标签:
本文转载自:http://blog.pluskid.org/?p=381
之前介绍 Scrapy 的时候提过 Spider Trap ,实际上,就算是正常的网络拓扑,也是很复杂的相互链接,虽然我当时给的那个例子对于我感兴趣的内容是可以有一个线性顺序依次爬下来的,但是这样的情况在真正的网络结构中通常是少之又少,一但链接网络出现环路,就无法进行拓扑排序而得出一个依次遍历的顺序了,所以 duplicate elimination 可以说是每一个 non-trivial 的必备组件之一,这样就算在遍历的过程中遇到环路也不用怕,排重组件会检测到已经访问过的地址,从而避免在环路上无限地循环下去。最简单的办法也就是每次抓取页面的时候记录下 URL ,然后每次抓取新的 URL 之前先检测一下是否已经有记录了。不过,通常我们并不直接按字符比较 URL ,因为那样通常会漏掉许多本来确实是重复的 URL ,特别是现在动态页面盛行的情况,例如在 cc98 (ZJU 的一个校内论坛)上下面几个 URL 路径是等价的:
1 和 2 是参数位置交换,这个问题几乎存在于所有动态页面上,因为通常的 CGI (姑且统称为 CGI 吧)并不在意参数出现的顺序,而 3 则是 cc98 自己的问题,实际上 page 这个参数对于现实一个帖子没有什么用处,写成多少都无所谓,它是帖子标题列表那个页面的页数,但是 cc98 有时确实会在现实帖子的时候把那个参数也附上。所以,判重组件要做到火眼金睛还是相当困难的,事实上,Internet 上的 URL 和它对应的内容是多对多的关系,即使同一个 URL 在不同时间访问也有可能得到不同的结果(例如一个 Google 的搜索结果页面),所以,判重组件错判和漏判都是有可能的,虽然如此,我们可以利用一些经验知识来做到尽量完善,另外,和上次说的一样,如果问题被限制在一个已知的领域(比如,某个特定的网站而不是混乱的 Internet ),问题又会变得简单许多了。
扯了半天,再回到 Scrapy 。因为自己之前做的一些小实验发现如果给他重复的 URL 的话,它是会义无反顾的地再抓一遍的,而在它的 Tutorial 里也只字未提相关的东西,所以我一直以为它没有提供现成的东西,虽然一个号称已经在实际中使用了的爬虫框架没有判重组件多少是一件有点让人难以置信的事。不过事实证明它其实是有判重组件的,从它的结构图(见上一篇介绍 Scrapy 的 blog )中可以看到,判重组件如果要自己写的话,应该是一个 Scheduler Middleware ,本来想看一下 Scheduler Middleware 的接口是怎样的,打开文档一看,才发现已经有了一个现成的 DuplicatesFilterMiddleware 了。
如果要添加自己的 Scheduler Middleware ,应该在 settings.py 里定义 SCHEDULER_MIDDLEWARES 变量,这是一个 dict 对象,key 是中间件的完整类名,value 则是 priority 。不过在系统级别的 SCHEDULER_MIDDLEWARES_BASE 里已经有了这个中间件了:
SCHEDULER_MIDDLEWARES_BASE = { ‘scrapy.contrib.schedulermiddleware.duplicatesfilter.DuplicatesFilterMiddleware‘: 500, }
再经过各种跟踪(之间还不会用 Python 调试器,都是直接打开库的源代码插入 print 语句 -,-bb),发现中间件确实被启动起来了,而且判重的方法也被调用了,并且也检测到了重复,不过,问题出在这里:
def enqueue_request(self, domain, request): seen = self.dupefilter.request_seen(domain, request) if seen and not request.dont_filter: raise IgnoreRequest(‘Skipped (request already seen)‘)
那个 dont_filter 属性在作怪,由于 spider 对象的 make_requests_from_url 方法把 Request 的 dont_filter 属性设成了 True ,因此导致判重组件失效了:
def make_requests_from_url(self, url): return Request(url, callback=self.parse, dont_filter=True)
可以看到这个方法其实非常简单,也可以自己手工构建 Request 对象,指定 callback ,并且 dont_filter 默认是 False 的,这样就能得到想要的效果了。
其实 Scrapy 提供的 duplicate filter 是相当灵活的,它把中间件和判重算法分离开来,预置了两种判重的实现,一个是 NullDupeFilter ,什么都不管,只会返回“不重复”,另一个是 RequestFingerprintDupeFilter (也是默认装配的那个),使用一个 Request 的 fingerprint 来进行比对。fingerprint 主要是通过 url 取 hash 计算出来的,当然为了能处理简单的参数位置变换的情况,减少漏判,具体可以参见 utils/request.py 的 request_fingerprint 方法。
要实现自己的 Duplicate Filter 有两种方法,一种是以算法的形式,在 settings.py 里将 DUPEFILTER_CLASS 指定为自己定义的类,这样会用自己的算法替换掉系统的算法;另一种方法是不影响系统默认的 filter ,另外再实现一个 filter middleware 添加到 SCHEDULER_MIDDLEWARES 里,写法大同小异,只是接口有稍许不同,下面介绍第二种写法。新建一个文件 scheduler_middleware.py (其实名字可以随便取),在里面实现我们的判重中间件:
