标签:
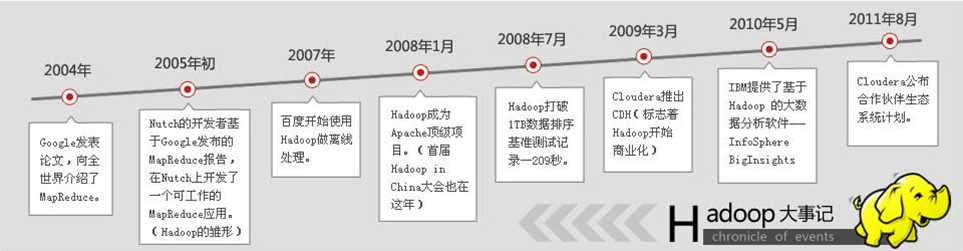
说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google。Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的GFS(Google File System),从此文件系统进入分布式时代。除此之外,Google在GFS上如何快速分析和处理数据方面开创了MapReduce并行计算框架,让以往的高端服务器计算变为廉价的x86集群计算,也让许多互联网公司能够从IOE(IBM小型机、Oracle数据库以及EMC存储)中解脱出来,例如:淘宝早就开始了去IOE化的道路。然而,Google之所以伟大就在于独享技术不如共享技术,在2002-2004年间以三大论文的发布向世界推送了其云计算的核心组成部分GFS、MapReduce以及BigTable。Google虽然没有将其核心技术开源,但是这三篇论文已经向开源社区的大牛们指明了方向,一位大牛:Doug Cutting使用Java语言对Google的云计算核心技术(主要是GFS和MapReduce)做了开源的实现。后来,Apache基金会整合Doug Cutting以及其他IT公司(如Facebook等)的贡献成果,开发并推出了Hadoop生态系统。