标签:
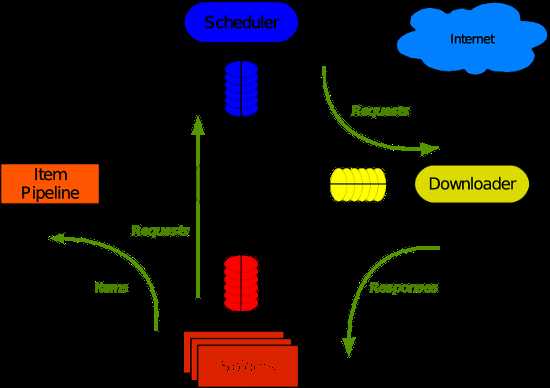
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下(注:图片来自互联网)
Scrapy主要包括了以下组件:
使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发。
【参考网页】
http://scrapy.org/
http://python.jobbole.com/?s=爬虫
爬虫框架 Scrapy
原文地址:http://www.cnblogs.com/renzimu/p/4608507.html