标签:
基本想法:既不想像参数估计(最大似然,贝叶斯学习)那样需要假定特定的分布函数形式,又不想像非参数估计那样在最终生成的模型中带着所有的训练样本。
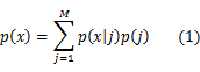
注意理解这个式子:p(j)是样本概率由第j个组分得到的概率,式(1)中也就是对联合分布求和得到了边缘分布。
P(j)的取值需要满足概率函数的约束:
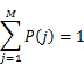
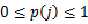
同理,条件概率密度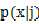 需要满足:
需要满足: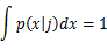
这个表达式(1)有意跟我们常见的分类问题中的表达式很相像,那时的表达式是这样的: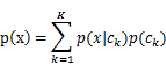
我们一般针对每一类去确定一个特定的概率密度函数形式,然后得到最终的结果。但是有时候我们得到的数据可能不完整,缺少类标签,所以不知道p(x)由哪几个成分组成,于是出现了式(1)那种存粹靠猜的做法:就假设M种组分,各用一个概率密度函数组合成x的分布!这是思路的来源。但随后用法就可以扩展了,其实可以针对每一类用一个混合分布模型,理论上可以证明,通过组合足够多的概率密度分布,可以精确接近任何一种分布!
混合模型的求解是基于最大似然概率的。
1、最大似然
具体实施先要假设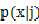 的形式,这里假设都是高斯函数,且协方差矩阵
的形式,这里假设都是高斯函数,且协方差矩阵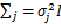 ,所以:
,所以:
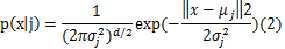
似然函数表达如下:
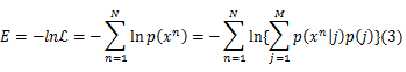
这里需优化的参数有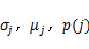
考虑到p(j)是一个受约束的参数,求导过程不易处理,于是用softmax函数将其约束表达出来:
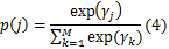
于是需优化的参数变成了:
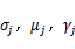
对公式(3)求偏导可以得到参数的最优值(偏导为零)如下:
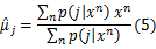
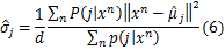
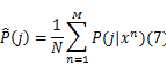
注意(5) (6) (7)式中都出现的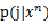 可以利用贝叶斯公式计算:
可以利用贝叶斯公式计算:
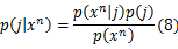
由(8)式可以计算(5)(6)(7),但它又要借助前面的结果,最优参数值的计算中出现了环!如果将旧值用于左边,则求出来的新值将是已有条件下的最优值,也就是比旧值更优!这就是迭代更新的策略了!
2、EM算法
依据前面的式(3),可以得到:
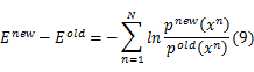
根据混合模型的公式(1),我们将式(9)化为:
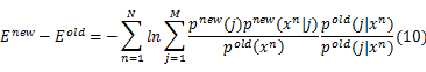
又由Jensen不等式,给定序列{ },满足
},满足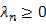 且
且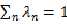 ,则下面不等式恒成立:
,则下面不等式恒成立:
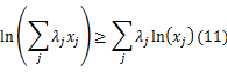
从而可以得到:
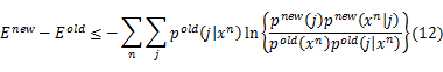
因为公式中的旧值总是已知的,可以除去公式中与新值完全无关的项,得到:
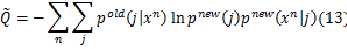
问题变成了在迭代过程中求解 的最小值,这里为了表达
的最小值,这里为了表达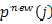 作为分布函数所受到的约束,利用拉格朗日乘子法,将目标函数重新表述为:
作为分布函数所受到的约束,利用拉格朗日乘子法,将目标函数重新表述为:
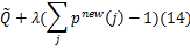
利用偏导等于0,简单的变换可以直接求得拉格朗日乘子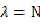
对于高斯混合模型的情况,带入公式可以求得具体形式。
事实上,这只是EM算法的一种特例。EM算法的提出,最初针对的是不完整的数据集。这里缺失的信息就是某个特性数据x由哪一个组分生成的信息!
标签:
原文地址:http://www.cnblogs.com/hustxujinkang/p/4629598.html