Hadoop是一个搭建在廉价PC上的分布式集群系统架构,它具有高可用性、高容错性和高可扩展性等优点。由于它提供了一个开放式的平台,用户可以在完全不了解底层实现细节的情形下,开发适合自身应用的分布式程序。
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要的两种组成元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)和上层用来执行MapReduce程序的MapReduce引擎。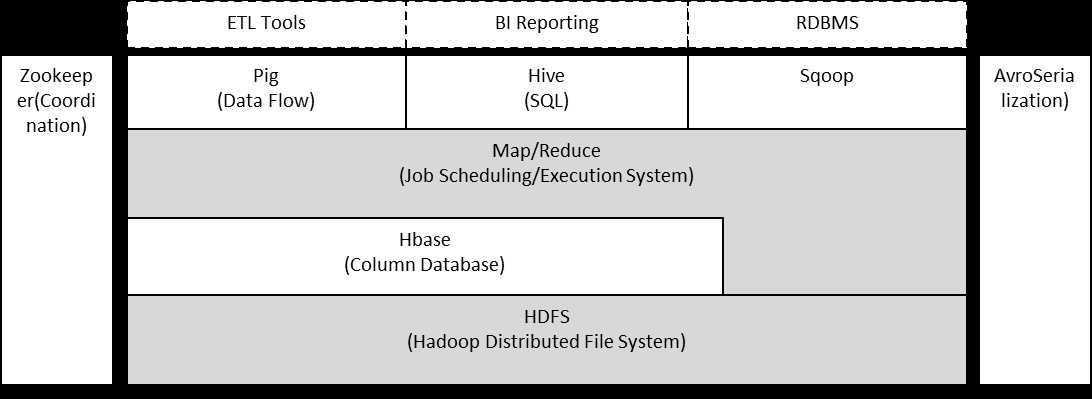
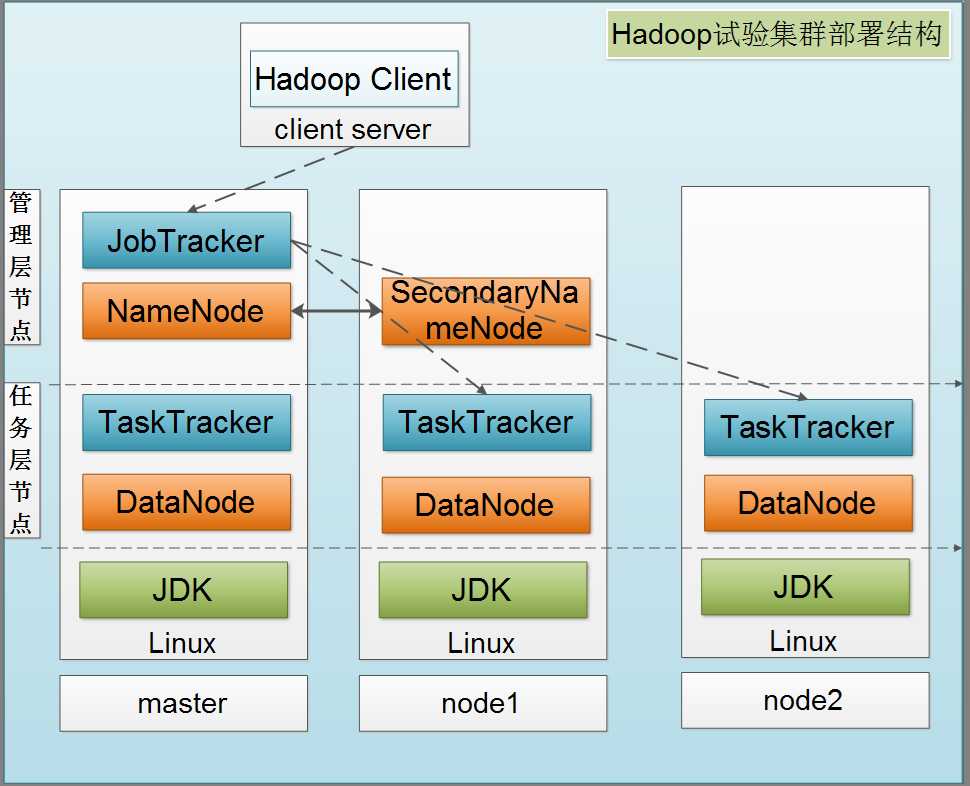
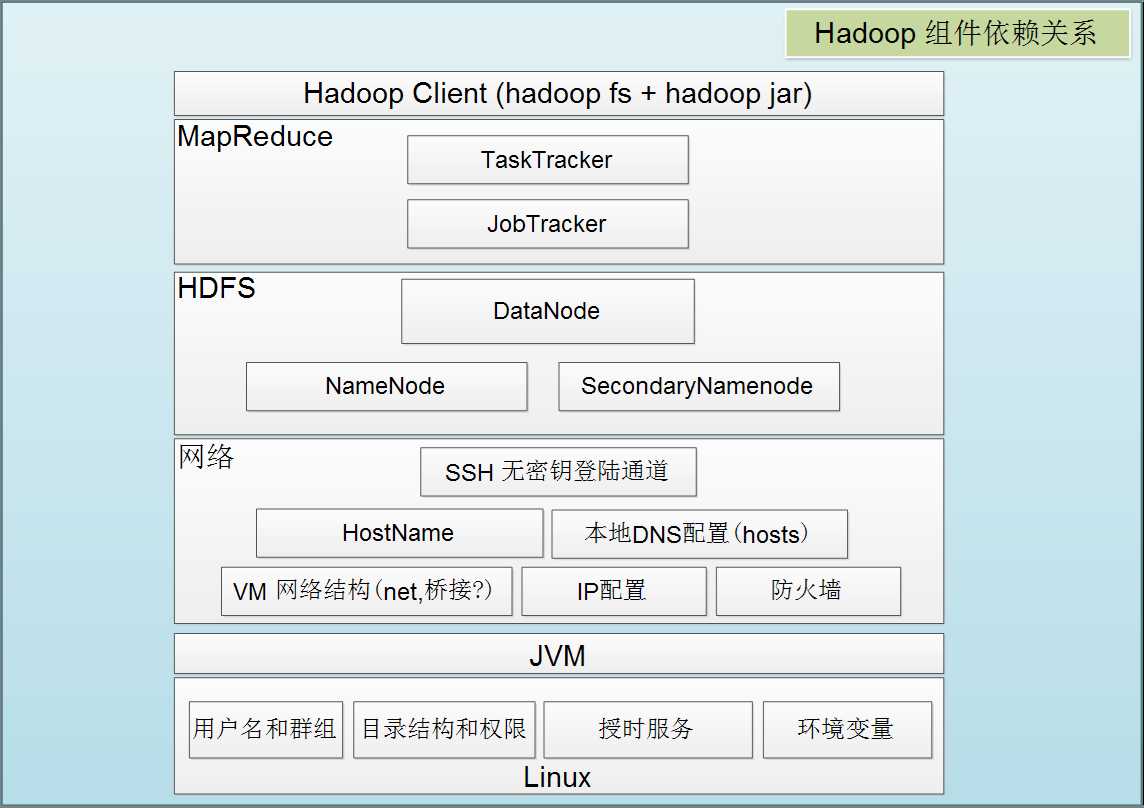
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC之上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS的架构如下图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。
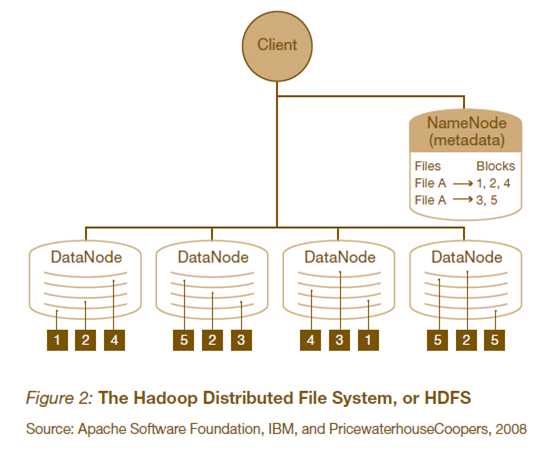
