标签:
在《Kafka实战-Flume到Kafka》一文中给大家分享了Kafka的数据源生产,今天为大家介绍如何去实时消费Kafka中的数据。这里使用实时计算的模型——Storm。下面是今天分享的主要内容,如下所示:
接下来,我们开始分享今天的内容。
Kafka的数据消费,是由Storm去消费,通过KafkaSpout将数据输送到Storm,然后让Storm安装业务需求对接受的数据做实时处理,下面给大家介绍数据消费的流程图,如下图所示:
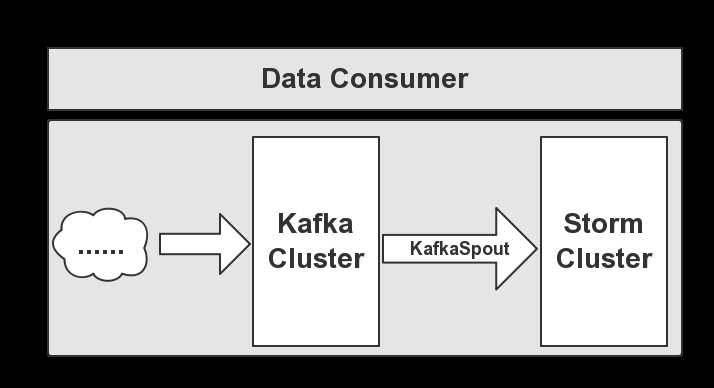
从图可以看出,Storm通过KafkaSpout获取Kafka集群中的数据,在经过Storm处理后,结果会被持久化到DB库中。
接着,我们使用Storm去计算,这里需要体检搭建部署好Storm集群,若是未搭建部署集群,大家可以参考我写的《Kafka实战-Storm Cluster》。这里就不多做赘述搭建的过程了,下面给大家介绍实现这部分的代码,关于KafkaSpout的代码如下所示:
package cn.hadoop.hdfs.storm; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import cn.hadoop.hdfs.conf.ConfigureAPI.KafkaProperties; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.IRichSpout; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; /** * @Date Jun 10, 2015 * * @Author dengjie * * @Note Data sources using KafkaSpout to consume Kafka */ public class KafkaSpout implements IRichSpout { /** * */ private static final long serialVersionUID = -7107773519958260350L; private static final Logger LOGGER = LoggerFactory.getLogger(KafkaSpout.class); SpoutOutputCollector collector; private ConsumerConnector consumer; private String topic; private static ConsumerConfig createConsumerConfig() { Properties props = new Properties(); props.put("zookeeper.connect", KafkaProperties.ZK); props.put("group.id", KafkaProperties.GROUP_ID); props.put("zookeeper.session.timeout.ms", "40000"); props.put("zookeeper.sync.time.ms", "200"); props.put("auto.commit.interval.ms", "1000"); return new ConsumerConfig(props); } public