标签:
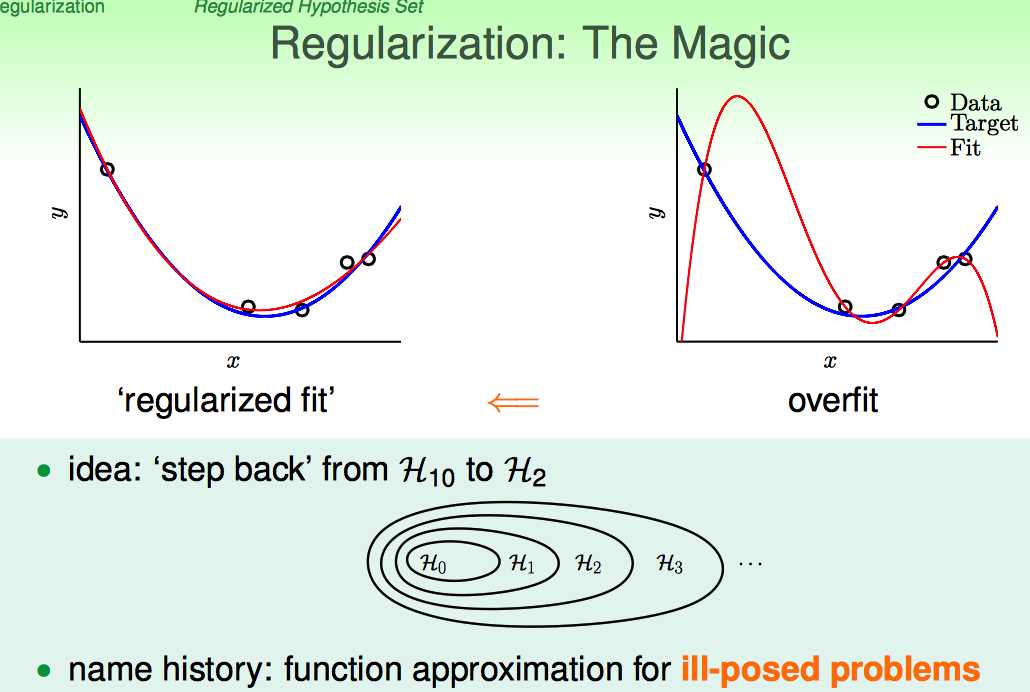
正则化的提出,是因为要解决overfitting的问题。
以Linear Regression为例:低次多项式拟合的效果可能会好于高次多项式拟合的效果。
这里回顾上上节nonlinear transform的课件:

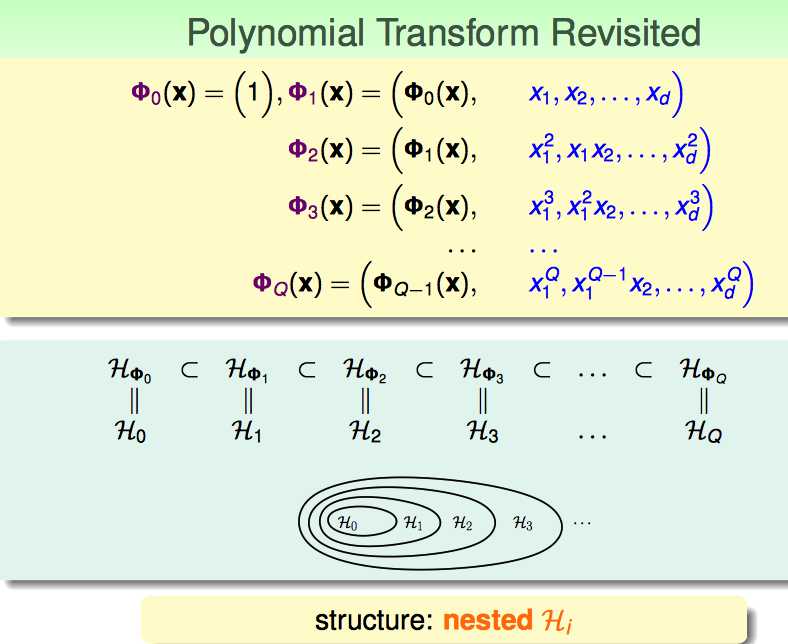
上面的内容说的是,多项式拟合这种的假设空间,是nested hypothesis;因此,能否想到用step back的方法(即,加一些constraints的方法把模型给退化回去呢?)

