标签:
PKU 1204 Word Puzzles
题目的大意为:
要求编程实现查找字谜拼图中的单词,输出查找到的单词的起始位置和方向(ABCDEFGH分别代表北、东北、东、东南、南、西南、西、西北八个方向)。
输入:
输入的第一行包含三个正数:行数,0<L<=1000;列数,0<C<= 1000;和字谜单词个数0<W<=1000。接下来的L行,每行输入C个字符。最后W行每行输入一个字谜单词。
输出:
你的程序应该每行输出每个单词(跟输入的顺序相同)第一个字母出现的行和列的下标。在三个值之间必须是一个空间分隔。
解题思路:
此题涉及到单词字符串的查找匹配,为了提高查找效率,减少空间耗费,可以考虑使用字典树,字典树的优点是能利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
字典树的根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
针对该题,可以设计一个26个大写字母的字典树,结点结构为:
struct Node{
int index;//字符串结尾标志,单词的序号,初始化为-1
Node* next[26];//指向26个子树的指针数组,初始化为null
};
此处用到的操作有插入,查找;
字典树插入字符串的方法为:
(1)从根结点的子结点开始插入的字符串的第一字符,(若该子结点为空,创建该结点),并将该结点作为下一个字符的父结点。
(2)迭代到下一个字符,直至字符串全部插入。
(3)在字符串最后一个字母的结点标记该字符串的序号,方便查找。
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在某个结点处,关键词的所有字母已被取出(index非负),即完成查找,若结点为空,查找失败。
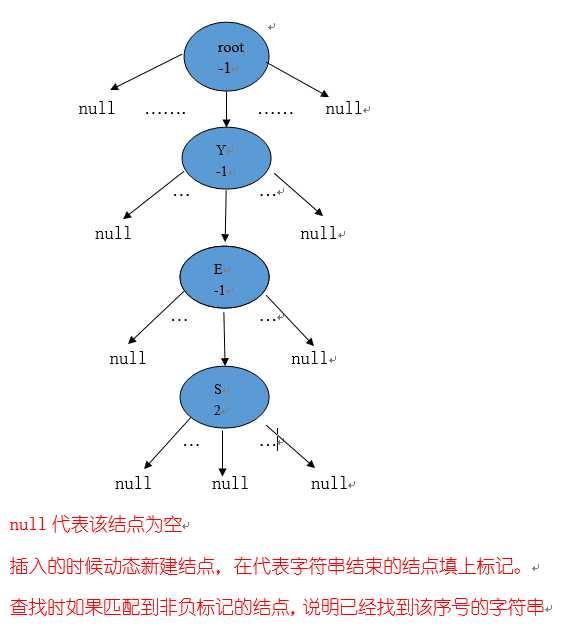
例如:往一棵空树中插入序列:YES,假设该字符串的序号index为2
代码:
#include<stdio.h>
#include <memory.h>
#define MaxNode 26//子结点数量
char puzzle[1001][1001];
//A...H的8个方向
int D[8][2] = { { -1, 0 }, { -1, 1 }, { 0, 1 }, { 1, 1 },
{ 1, 0 }, { 1, -1 }, { 0, -1 }, { -1, -1 } };
struct {
int x;
int y;
char dir;
}outputList[1001];//记录单词位置和方向的数组
struct TrieNode{//结点结构
public:
int wordIndex;//单词序号
TrieNode* next[MaxNode];//26个字母的子结点指针
TrieNode(){//构造函数
wordIndex = -1;
memset(next, NULL, sizeof(TrieNode*)*MaxNode);
}
};
class Trie{//字典树
public:
int MaxRow, MaxCol, MaxWords;
Trie()
{
root = new TrieNode();
};
int find(int i, int j,char dir)//从i行,j列沿dir方向查找
{
int pos = puzzle[i][j] - ‘A‘;
int x = i,y = j;
TrieNode* current = root->next[pos];
while (current != NULL)
{
if (current->wordIndex > 0)//找到单词,记录单词位置和方向
{
outputList[current->wordIndex].x = x;
outputList[current->wordIndex].y = y;
outputList[current->wordIndex].dir = (char)dir + ‘A‘;;
}
i += D[dir][0]; j += D[dir][1];//dir方向的下一个字母的下标
if (i < 0||j<0||i>=MaxRow||j>=MaxCol)break;//超出puzzle图则跳出循环
pos = puzzle[i][j] - ‘A‘;
current = current->next[pos];//指向下一个字典树结点
}
return -1;
};
void insert(char *des,int index)//插入序号为index的字符串des
{
TrieNode* current = root;//从根结点开始
int pos;
for (; *des!=‘\0‘; des++)//将每个字符插入
{
pos = *des - ‘A‘;
if (current->next[pos] == NULL)
current->next[pos] = new TrieNode();//结点为空则创建
current = current->next[pos];
}
current->wordIndex = index;//插入结束,标记该字符串序号
};
private:
TrieNode * root;//树根指针
};
int main()
{
Trie T;
scanf("%d%d%d", &T.MaxRow, &T.MaxCol, &T.MaxWords);
getchar();//去掉换行符
for (int i = 0; i < T.MaxRow; i++)
{
gets(puzzle[i]);
}
char t[1001];
for (int i = 1; i <= T.MaxWords; i++)
{
gets(t);
T.insert(t,i);
}
for (int i = 0; i < T.MaxRow; i++)
for (int j = 0; j < T.MaxCol; j++)
{
for (int dir = 0; dir <= 7; dir++)
{
T.find(i, j, dir);
}
}
for (int i = 1; i <= T.MaxWords; i++)
{
printf("%d %d %c\n", outputList[i].x, outputList[i].y, outputList[i].dir);
}
return 0;
}
标签:
原文地址:http://www.cnblogs.com/litianhan/p/4590512.html