from scrapy.core.exceptions import IgnoreRequest from scrapy.extension import extensions from crawl.cc98_util import extract_url, DOMAIN class DuplicatesFilterMiddleware(object): def open_domain(self, domain): if domain == DOMAIN: self.init_fingerprints() def close_domain(self, domain): if domain == DOMAIN: self.fingerprints = None def enqueue_request(self, domain, request): if domain != DOMAIN or request.dont_filter: return fp = self.make_fingerprint(extract_url(request.url)) if fp in self.fingerprints: raise IgnoreRequest(‘Skipped (request already seen)‘) self.fingerprints.add(fp) def make_fingerprint(self, dic): return ‘%s,%s,%s‘ % (dic[‘board_id‘],dic[‘thread_id‘],dic[‘page_num‘]) def init_fingerprints(self): self.fingerprints = set()
主要是要实现三个方法:open_domain, close_domain 和 enqueue_request ,如果发现 Request 对象应该丢弃的话,直接抛出 IgnoreRequest 异常即可。这里我用 extract_url 方法(就是正则匹配,就不细说了)提取出 board_id, thread_id 和 page_num 三个参数,将他们的值排列起来做成一个 fingerprint ,用在 cc98 这里是正好的。然后在 settings.py 里加入:
SCHEDULER_MIDDLEWARES = { ‘crawl.scheduler_middlewares.DuplicatesFilterMiddleware‘: 500 }
就可以用上我们自己的判重过滤了。  到此为止本来关于本文标题的东西可以说已经讲完了,不过这个 crawler 要完整还需要一些额外的东西,我就顺便多说一下吧。
到此为止本来关于本文标题的东西可以说已经讲完了,不过这个 crawler 要完整还需要一些额外的东西,我就顺便多说一下吧。
首先是抓取结果的处理,这次我并不是直接存储 raw 的 HTML 页面,而是将内容解析之后按照帖子结构存储在数据库里。在最近更新过之后发现原来的 ScrapedItem 在将来的版本里将会由 Item 来替代了,现在可以用类似于 ORM 的方式来定义 Item ,也许以后会做得像 Django 的 Model 那样方便地用于数据库上吧:
from scrapy.item import Item, Field class CrawlItem(Item): board_id = Field() thread_id = Field() page_num = Field() raw = Field() def __str__(self): return ‘<CrawlItem %s,%s,%s>‘ % (self[‘board_id‘], self[‘thread_id‘], self[‘page_num‘]) class PostBundleItem(Item): posts = Field() def __str__(self): return ‘<PostBundleItem %d>‘ % len(self[‘posts‘])
一次下载的一个页面会得到一个 CrawlItem 对象,这是论坛里一页的内容,一页内通常有多个 post ,所以我再添加了一个 pipeline 来将一个页面解析成多个 post ,存储在一个 PostBundleItem 对象中。pipeline 就不细说了,上次介绍过,只要定义 process_item 方法即可,这样在 settings.py 里我就依次有两个 pipeline :
ITEM_PIPELINES = [‘crawl.pipelines.PostParsePipeline‘, ‘crawl.pipelines.PostStorePipeline‘]
代码也不多帖了,画一个图直观一点(画这个图里的字体实在是太丑了,但是手边没有好用的工具,也只能暂时将就了 -,-bb):
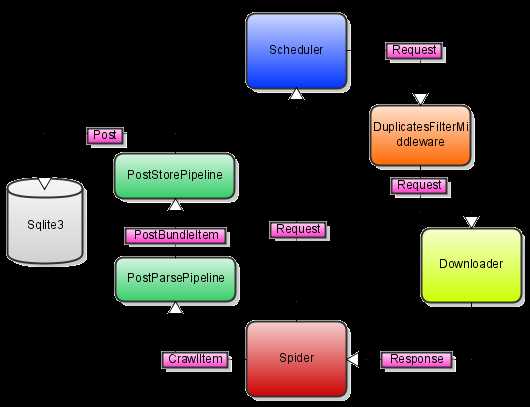
不过,如果你有注意到,不管是 Scrapy 内置的判重组件还是我上面的组件,所用的数据结构都是直接放在内存里的,所以说如果你一次 crawl 结束(包括正常结束,或者断电、断网、程序出错等异常结束)之后,如果再重新启动 crawler ,判重组件会从零开始,于是许多的页面又要重新下载一次。这当然不是我们说希望的,因此我要在 crawler 启动的时候从数据库里提取出已经抓取了的页面来初始化 duplicates filter ;另外,为了达到增量抓取的目的,我希望每次 crawler 启动的时候从上一次结束的地方开始抓取,而不是每次都使用同一个固定的 seed url ,这也需要用到数据库里已经存在的数据。
由于各个组件都要访问数据库,因此我做一个 Scrapy Extension 来管理数据库连接。在 Scrapy 中做一个 Extension 也是一件很容易的事情,随意写一个类就可以作为 Extension ,没有任何限制或规定,例如:
import sqlite3 from os import path from scrapy.conf import settings from scrapy.core import signals from scrapy.xlib.pydispatch import dispatcher from scrapy.core.exceptions import NotConfigured class SqliteManager(object): def __init__(self): if settings.get(‘SQLITE_DB_FILE‘) is None: raise NotConfigured self.conn = None self.initialize() dispatcher.connect(self.finalize, signals.engine_stopped) def initialize(self): filename = settings[‘SQLITE_DB_FILE‘] if path.exists(filename): self.conn = sqlite3.connect(filename) else: self.conn = self.create_table(filename) def finalize(self): if self.conn is not None: self.conn.commit() self.conn.close() self.conn = None def create_table(self, filename): # ... snipped ...
然后在 settings.py 里指定加载该 Extension 即可:
EXTENSIONS = { ‘crawl.extensions.SqliteManager‘: 500 }
同 middleware 一样,后面那个 500 表示优先级。另外,上面的代码中如果发现没有定义 SQLITE_DB_FILE 变量(也是在 settings.py 中)的话会抛出 NotConfigured 异常,这个异常并不会导致 crawler 启动出错,此时 Scrapy 只是会简单地选择不启用该 Extension 。其实我这里的 SqliteManager 是一个相当核心的组件,如果不启用的话整个系统就没法正常工作了,所以这样的行为似乎应该修改一下。
Extension 定义好之后在程序中引用也很方便,把 scrapy.extension 里的 extensions 对象 import 进来,然后用 extensions.enabled[‘SqliteManager‘] 就可以引用到系统为你初始化好的那个 Extension 对象了,以这种引用方式看来,Extension 的类名似乎得是 unique 的才行。
有一点要注意的地方就是各个组件之间的依赖关系,特别是在初始化的时候,例如,我这里 DuplicatesFilterMiddleware 和 spider 在初始化的时候都会用到 SqliteManager 的数据库连接,因此 SqliteManager 需要在对象构造的时候就建立好连接(或者惰性按需建立也可以),而不是像上一篇文章中那样在 signals.engine_started 的时候再建立连接。而且,由于 Scrapy 建立在 Twisted 这个看起来非常魔幻的异步网络库的基础上,程序出错之后想要轻松地调试几乎是不可能的,得到的错误信息和 trackback 通常都是风马牛不相及,这个时候似乎只有反复检查代码是最终有效的“调试”方式了。 
这样,我们将前面定义的 init_fingerprints 方法稍作修改,不再是只建立一个空的 set ,而是从数据库里做一些初始化工作:
def init_fingerprints(self): self.fingerprints = set() mgr = extensions.enabled[‘SqliteManager‘] cursor = mgr.conn.execute(‘select distinct board_id, thread_id, page_num from posts‘) for board_id, thread_id, page_num in cursor: fp = self.make_fingerprint({‘board_id‘:board_id,‘thread_id‘:thread_id,‘page_num‘:page_num}) self.fingerprints.add(fp)
在上一篇文章的介绍中,spider 使用 start_urls 属性作为 seed url ,其实实际使用的是一个 start_requests 方法,不过 BaseSpider 提供了一个默认实现,就是从 start_urls 构建初始 Requests ,我们为了实现增量 crawler ,只要重新定义 spider 的该方法即可:
def start_requests(self): mgr = extensions.enabled[‘SqliteManager‘] val = mgr.conn.execute(‘select max(page_num) from posts‘).fetchone()[0] if val is None: page_num = 1 else: page_num = val # the last page may be incomplete, so we set dont_filter to be True to # force re-crawling it return [Request(make_url(board_id=self.board_id, thread_id=self.thread_id, page_num=page_num), callback=self.parse, dont_filter=True)]
虽然跑题已经跑得有点远了,不过这样一来,我们就得到了一个比先前更加完善的爬虫了。
【转】Duplicate Elimination in Scrapy
标签:
原文地址:http://www.cnblogs.com/rwxwsblog/p/4603694.html