事实上,是可以通过加入constraint使得模型退化回去的;但是,再优化的过程中涉及到了“判断每个wq等于0的”问题,这种问题有点儿类似PLA的求解过程。
类比一下,这是一个NP-hard的问题,即不好求解。那么能不能换一种方式,让求解变得容易些呢?

让求解变得容易的方法是,改变约束条件。假设空间变成了regularized hypothesis Wreg。

上述内容,是通过几何角度分析:满足约束条件的最优解,Wreg应该与梯度的负方向一样。

这样optimal solution就可以求出来了;有个别名叫岭回归。
上述的过程,主要请出了前人的智慧“拉格朗日乘子”,目的是把有约束的优化问题转化为无约束的优化问题。
上面是用几何意义想出来的最有的Wreg,下面还原到初始的目标优化函数:

这里引出来了augmented error的概念;因为Ein是square的,W‘W也是正的,所以lambda也是设成是正的(由于lambda是正的,因此在优化求解的时候,可以保证W‘W不能太大)。用这个方法可以对模型复杂度进行惩罚,并且把有约束的问题转化为无约束的问题。
这里的关键在于如何选取lambda
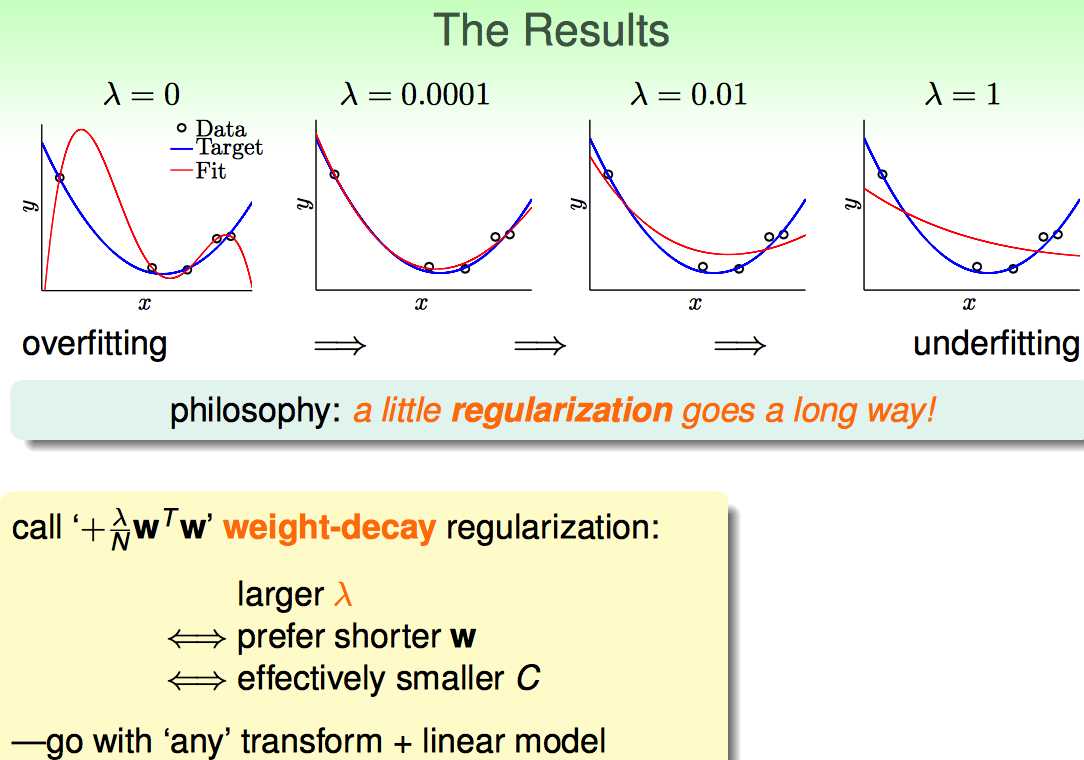
lambda越大,倾向于w越短;这种方式可以平移到很多线性模型中(只要是square error的);由于这种regularization的作用是缩短W的长度,因此也叫weight-decay regularization。
接下来,从更一般的角度讲解了regularization
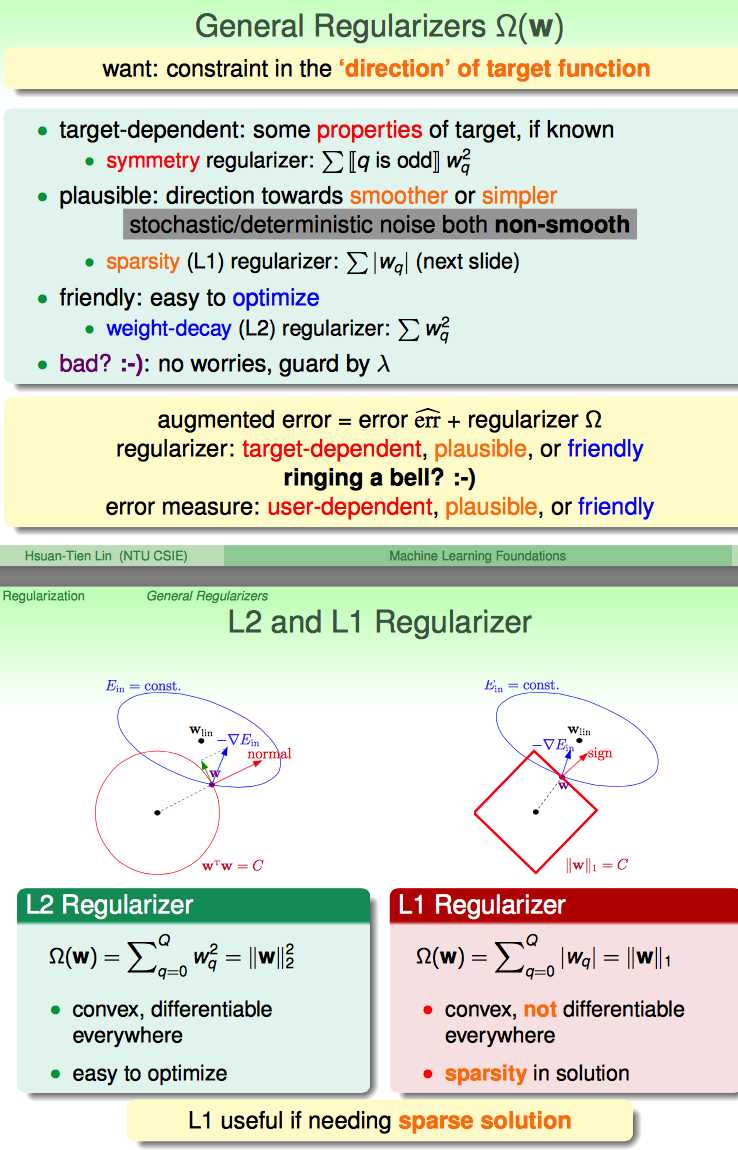
正则化分三种类型
(1)特殊目标驱动正则化:比如,缩减偶次项Wq²
(2)为了平滑( 尽量少够到一些stochastic/deterministic noise ):例如 L1 regularizer
(3)易于优化:如L2 regularizer
感觉这里对L1 L2 regularizer讲解的比较弱,搜了一篇日志(http://blog.csdn.net/zouxy09/article/details/24971995),对L1和L2 regularizer讲解的不错。
标签:
原文地址:http://www.cnblogs.com/xbf9xbf/p/4611475.html