标签:
串是由零个或多个字符组成的有限序列,又名叫字符串
串中的字符数目n称为串的长度
零个字符的串称为空串

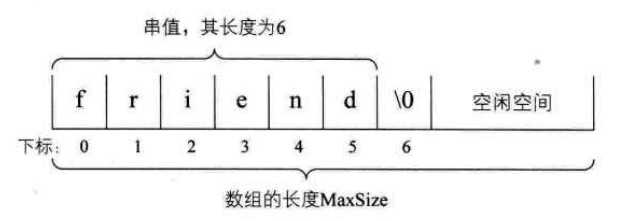
一个结点可以存储一个字符也可以考虑存储多个字符,最后一个结点若是未被占满时,可以用#或其它非串值字符补全

对主串的每一个字符作为子串开头,与要匹配的字符进行匹配。对主串做大循环,每个字符开头做T的长度的小循环,直到匹配成功或全部遍历完成为止。
时间复杂度为O(n+m)
/* 返回子串T在主串S中第pos个字符之后的位置。若不存在,则函数返回值为0。 */ /* 其中,T非空,1≤pos≤StrLength(S)。 */ int Index(String S, String T, int pos) { int i = pos; /* i用于主串S中当前位置下标值,若pos不为1,则从pos位置开始匹配 */ int j = 1; /* j用于子串T中当前位置下标值 */ while (i <= S[0] && j <= T[0]) /* 若i小于S的长度并且j小于T的长度时,循环继续 */ { if (S[i] == T[j]) /* 两字母相等则继续 */ { ++i; ++j; } else /* 指针后退重新开始匹配 */ { i = i-j+2; /* i退回到上次匹配首位的下一位 */ j = 1; /* j退回到子串T的首位 */ } } if (j > T[0]) return i-T[0]; else return 0; }
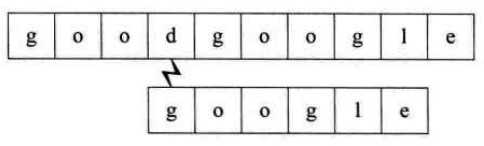
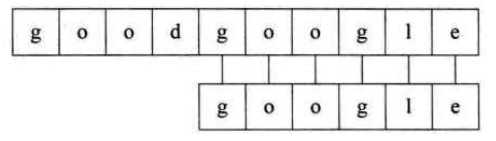
利用上面的算法,假设我们要从主串goodgoogle中找到google,则需要下面的步骤
