标签:
(1)字典树(Trie树)
Trie是个简单但实用的数据结构,通常用于实现字典查询。我们做即时响应用户输入的AJAX搜索框时,就是Trie开始。本质上,Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。还是例子最清楚。给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
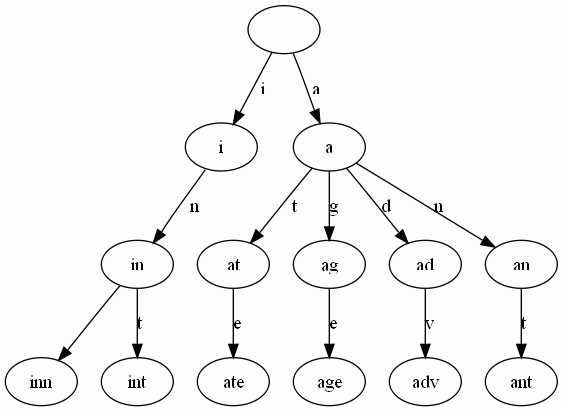
可以看出:
(2)后缀树
所谓后缀树,就是包含一则字符串所有后缀的压缩了的字典树。先说说后缀的定义。给定一长度为n的字符串S=S1S2..Si..Sn,和整数i,1 <= i <= n,子串SiSi+1...Sn都是字符串S的后缀。以字符串S=XMADAMYX为例,它的长度为8,所以S[1..8], S[2..8], ... , S[8..8]都算S的后缀,我们一般还把空字串也算成后缀。这样,我们一共有如下后缀。对于后缀S[i..n],我们说这项后缀起始于i。
所有这些后缀字符串组成一棵字典树:

仔细观察上图,我们可以看到不少值得压缩的地方。比如蓝框标注的分支都是独苗,没有必要用单独的节点同边表示。如果我们允许任意一条边里包含多个字母,就可以把这种没有分叉的路径压缩到一条边。另外每条边已经包含了足够的后缀信息,我们就不用再给节点标注字符串信息了。我们只需要在叶节点上标注上每项后缀的起始位置。于是我们得到下图:
这样的结构丢失了某些后缀。比如后缀X在上图中消失了,因为它正好是字符串XMADAMYX的前缀。为了避免这种情况,我们也规定每项后缀不能是其它后缀的前缀。要解决这个问题其实挺简单,在待处理的子串后加一个空字串就行了。例如我们处理XMADAMYX前,先把XMADAMYX变为 XMADAMYX$,于是就得到suffix tree。

这就形成一棵后缀树了。关于如何建立一棵后缀树,已有很成熟的算法,能在o(n)时间内解决。
(3)广义后缀树
传统的后缀树只能处理一个单词的所有后缀。广义后缀树存储任意多个单词的所有后缀。例如字符串“abab”和“baba”,首先将它们使用特殊结束符链接起来,如表示成“abab$baba#”,然后求连接后的新字符的后缀树,遍历所得后缀树,如遇到特殊字符,如“$”,"#"等则去掉以该节点为跟的子树,最后所得后缀树即为原字符串组的广义后缀树。其实质是将两个字符串的所有后缀,即:abab$,bab$,ab$,b$,baba#,aba#,ba#,a#,组成字典树,再进行压缩处理。广义后缀树的一个常应用就是判断两个字符串的相识度。
标签:
原文地址:http://www.cnblogs.com/yanqi0124/p/4598592.html