标签:
1 package org.apache.hadoop.PageRank; 2 3 import java.util.ArrayList; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FileSystem; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 public class PageRank { 14 15 public static void run(){ 16 17 } 18 19 public static void main(String[] args) throws Exception { 20 double factor=0; 21 if(args.length>1){ 22 factor=Double.parseDouble(args[0]); 23 }else{ 24 factor=0.85; 25 } 26 String input="hdfs://10.107.8.110:9000/PageRank_input"; 27 String output="hdfs://10.107.8.110:9000/PageRank/output"; 28 ArrayList<String> pathList=new ArrayList<String>(); 29 for(int i=0;i<20;i++){ 30 Configuration conf = new Configuration(); 31 conf.set("num","4"); 32 conf.set("factor",String.valueOf(factor)); 33 Job job = Job.getInstance(conf, "PageRank"); 34 job.setJarByClass(org.apache.hadoop.PageRank.PageRank.class); 35 job.setMapperClass(MyMapper.class); 36 job.setReducerClass(MyReducer.class); 37 job.setOutputKeyClass(Text.class); 38 job.setOutputValueClass(Text.class); 39 FileInputFormat.setInputPaths(job, new Path(input)); 40 FileOutputFormat.setOutputPath(job, new Path(output)); 41 input=output; 42 pathList.add(output); 43 output=output+1; 44 45 System.out.println("the "+i+"th iterator is finished"); 46 job.waitForCompletion(true); 47 } 48 for(int i=0;i<pathList.size()-1;i++){ 49 Configuration conf=new Configuration(); 50 Path path=new Path(pathList.get(i)); 51 FileSystem fs=path.getFileSystem(conf); 52 fs.delete(path,true); 53 } 54 } 55 56 } 57 58 59 60 package org.apache.hadoop.PageRank; 61 62 import java.io.IOException; 63 import java.util.HashMap; 64 import java.util.Map; 65 66 67 import org.apache.hadoop.io.LongWritable; 68 import org.apache.hadoop.io.Text; 69 import org.apache.hadoop.mapreduce.Mapper; 70 71 public class MyMapper extends Mapper<LongWritable, Text, Text, Text> { 72 73 74 public void map(LongWritable ikey, Text ivalue, Context context) 75 throws IOException, InterruptedException { 76 String[] line=ivalue.toString().split(":"); 77 String content=line[1]; 78 int num=content.split(",").length; 79 String word=line[0].split(" ")[0]; 80 String alaph=line[0].split(" ")[1]; 81 context.write(new Text(word),new Text("content:"+content)); 82 for(String w:content.split(",")){ 83 context.write(new Text(w),new Text("link:"+word+" "+String.valueOf(1.0/num))); 84 context.write(new Text(w),new Text("alaph:"+word+" "+alaph)); 85 } 86 } 87 88 } 89 90 91 92 package org.apache.hadoop.PageRank; 93 94 import java.io.IOException; 95 import java.util.HashMap; 96 import java.util.Map; 97 98 import org.apache.hadoop.conf.Configuration; 99 import org.apache.hadoop.io.Text; 100 import org.apache.hadoop.mapreduce.Reducer; 101 102 public class MyReducer extends Reducer<Text, Text, Text, Text> { 103 104 public void reduce(Text _key, Iterable<Text> values, Context context) 105 throws IOException, InterruptedException { 106 // process values 107 Configuration conf=context.getConfiguration(); 108 double factor=Double.parseDouble(conf.get("factor")); 109 int num=Integer.parseInt(conf.get("num")); 110 111 Map<String,Double> alaph=new HashMap<String,Double>(); 112 Map<String,Double> link=new HashMap<String,Double>(); 113 114 String content=""; 115 for (Text val : values) { 116 String[] line=val.toString().split(":"); 117 if(line[0].compareTo("content")==0){ 118 content=line[1]; 119 }else { 120 String[] s=line[1].split(" "); 121 double d=Double.parseDouble(s[1]); 122 if(line[0].compareTo("alaph")==0){ 123 alaph.put(s[0],d); 124 }else if(line[0].compareTo("link")==0){ 125 link.put(s[0],d); 126 } 127 } 128 } 129 double sum=0; 130 for(Map.Entry<String,Double> entry:alaph.entrySet()){ 131 sum+=link.get(entry.getKey())*entry.getValue(); 132 } 133 134 System.out.println(" "); 135 System.out.println("sum is "+sum); 136 System.out.println(" "); 137 double result=factor*sum+(1-factor)/num; 138 context.write(_key,new Text(String.valueOf(result)+":"+content)); 139 140 } 141 142 }
def f(x): links=x[1][0] rank=x[1][1] n=len(links.split(",")) result=[] for s in links.split(","): result.append((s,rank*1.0/n)) return result file="hdfs://10.107.8.110:9000/spark_test/pagerank.txt" data=sc.textFile(file) link=data.map(lambda x:(x.split(":")[0],x.split(":")[1])) n=data.count() rank=link.mapValues(lambda x:1.0/n) for i in range(10): rank=link.join(rank).flatMap(f).reduceByKey(lambda x,y:x+y).mapValues(lambda x:0.15/n+0.85*x)
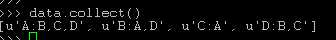

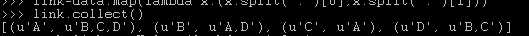

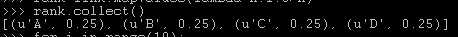



标签:
原文地址:http://www.cnblogs.com/sunrye/p/4611570.html