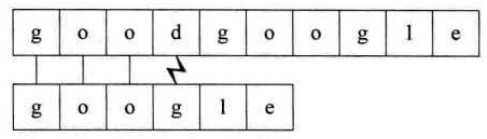
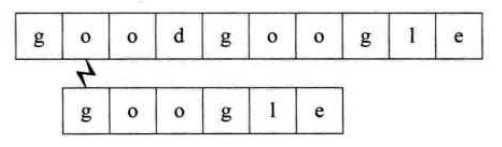
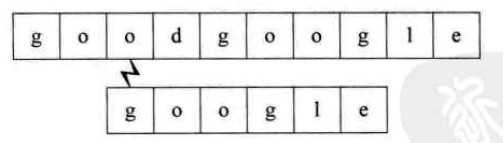
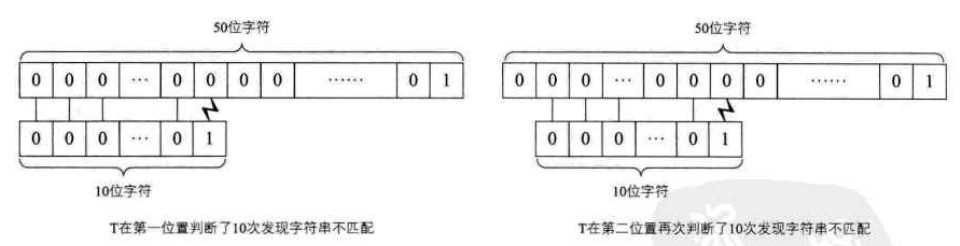
想想如果我们要在主串S="00000000000000000000000000000000000000000000000000001",而要匹配的子串T=“0000000001”
也就是说T串需要在S串的前40个位置都需要判断10次并得到不匹配的结论,直到第41位才全部匹配相等
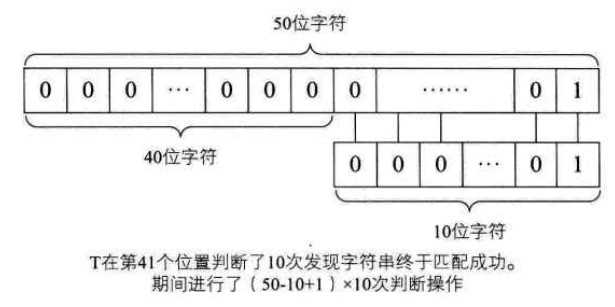
因此最坏的情况的时间复杂度为O(((n-m)+1)*m)
如果主串S="abcdefgab",要匹配的子串T="abcdex"
如果用朴素算法的话,则匹配的流程图如下所示:
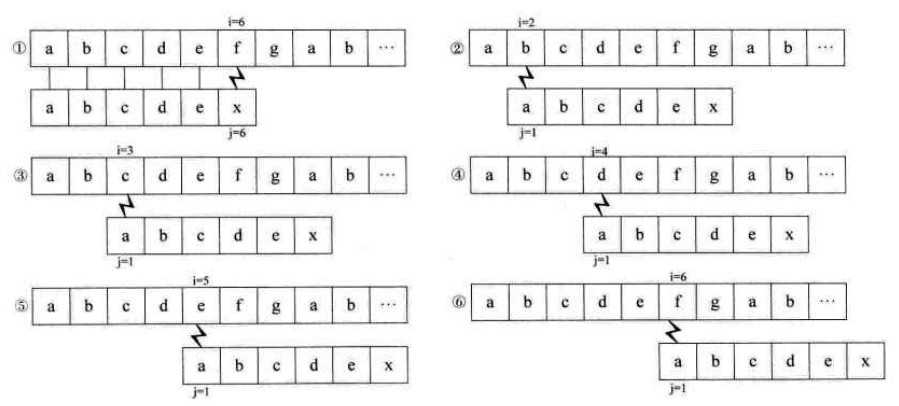
细想一下,子串T中“abcdex” 首字母a与后面的串“bcdex”中的任意一个字符都不相等,既然a不与自己后面的子串中任何一个字符相等,那么对于上图1来说,前五个字符分别相等,意味着子串T的首字符a不可能与s串的第2位到第5位的字符相等,也就是说在上图中2、3、4、5的判断都是多余的。
如果子串T中有与首字符相等的字符,也是可以省略一部分不必要的判断步骤的。
我们把T串各个位置的j值的变化定义为一个数组next,那么next的长度就是T串的长度
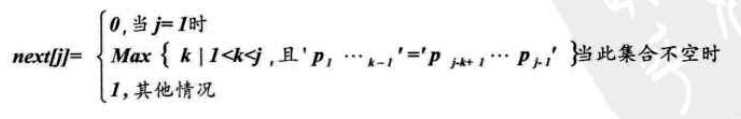
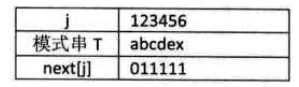
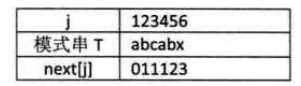