可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
就是需要获取分布式文件系统文件的应用程序。
下面来看看在HDFS上如何进行文件的读/写操作:
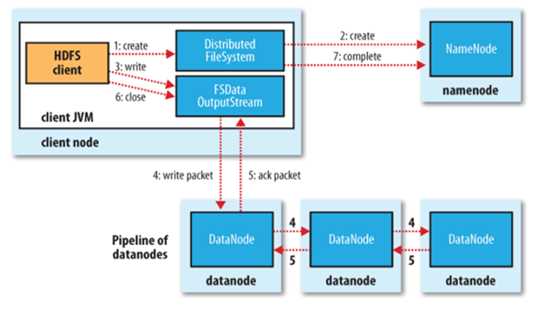
文件写入:
1. Client向NameNode发起文件写入的请求
2. NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
3. Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
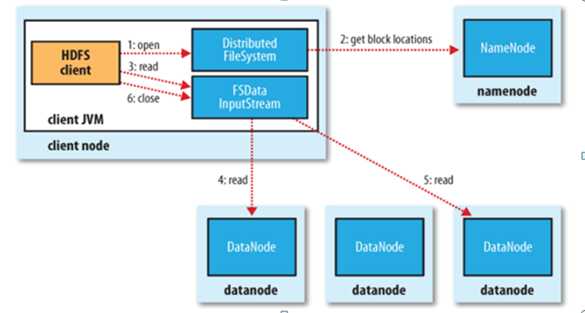
文件读取:
1. Client向NameNode发起文件读取的请求
2. NameNode返回文件存储的DataNode的信息。
3. Client读取文件信息。
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
下图是一个MapReduce的处理过程:
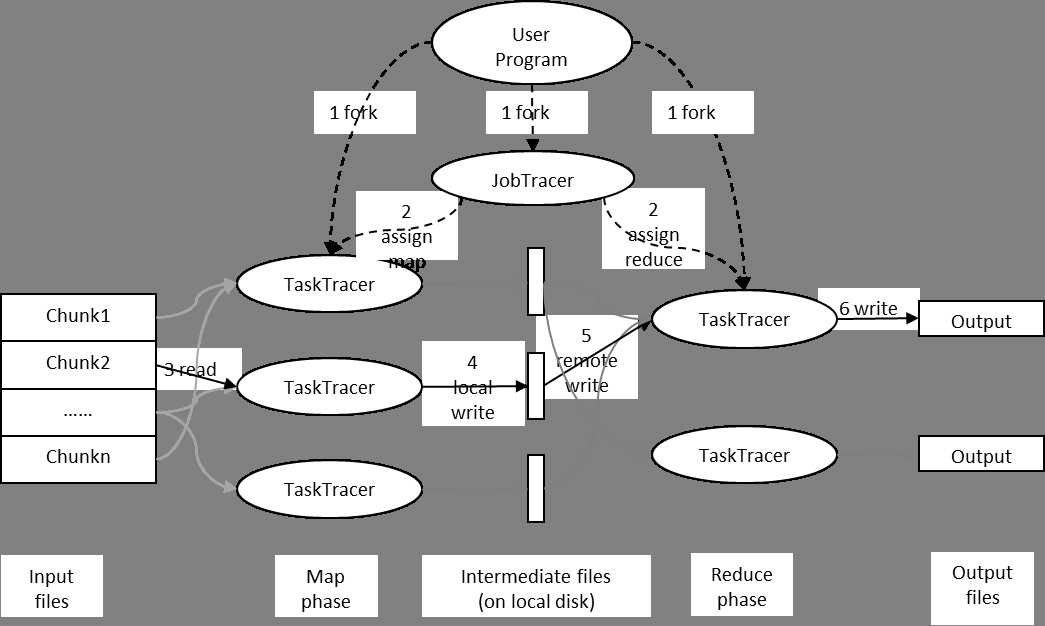
