标签:
分布式缓存是指缓存部署在多个服务器组成的服务器集群中,以集群的方式提供缓存服务,其架构方式主要有两种,一种是以JBoss Cache为代表的需要同步更新的分布式缓存,一种是以Memchached为代表的互不通信的分布式缓存。
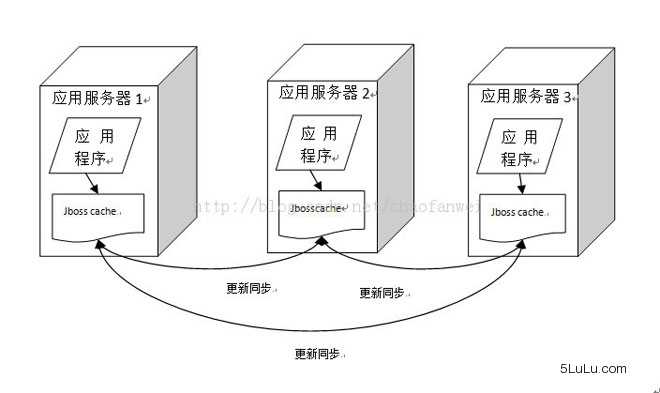
1、JBoss Cache
Jboss Cache的分布式缓存在集群中的每一台服务器都缓存相同的数据,当集群中的某台服务器的缓存数据更新时,会通知集群中的其他服务器更新或者清除缓存。JBoss Cache通常将应用程序和缓存部署在同一台服务器上,应用程序可以从本地快速获取缓存数据,但是这种方式带来的问题就是缓存数据的数量受限于单一服务器的内存空间,而且当集群规模较大时,缓存更新信息需要通知集群中其他机器同步更新,这中间对于服务器和网络带宽来说,付出的代价是很惊人的。因而这种方案大多见于一般的企业级应用中,在大型网站中很少用。
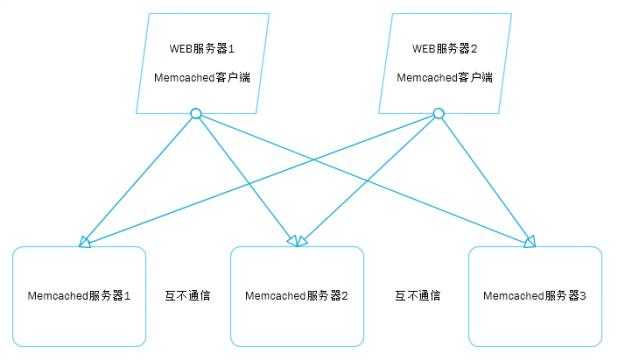
2、Memchached
Memchached曾一度是网站分布式缓存的代名词,被大量网站使用。其简单的设计、优异的性能、互不通信的服务器集群、海量数据可伸缩的架构令网站架构师们趋之若鹜。
远程通信设计需要考虑两方面的要素,一是通信协议,即选择TCP协议还是UDP协议,抑或是Http协议;一种是通信序列化协议,数据传输的两端,必须使用彼此可识别的数据序列化方式才能使通信得以完成,如XML、Json等文本序列化协议,或者是Google的Protobuffer等二进制序列化协议。Memecached使用TCP协议(UDP也支持)通信,其序列化协议是一套基于文本的自动以协议,非常简单,以一个命令关键字开头,后面是一组命令操作数。例如读取一个数据的命令协议是get<Key>。Memecached以后,很多NoSql产品都借鉴或直接使用了这套协议。
Memecached通信协议非常简单,只要支持该协议的客户端都可以和Memecached服务器通信,因此Memecached发展出了非常丰富的客户端程序,几乎支持所有主流网站的编程语言,因此在混合了多重编程语言的网站中,Memecached更是如鱼得水。
Memcached服务端通信模块式基于Libevent,一个支持事件触发的网络通信程序库。Libevent的设计和实现有许多值得改善的地方,但他在稳定的长连接方面的表现却正是Memecached所需要的。关于Libevent更详细的内容,我们会在后面专门讲Memecached的时候再详细说明。
在上一篇文章中我们说到,缓存就是将数据存储在访问速度相对较高的存储介质中,所以通产缓存都是存储在内存当中。那么缓存数据都存储在内存当中,必然会牵涉到一个问题,那就是内存的管理。而在内存管理中,令人最头疼的问题就是内存的碎片管理。操作系统、虚拟机垃圾回收在这方面想了很多办法:压缩、复制等。Memecached使用了一个非常简单的办法,那就是固定的内存空间分配。
Memecached将内存空间分成一组slab,每个slab又包含一组chunk,同一个slab里面的每个chunk的大小是固定的,拥有相同大小chunk的slab被组织在一起叫做slab_class.
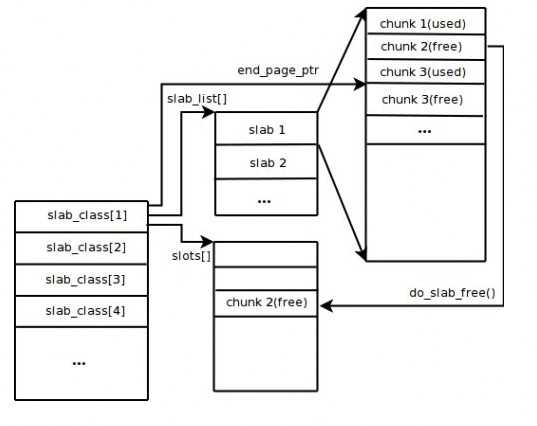
存储数据时根据数据的Size大小,寻找一个大于Size的最小的chunk将数据写入。这种内存管理的方式避免了内存碎片管理的问题,内存的分配和释放都以chunk为单位的。和其他缓存一样,memcached也是以LRU(最近最久未使用算法)算法释放最近最久未被访问的数据占有的空间,释放的chunk被标记为未使用,等待下一个合适的数据写入。
当然memecached的这种内存管理机制也会带来内存浪费的问题,数据只能存在一个比它大的chunk中,而一个chunk只能存一个数据,其他空间就浪费了。如果启动时参数配置不合理,浪费会更加惊人,发现没有缓存多少数据,空间就没了。
Memcached互不通信的特性是的Memecached从JBoss Cache、OSCache等众多分布式缓存产品中脱颖而出,满足网站对海量缓存数据的需求。其客户端路由算法一致性Hash更成为数据存储伸缩性架构设计的经典范式。事实上,正是集群中的分布式缓存服务器之间互不通信使得集群可以做到几乎无限制的线性伸缩,这也正是目前流行的许多大数据技术的基本架构特点。
虽然近些年许多NoSql产品层出不穷,在数据持久化、支持复杂数据结构,甚至性能方面有许多都优于Memecached,但Memecached由于其简单、稳定、专注的特点,仍然在分布式缓存领域占据重要地位。
对于Memecached相关技术知识,我们会在今后的文章中详细的讲解。
标签:
原文地址:http://www.cnblogs.com/Ron-Zheng/p/Distrubute.html