KafkaSpout(String topic) { this.topic = topic; } public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } public void close() { // TODO Auto-generated method stub } public void activate() { this.consumer = Consumer.createJavaConsumerConnector(createConsumerConfig()); Map<String, Integer> topickMap = new HashMap<String, Integer>(); topickMap.put(topic, new Integer(1)); Map<String, List<KafkaStream<byte[], byte[]>>> streamMap = consumer.createMessageStreams(topickMap); KafkaStream<byte[], byte[]> stream = streamMap.get(topic).get(0); ConsumerIterator<byte[], byte[]> it = stream.iterator(); while (it.hasNext()) { String value = new String(it.next().message()); LOGGER.info("(consumer)==>" + value); collector.emit(new Values(value), value); } } public void deactivate() { // TODO Auto-generated method stub } public void nextTuple() { // TODO Auto-generated method stub } public void ack(Object msgId) { // TODO Auto-generated method stub } public void fail(Object msgId) { // TODO Auto-generated method stub } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("KafkaSpout")); } public Map<String, Object> getComponentConfiguration() { // TODO Auto-generated method stub return null; } }
package cn.hadoop.hdfs.storm.client; import cn.hadoop.hdfs.storm.FileBlots; import cn.hadoop.hdfs.storm.KafkaSpout; import cn.hadoop.hdfs.storm.WordsCounterBlots; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; /** * @Date Jun 10, 2015 * * @Author dengjie * * @Note