标签:
大家好,欢迎回到性能调优培训。在上2个星期,你已经学过了统计信息,它们为什么重要,还有在SQL Server里它们是什么样的。在这期性能调优培训里我想谈下当前参数预估含有的局限性,还有如何应用不同新技术来克服这些局限。
上个星期你就看到,当执行计划被编译时,SQL Server使用直方图和密度向量来作参数预估。SQL Server这里使用的模型是个静态的,它有很多的缺点和陷阱。在SQL Server 2014里这些情况会改变——下个星期我会详细讲解这些提升。
为了给你参数预估哪里有问题的具体例子,假设有下列2个表:Orders表和Country表。Orders表里的每条记录代表客户下的订单(像数据仓库情景里的事实表),那个表里通过外键约束指向Country表(它就像纬度表)。现在我们对这2个表进行一个来自UK的销售查询:
1 SELECT SalesAmount FROM Country 2 INNER JOIN Orders ON Country.ID = Orders.ID 3 WHERE Name = ‘UK‘
当你查看它的执行计划时,会发现SQL Server在参数预估上有个大问题。
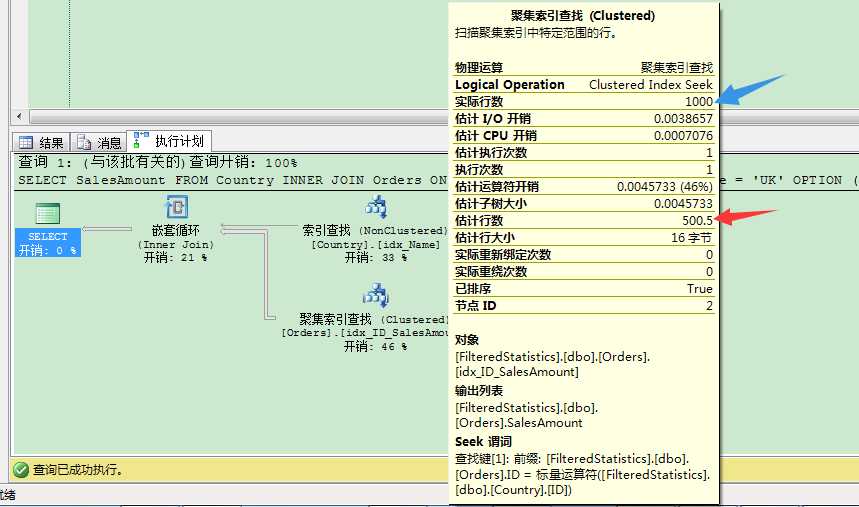
SQL Server估计行数是501,实际上聚集索引查找运算符的实际行数是1000。SQL Server这里使用idx_ID_SalesAmount统计信息对象的密度向量来做出那个预估:密度向量是0.5(在那列我们只有2个不同值),因此估计行数是501(1001 * 0.5)。你可以通过增加过滤统计信息对象来解决这个问题。这会给SQL Server更多关于数据分布本身的信息,也会帮助参数预估。
1 CREATE STATISTICS Country_UK ON Country(ID) 2 WHERE Name = ‘UK‘
当你现在再次看执行计划时,你会看到现在的估计行数和实际行数是一样了。关于这个问题的更多信息可以查看这个文章:使用过滤统计信息解决参数预估错误。
在SQL Server里对于当前的参数预估的另外一个问题出现在查询谓语是彼此相关的。来看下面的SQL查询:
1 SELECT * FROM Products 2 WHERE Company = ‘Microsoft‘ 3 AND Product = ‘iPhone‘
当我们常人来看这个查询时,你马上知道会有多少行返回:0!微软公司不可能卖苹果手机滴。当你对SQL Server执行这样的查询时,查询优化器会独立看每个查询谓语:
在第1步里,参数预估对谓语Company = ‘Microsoft‘完成。
在第2步里,查询优化器生成对另外谓语Product = ‘iPhone‘的参数预估。
最后2个预估相乘(multiplied by each other)生成最后的预估。当第1个谓语生成0.3的参数,第2个生成0.4的参数,最后的参数就是0.12(0.3 * 0.4)。查询优化器对每个谓语各自处理,而不考虑彼此关联。
对于这个特定问题,Paul White写了一篇非常有趣的文章,还有你如何影响SQL Server的查询优化器来生成更好性能的执行计划。
对于SQL Server里执行计划的准确性和高性能,统计信息和参数预估非常重要。遗憾的是它们的使用率也是有限的,尤其在一些边缘情况。通过这篇文章你看到你如何使用过滤统计信息帮助查询优化器生成更好的参数预估,还有如何处理SQL Server里的相关列问题。
在下星期的性能调优培训里,我们会进一步讨论新的参数预估,即SQL Server 2014的一部分,还有在哪个情形下,新的实现方法会给你更好的执行计划。请继续关注。
标签:
原文地址:http://www.cnblogs.com/woodytu/p/4631014.html