/* 通过计算返回子串T的next数组。 */ void get_next(String T, int *next) { int i,j; i=1; j=0; next[1]=0; while (i<T[0]) /* 此处T[0]表示串T的长度 */ { if(j==0 || T[i]== T[j]) /* T[i]表示后缀的单个字符,T[j]表示前缀的单个字符 */ { ++i; ++j; next[i] = j; } else j= next[j]; /* 若字符不相同,则j值回溯 */ } } /* 返回子串T在主串S中第pos个字符之后的位置。若不存在,则函数返回值为0。 */ /* T非空,1≤pos≤StrLength(S)。 */ int Index_KMP(String S, String T, int pos) { int i = pos; /* i用于主串S中当前位置下标值,若pos不为1,则从pos位置开始匹配 */ int j = 1; /* j用于子串T中当前位置下标值 */ int next[255]; /* 定义一next数组 */ get_next(T, next); /* 对串T作分析,得到next数组 */ while (i <= S[0] && j <= T[0]) /* 若i小于S的长度并且j小于T的长度时,循环继续 */ { if (j==0 || S[i] == T[j]) /* 两字母相等则继续,与朴素算法增加了j=0判断 */ { ++i; ++j; } else /* 指针后退重新开始匹配 */ j = next[j];/* j退回合适的位置,i值不变 */ } if (j > T[0]) return i-T[0]; else return 0; }
上面get_next的时间复杂度为O(m),而index_KMP中while循环的时间复杂度为O(n),所以整个算法的时间复杂度为O(n+m)
比如主串S="aaaabcde",子串T="aaaaax",那么next数组值分别为012345
利用KMP算法比较的过程如下图所示:
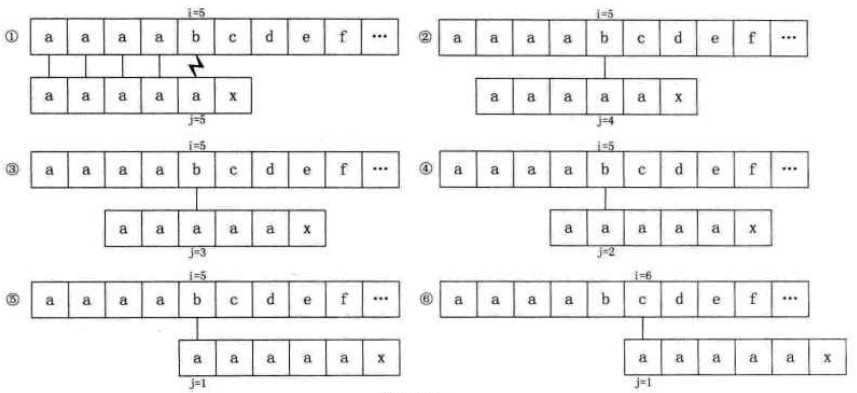
当i=5,j=5时,b与a不相等,如上图1
j=next[5]=4,如上图2,b与第四个位置的a依然不等
j=next[4]=3,如上图3,...
细想一下,2、3、4、5步骤都是多余的,因为T串的第二、三、四、五位置的字符都与首位a相等,那么可以利用首位的next[1]的值去取代与它相等的字符后续的next[j]的值
/* 求模式串T的next函数修正值并存入数组nextval */ void get_nextval(String T, int *nextval) { int i,j; i=1; j=0; nextval[1]=0; while (i<T[0]) /* 此处T[0]表示串T的长度 */ { if(j==0 || T[i]== T[j]) /* T[i]表示后缀的单个字符,T[j]表示前缀的单个字符 */ { ++i; ++j; if (T[i]!=T[j]) /* 若当前字符与前缀字符不同 */ nextval[i] = j; /* 则当前的j为nextval在i位置的值 */ else nextval[i] = nextval[j]; /* 如果与前缀字符相同,则将前缀字符的 */ /* nextval值赋值给nextval在i位置的值 */ } else j= nextval[j]; /* 若字符不相同,则j值回溯 */ } }

(具体分析图如下所示:
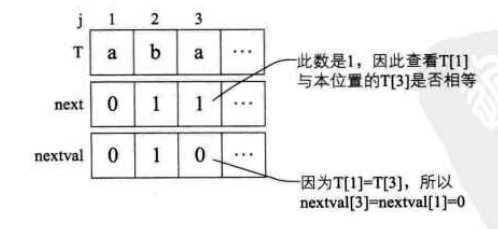
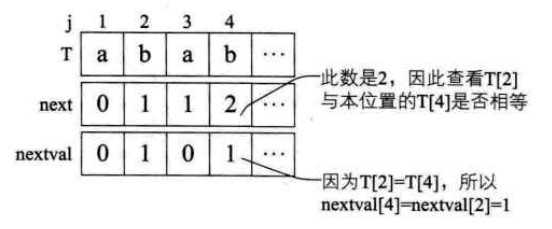 )
)
另外一个例子(看看你推导正确了没)

标签:
原文地址:http://www.cnblogs.com/liyunhua/p/4622938.html