标签:
这一节讲的是overfitting,听完对overfitting的理解比以前深刻多了。
先介绍了过拟合,后果就是Ein很小,而Eout很大。然后分别分析了造成过拟合的原因。
首先是对横型复杂度对过拟合的探讨。模型越复杂,越可能产生过拟合。然后给出了造成这一结果的原因:样本数量太小。这是在有noise的情况下,
那么假如没有noise呢?
用下面两幅图来表明各个参数的影响:
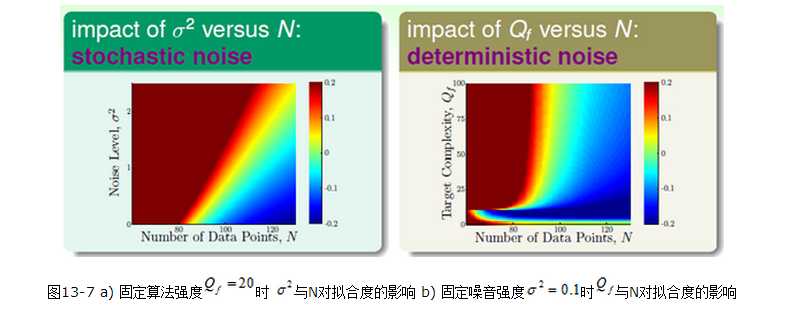
从图中可看出,noise和模型复杂度都会对过拟合产生影响。其中需要注意的是右图左下角的那块区域。采用了复杂的模型
就相当于产生了noise,这被称为deterministic noise(比较难理解),与之对应的是stochastic noise。总结过拟合的原因就是四个:
数据量N少,随机噪音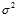 高,确定性噪音高,过量的VC维。
高,确定性噪音高,过量的VC维。
最后提出了解决过拟合的方法,包括数据清理/裁剪(data cleaning/pruning),数据提示(data hinting),正则化(regularization),确认(validation),并
以开车举例来说明这些方法的作用,后两种方法也是后两节课的内容。
data cleaning/pruning就是改正或删除错误的样本点,处理简单,但通常这样的样本点不易被发现。
data hinting就是通过产生虚拟样本来产生更多的样本数量
Coursera台大机器学习课程笔记12 -- Hazard of Overfitting
标签:
原文地址:http://www.cnblogs.com/573177885qq/p/4605677.html