KafkaTopology Task */ public class KafkaTopology { public static void main(String[] args) { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("testGroup", new KafkaSpout("test")); builder.setBolt("file-blots", new FileBlots()).shuffleGrouping("testGroup"); builder.setBolt("words-counter", new WordsCounterBlots(), 2).fieldsGrouping("file-blots", new Fields("words")); Config config = new Config(); config.setDebug(true); if (args != null && args.length > 0) { // online commit Topology config.put(Config.NIMBUS_HOST, args[0]); config.setNumWorkers(3); try { StormSubmitter.submitTopologyWithProgressBar(KafkaTopology.class.getSimpleName(), config, builder.createTopology()); } catch (Exception e) { e.printStackTrace(); } } else { // Local commit jar LocalCluster local = new LocalCluster(); local.submitTopology("counter", config, builder.createTopology()); try { Thread.sleep(60000); } catch (InterruptedException e) { e.printStackTrace(); } local.shutdown(); } } }
首先,我们启动Kafka集群,目前未生产任何消息,如下图所示:
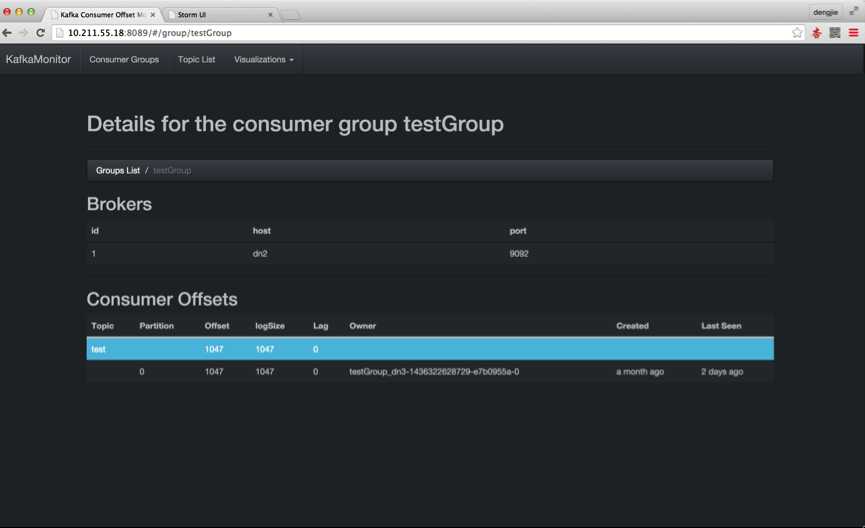
接下来,我们启动Flume集群,开始收集日志信息,将数据输送到Kafka集群,如下图所示:
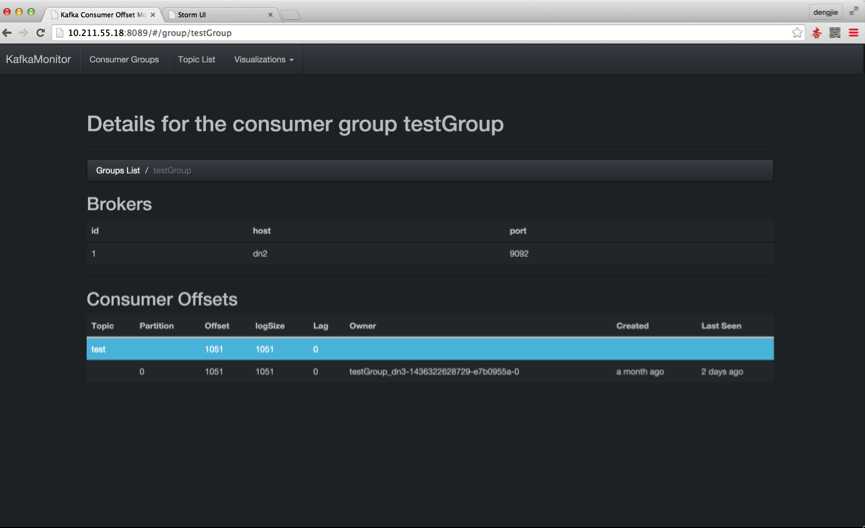
接下来,我们启动Storm UI来查看Storm提交的任务运行状况,如下图所示: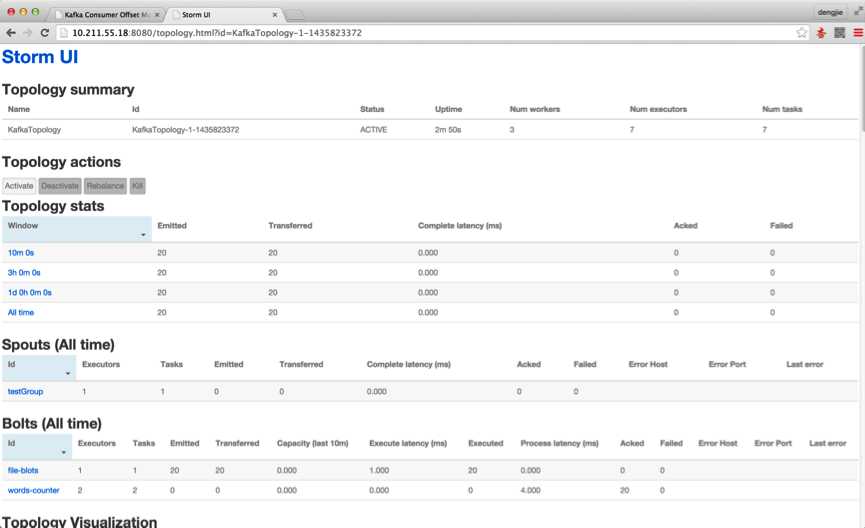
最后,将统计的结果持久化到Redis或者MySQL等DB中,结果如下图所示:
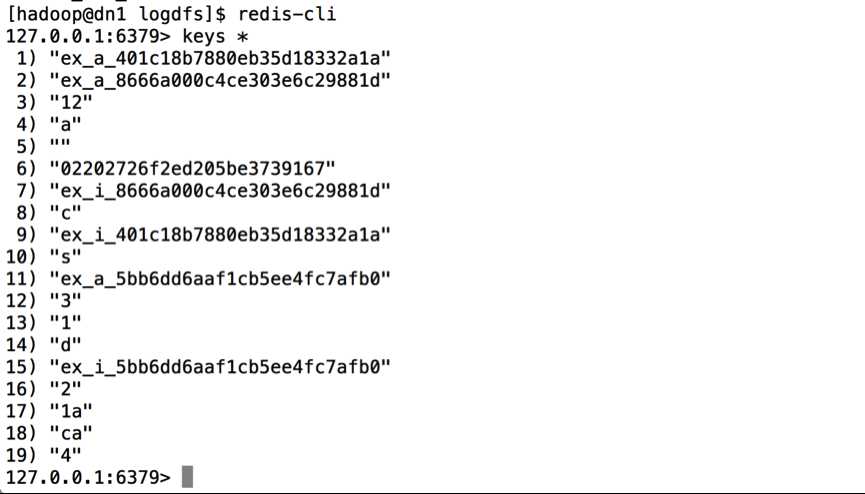
这里给大家分享了数据的消费流程,并且给出了持久化的结果预览图,关于持久化的细节,后面有单独有一篇博客会详细的讲述,给大家分享其中的过程,这里大家熟悉下流程,预览结果即可。
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
标签:
原文地址:http://www.cnblogs.com/smartloli/p/4632644.html