标签:
前言:
作为IT从业人员, 如果不是亲身经历, 对闰秒的认识. 或许只是一个美丽的彩蛋, 觉得好玩而已. 这次真切的感受, 震惊之余, 觉得难道不是人生的幸事吗?

科普:
先来絮叨一下, 原子钟时间和地球时间其实是有微小的差异. 为了同步, 故引入了闰秒, 当两者的差异超过+/-0.9秒时, 就把时间时钟向前/后拨动一秒.
人们一般把调整时间设定在当年的1月1号或7月1号的凌晨, 由于咱们这边属于东八区, 故时间的调整点为7月1号的8点, 更确切的讲是2015-07-01 07:59:60.
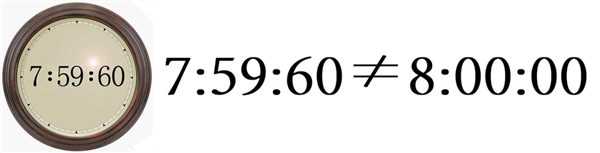
经历:
路人甲: "今天是建党节啊, 五毛万岁!!!!"
路人乙: "是呀, 美好的一天, oh yeah".
原以为一如平常, 突然同事提醒我, 在某台机器上, 我的服务进程的CPU突然蹦到了300+.
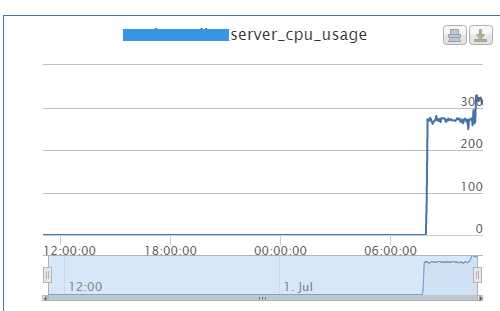
对比了集群的其他机器, 唯有这台机器是异常的. 最近也没升级, 也没流量的陡增.这是啥情况?
后来得知, 系统部在8点有操作, 这样在时间点上就吻合了? 我们猜测和闰秒有关系, 那为何其他机器正常, 这太机器不正常.是否和内核有关系?
对比后发现, 这台机器的内核版本比较旧,时间同步后就正常了.

原因分析:
在某些linux 2.6.x内核版本上, 有些不合理的处理.
在通过CPU硬件晶振的数据获得当前精确时间时,由于闰秒的关系,这个时间和操作系统维持的墙上时间(Wall Time,也就是显示给用户看的时间)不一致,形成类似死循环的状态, 进而导致CPU暴涨.
The issue identified after the leap second can cause applications that are using FUTEXes to consume 100% of CPU. The issue is present in all Linux kernel versions >= 2.6.22, therefor affecting SLE 11 SP1 and later releases. The issue is caused by the FUTEX subsystem timing getting de-synchronized causing FUTEX calls to return based on a time-out, these calls are looping to look for events which causes 100% CPU consumption. We recommend to apply the workaround even if everything is currently alright with the system.
解决方案:
最简单的方法, 就是重启服务器.
当然对于线上服务而言, 这是不可取的方法.
实际上, 通过时间同步命令, 即可简单解决:
date -s "$(LC_ALL=C date)"
具体可参考文章: "Leap second issues - June 30, 2012".
总结:
虽然具体的产生原因, 不是特别的理解. 但算是体验了一把闰秒的惊人"威力", 长了见识. 对线上的敬畏之心, 更深了一步.
写在最后:
如果你觉得这篇文章对你有帮助, 请小小打赏下. 其实我想试试, 看看写博客能否给自己带来一点小小的收益. 无论多少, 都是对楼主一种由衷的肯定.

标签:
原文地址:http://www.cnblogs.com/mumuxinfei/p/4616858.html