标签:
随着业务的快速成长,日访问量越来越高,除了对功能要求很高以外,对性能要求也越来越高。 在实际工作中,我们往往会被一些问题所困扰。
1)线上服务容量是多少?性能痛点在哪里? 可伸缩性(resilience)和可靠性(reliability)怎样?预先知道了系统的容量,做到心中有数,才能为最终规划整个运行环境的配置提供有利的依据。
2)新开发的功能是否满足性能指标? 重新修改的代码会不会带来性能问题? 对服务或工具的参数修改是否有效果(如jvm参数,mysql或solr配置等)? 如果在上线用前就能进行验证,那么不仅能极大降低部署时发生意外的概率,还能为性能优化提供指导。
为尝试解决上述问题,我们在多个项目上进行过性能测试,使用过的方法主要分成三类。
| 方案 | 具体方式 | 优点 | 缺点 | |
| 人为模拟请求 | 自己写代码或者使用简单的工具如httpload等去模拟用户请求进行测试 | 操作简单,能快速的得到cpu、mem、 load、 qps等极限值。 | 缺少真实用户交互行为,缺乏真实性 | |
| copy线上流量 | 使用tcpcopy工具实时copy线上流量到某台机器 | 操作简单,是真实线上请求,且对线上服务压力无影响 | 需要准备一套跟线上机器配置、依赖一致的独立环境,同时如果是服用线上的环境的话,一些写操作的请求被copy会有问题 | |
| 线上流量切换 | 直接用线上的机器和环境,通过调整nginx配置参数,逐渐将要做压测的机器的权重增加,然后观察该机器各个指标性能 | 真实生产线流量,能把用户行为导向压测服务器,是最为真实的用户行为,能够把一些需要登陆,有用户交互行为的性能真实的反映出来 | 因为是用生产系统真实流量来模拟压测,无法得出最大值,如果阀值设置有误,也存在一定的风险。此外该性能测试也不能经常进行 |
尽管我们在性能测试上做过一些尝试,但还远远不够,存在以下不足。
3.1 性能测试指标和标准尚未完全确立
不同服务测试指标应该不同,相应的标准也不同,例如接入层服务和后端服务指标是不同的。如果我们能为各个服务制定类似如下的标准,以后再进行性能测试就有了参考依据。 随着服务的发展,这些标准也会随之相应改动,要求会越来越严格。
|
判断指标 |
不通过的标准 |
|
超时概率 |
大于万分之一 |
|
错误概率 |
大于万分之一 |
|
平均响应时间 |
超过100ms |
|
0.99响应时间 |
超过200ms |
|
qpm(每分钟处理的请求量) |
小于2w |
|
qpm波动范围(标准差) |
正负3 |
|
cpu使用率 |
平均每核超过75% |
|
负载(load) |
平均每核超过1.5 |
|
jvm内存使用率 |
大于80% |
|
gc平均时间 |
超过1s |
|
fullgc频率 |
频率高于半小时一次 |
|
... |
...
|
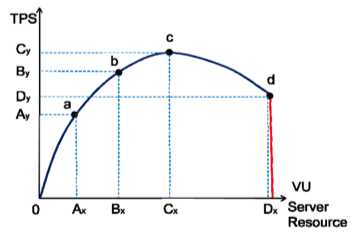
图1 淘宝性能测试曲线(a点:性能期望值;b点:高于期望,系统资源处于临界点;c点:高于期望,拐点;d点:超过负载,系统崩溃)
根据上述压力变化模型,淘宝网将性能测试分成狭义的4种类型:
a)性能测试:a点到b点之间的系统性能
定义:狭义的性能测试,是指以性能预期目标为前提,对系统不断施加压力,验证系统在资源可接受范围内,是否能达到性能预期。
b)负载测试 :b点的系统性能
定义:狭义的负载测试,是指对系统不断地增加压力或增加一定压力下的持续时间,直到系统的某项或多项性能指标达到极限,例如某种资源已经达到饱和状态等。
c)压力测试:b点到d点之间
定义:狭义的压力测试,是指超过安全负载的情况下,对系统不断施加压力,是通过确定一个系统的瓶颈或不能接收用户请求的性能点,来获得系统能提供的最大服务级别的测试
d)稳定性测试:a点到b点之间
定义:狭义的稳定性测试,是指被测试系统在特定硬件、软件、网络环境条件下,给系统加载一定业务压力,使系统运行一段较长时间,以此检测系统是否稳定,一般稳定性测试时间为n*12小时
我们现在的性能测试还没有那么全面,比如没有进行长时间的稳定性测试,长时间的测试执行可导致程序发生由于内存泄露引起的失败,揭示程序中的隐含的问题或冲突。
线上流量切换方法不能经常执行,copy线上流量目前只能将所有(包括读和写)流量拷贝过来,而自己写程序模拟用户请求又缺乏真实性。一种思路是自己实现测试程序将前一天的请求重新跑一遍,其核心在于控制请求频率,使其与之前请求频率曲线一致,从而达到近似模拟的目的。
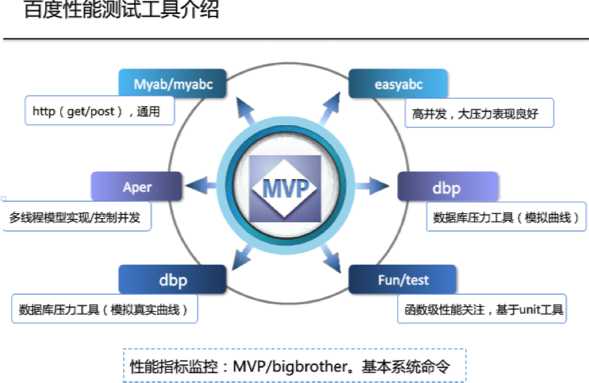
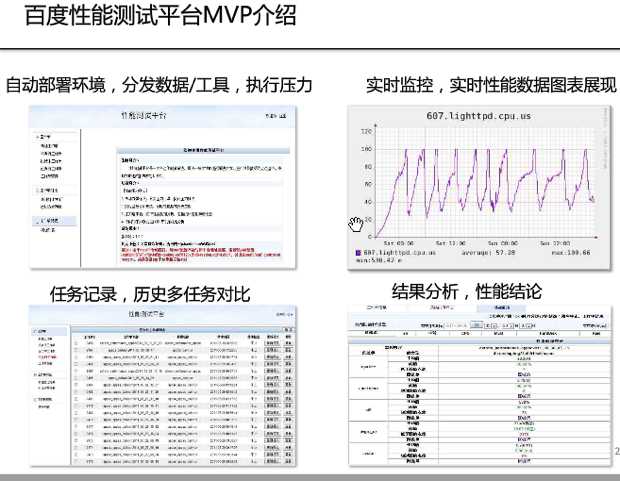
例如百度有个性能测试平台,有此平台后,可以方便地进行性能测试。其可以用于指导程序开发,使得在开发过程不仅关注功能,也关注性能,此外,性能测试纳入持续集成,每天出报表,每天都能知道自己服务的处理能力。
标签:
原文地址:http://www.cnblogs.com/LBSer/p/4605345.html