用户提交任务给JobTracer,JobTracer把对应的用户程序中的Map操作和Reduce操作映射至TaskTracer节点中;输入模块负责把输入数据分成小数据块,然后把它们传给Map节点;Map节点得到每一个key/value对,处理后产生一个或多个key/value对,然后写入文件;Reduce节点获取临时文件中的数据,对带有相同key的数据进行迭代计算,然后把终结果写入文件。
如果这样解释还是太抽象,可以通过下面一个具体的处理过程来理解:(WordCount实例)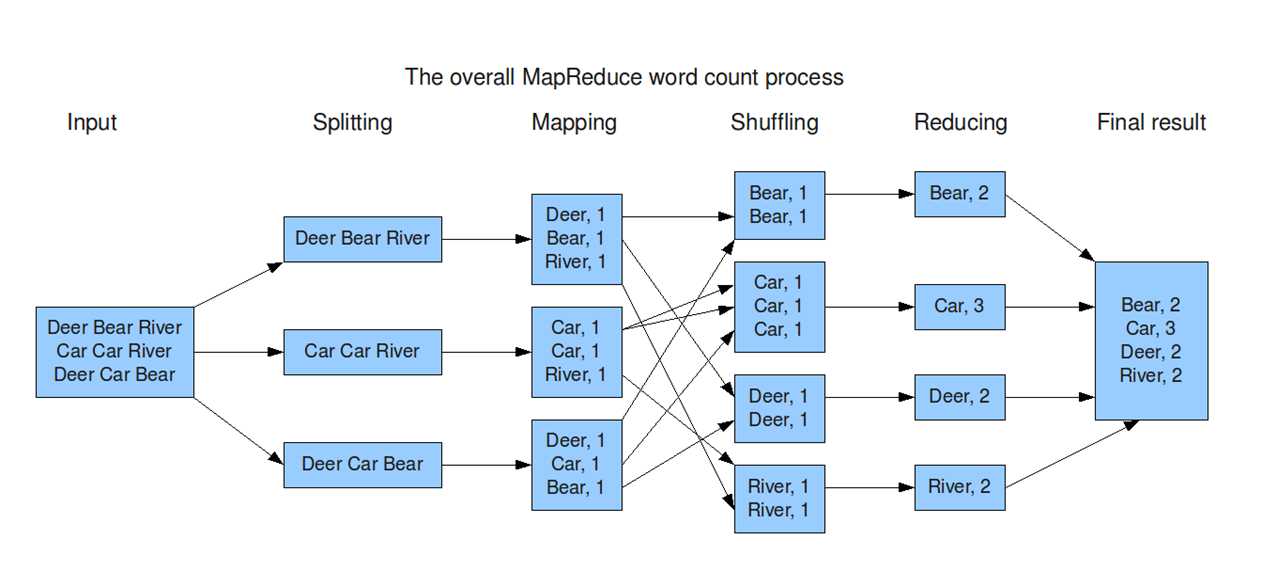 Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
但是,Map/Reduce并不是万能的,适用于Map/Reduce计算有先提条件:
①待处理的数据集可以分解成许多小的数据集;
②而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合使用Map/Reduce模式;
四、Hadoop的安装配置:详见本博
http://www.cnblogs.com/yangxiao99/p/4574889.html
欢迎各位来探讨交流:QQ:747861092
QQ群:163354117 (群名称:CodeForFuture)
标签:
原文地址:http://www.cnblogs.com/yangxiao99/p/4605115.html