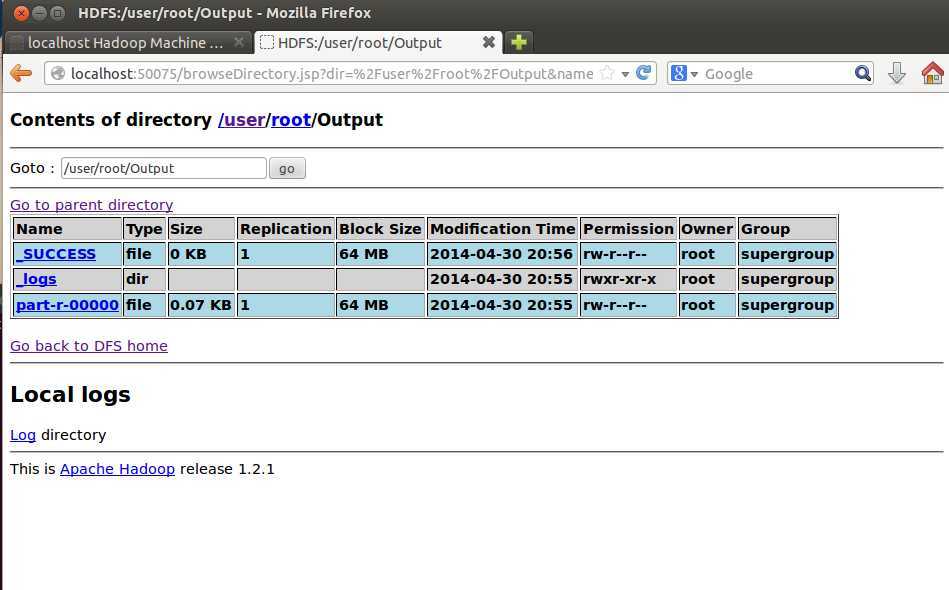
上图为在分布式上生成的输出目录里的具体文件(part-r-00000是保存程序结果的文件)。
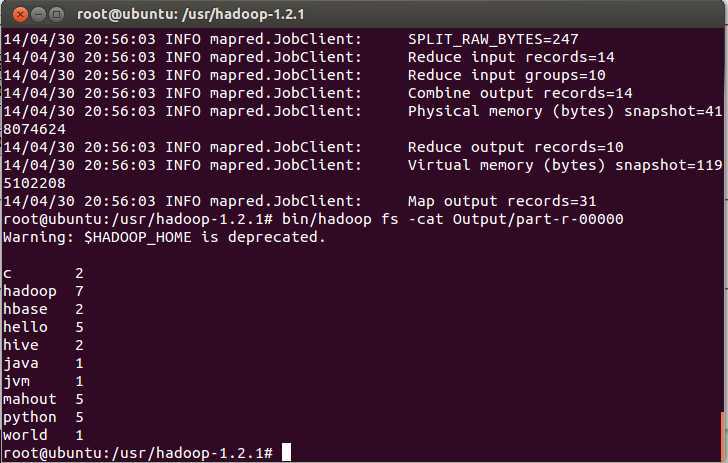
上图为查看输出目录里的统计结果
Hadoop之词频统计小实验(基于单节点伪分布),布布扣,bubuko.com
标签:style blog class code java tar
原文地址:http://www.cnblogs.com/bitpeach/p/3705008.html