标签:
目录
1.数据集选取
2.数据预处理
(1)数据清理
(2)数据集成
(3)数据归约
(4)数据变换和数据离散化
3.数据分析算法
4.分析总结改进
这学期提前选课学习了Data Mining,最近提交了论文已经彻底结了。想来想去还是写点东西记一下,假如以后能用上呢?仅供参考哈
参考书:《数据挖掘概念与技术》 Jiawei Han 等著
首先一些基本概念还是要了解一下的,数据挖掘是从大量数据中挖掘出有趣模式和知识的过程。数据源一般是数据库、数据仓库、Web等,得到的数据称为数据集(dataset)。其中数据仓库是data mining独有内容,是从多个数据源收集的信息存储库。按照William H.Inmon的说法,“数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理者的决策过程”。对比数据库的概念,“长期存储在计算机内、有组织的、可共享的大量数据的集合”(《数据库系统概论》(第四版)王珊等),可以分为两类,联机数据处理(Online Transaction Processing,OLTP)系统和联机分析处理(Online Analytical Processing,OLAP)系统。数据库属于前一个,数据仓库属于后一个,对比如下:
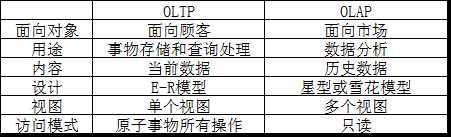
图1 OLTP和OLAP对比图
然后是重点:数据挖掘的一般过程。
一般数据集是已经存在的或者至少知道如何获得的(访问某个资料库,网上过滤抓取需要的数据,问卷调查手动收集等)。数据集的选取对数据挖掘模式是否有趣起决定作用。一般的数据挖掘模式有频繁模式,用于预测分析的分类和回归模式,聚类分析模式等,代表着数据挖掘的某种目的。最开始做实验的时候并不知道自己想要做什么(一般都是现有数据集或者想法,再有数据挖掘),于是查看一些常见的数据集网站(下附),寻找自己感兴趣的数据集,毕竟兴趣是最好的老师,兴趣有了,数据挖掘才能开心地做下去。
UCI机器学习和智能系统 https://archive.ics.uci.edu/ml/datasets/
kdd 2015预测学堂在线退课率 https://www.kddcup2015.com/information.html
数据挖掘 数据集下载搜集整理版 http://blog.sina.com.cn/s/blog_5c9288aa01014a56.html
选取了数据集之后,就开始对数据进行预处理使得数据能够为我们所用了。数据预处理提高数据质量:准确性、完整性和一致性,包括数据清理、数据集成、数据规约和数据变换方法。

图2数据预处理方法
忽略元祖
人工填写缺失值
使用属性的中心度量填充
给定同一类所有样本的属性均值或中位数填充
最可能的值填充
实体识别
冗余和相关分析(卡方检验,相关系数,协方差等,用spss比较方便)
维规约(小波变换和主成分分析,最常用)
数量规约(较小的数据替代原始数据)
数据压缩(有损无损两种,尤其对于图像视频等多媒体常用)
数据变换:光滑,属性构造,聚集,规范化,离散化和概念分层。

图3 数据规范化常见方法

图4 数据离散化
Eg:3-4-5规则,根据最高有效位个数分:
分为3类:最高有效位个数为 3 6 7 9
4 2 4 8
5 1 5
一般步骤:取min5%,max95%;根据3-4-5规则分段;根据两端调整分段
这个里面的内容就多而且复杂了,仅提出一些常见的供参考吧:
最经典的莫过于频繁模式挖掘了,对象为事物出现的次数。如著名的啤酒尿布。其中最典型的算法为Apriori算法,包括连接和剪枝。其中有置信度,支持度,频繁项集最小置信度阈值等重要概念,到相关分析中还有提升度,全置信度,Kulczy和余弦等判断标准和零不变度量考虑。个人觉得Uber就是看到了大量的零事物,从而开拓私家车市场并取得巨大成功的典型案例,也可以说换角度思考吧。
数据挖掘不仅仅用于挖掘频繁模式之间的联系,还常常用来分类和聚类。
分类的一般过程为用分类算法分析训练数据,然后用检验数据评估分类规则的准确率。常用的分类准则有决策树归纳、属性选择度量、树剪枝等,具体的常见算法有朴素贝叶斯(前提属性之间相互独立),贝叶斯信念网络,k-最近邻分类,遗传算法,神经网络,模糊集方法等。由此机器学习智能算法的强大可见一斑。
聚类由于是非指导学习,就相对麻烦些了。聚类的常见划分方法有k-均值和k-中心点,都是基于抽象距离的(实际度量为密度,网格等)。还有比较高级版本的,比如说基于概率的。聚类中有很多重要的概念,如划分准则,簇的离散型,相似性度量,聚类空间。个人觉得聚类其实就是自己按照一定的理解尝试去定制标准进行分类,然后检验自己的标准(尤其是离群点)。
算法弄完了,别忘了检验哦。
世界上没有任何东西生而完美,因而我们常常有很奇特的体验:过了一段时间后看自己以前做的事情,觉得自己以前怎么会做得那么二!
在数据挖掘中分析是很重要的,因此自己有任何的想法,即便自己当时觉得不好,也应该记下来,最后分析的时候再看看,假如又觉得有用呢。分析的对象主要是模型的优缺点(或者叫模型的评估),客观公正的评判自己的作品(能有高手帮忙最好啦)能清醒自己的认知。改进就是从分析当中来。一般而言,做这种带一定学术性的东西,确定好自己的基本想法和实践过程后去大型数据库(如中国知网)搜一搜,看看别人是如何处理相关事情的,对比一下。不管怎么说,高屋建瓴总比平地盖楼容易吧。
总结是对自己的肯定,别的不说,写完总结后看看前面自己做的事情,肯定还是有不小的自豪感的!总结的过程就是思考的过程,让自己后面的每一个作品都比现在的要好!
以我目前所学的粗浅知识,也就能写这么点了。。。
标签:
原文地址:http://www.cnblogs.com/codetker/p/4607442.html