标签:
一、对于回归问题,基本目标是建模条件概率分布p(t|x)
利用最大似然的方式:negative logarithm of the likelihood
????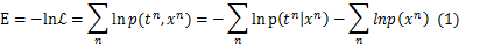
这个函数可以作为优化目标,其中的第二项与参数无关,在优化的时候不用计算在内。实际中所用到的各种不同的目标函数不过是对于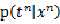 的形式做了具体的假设。
的形式做了具体的假设。
1.sum of squares error
这里假设输出矢量t的维度为K,则:
????????????????????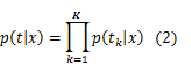
回归实际上就是希望得到K个输出关于输入的一个函数表达式 ,k=1,2…..K,而假设真值与预测值之间的误差是一个随机变量
,k=1,2…..K,而假设真值与预测值之间的误差是一个随机变量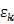 ,k=1,2…K
,k=1,2…K
????????????????????????????????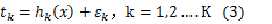
如果我们把这K个随机变量进一步假设为服从0均值,具有统一方差 的高斯分布,
的高斯分布,
则:
????????????????????????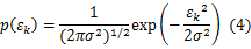
注意: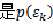 而不是
而不是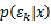 是因为我们认为
是因为我们认为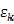 的分布独立于x!,同时,也一般把K个随机变量
的分布独立于x!,同时,也一般把K个随机变量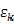 认为服从同一分布,也就是
认为服从同一分布,也就是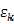 也独立于k。
也独立于k。
注意理解公式(4),误差服从高斯分布,则说明给定输入x,实际可能出现的tk值总在预测值上下浮动,也就是条件概率满足下面公式????????????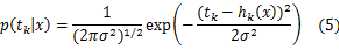
更形象的示例且看下图,图中的点就是我们的训练数据,而中间那条线就是我们的预测函数!对于某一个x,预测函数总能得到一个值,但是实际在训练数据中总有很多与同一个x对应的点,他们都在预测函数上下浮动,浮动的距离服从高斯分布!
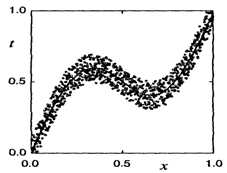
对于训练过程来说
????
?
????????????????????????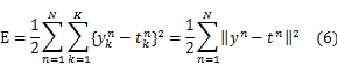
????由这个形式还有一种类似的root-mean-square(RMS) error:
????????????????????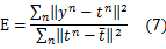
这种方式求出来的错误并不随数据规模而增长。
2、平方误差函数对于神经网络结果的解释
????如果我们把平方误差函数作为神经网络的目标函数去优化参数,则得到结果将是:
????????????????????????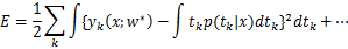
省略号之后的项与参数无关,由此可以得知,如果我们使用梯度下降法之类的优化方法,或者直接利用偏导为0,最终必然接近如下结果: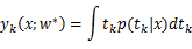
????换句话说,我们把目标函数形式化简之后,发现,最终优化得到的参数必然使得生成函数中y为x处t值的平均!
3、Modeling conditional distribution
????平方误差函数中做的关于高斯分布的假设太强,于是寻求一种更普适的方式建模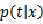 ,这里也就是利用高斯混合模型来建模误差分布!
,这里也就是利用高斯混合模型来建模误差分布!
?
?
?
?
二、对于分类问题,方式是建模后验概率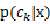
1、Sum of squares for classification
????套用前面回归问题的方式,如果采用最小平方和的方式,神经网络的网络输出:
????????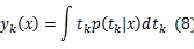
?
假设总共有C类,则总共有C个输出单元,每次输入一个x,与x所属的类对应的输出单元为1,其它输出单元为0
????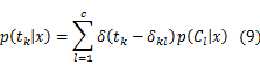
对于公式(8) 的理解,首先要明确,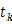 依据训练样本中x的类标签来取值,只能为0或1,
依据训练样本中x的类标签来取值,只能为0或1,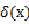 是指单位冲击函数,在0处取1,在其他地方都是取0。
是指单位冲击函数,在0处取1,在其他地方都是取0。
可分情况如下:
????当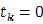 时,只要x不属于第k类就行
时,只要x不属于第k类就行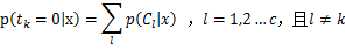
当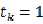 时,只在x属于第k类是成立
时,只在x属于第k类是成立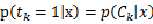
将式(9)代入公式(8),得到:
????????????????????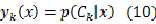
?
此时网络输出的含义就变成了对后验概率的建模!
反思一下:平方误差函数的导出基于两点:最大似然概率,误差服从高斯分布!,这对于分类问题却并不是最合适的!因为分类问题的目标输出都是0,1,完全不会是高斯分布!前面的回归问题,在我们假设成立的前提下,得到的模型能保证是训练数据集似然概率最大。但是这样来看分类问题,由于假设基本不可能,所以导出的模型没法从理论上保证使得训练数据集的似然概率最大。
?
2、互信息量的解释方法
????现在重新思考之前的方式,我们先是最大似然为目标,然后假设了误差为高斯分布,导出平方误差函数,最后使得只要基于平方误差函数去优化,得到的模型就会导出最大似然概率最大。
????先确立一个目标:使得输出代表后验概率!
????使输出代表后验概率的方法来自于线性判别过程,最初的线性判别函数是这样的:
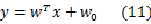
对于两类问题,现在我们考虑后验概率:
????????????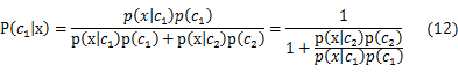
?
假设:????????????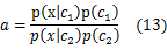
则:
????????????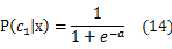
式(14)的右边就是我们熟悉的sigmoid函数。
现在的想法就是,能不能使得输出y具有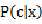 的语义??也就是如何使得y = sigmoid(a),最自然的想法是,如果a能像式(11)那样由输入线性表示,问题也就解决了。庆幸的是,对于类条件概率分布为高斯函数的时候,这一结论是很好证明的,而且可以推广至更普遍的指数族分布函数。也就是说sigmoid函数可以在二分类问题中,将普通的线性判决函数的输出转换成具有后验概率语义的输出,结果不会变(sigmoid函数是单调递增函数)。
的语义??也就是如何使得y = sigmoid(a),最自然的想法是,如果a能像式(11)那样由输入线性表示,问题也就解决了。庆幸的是,对于类条件概率分布为高斯函数的时候,这一结论是很好证明的,而且可以推广至更普遍的指数族分布函数。也就是说sigmoid函数可以在二分类问题中,将普通的线性判决函数的输出转换成具有后验概率语义的输出,结果不会变(sigmoid函数是单调递增函数)。
????在多类问题中与之对应的是softmax函数。
?
????一旦输出具有了后验概率的语义,则最大似然的表示变得极其简单,也就得出了所谓的
Negative-log-likelihood的损失函数形式!
反思:也就是说分类问题,要使得输出具有后验概率语义,进而套用Negative-log-likelihood损失函数,必须使用特定的activation function(两类是sigmoid,多类是softmax)。


?
?
?
标签:
原文地址:http://www.cnblogs.com/hustxujinkang/p/4637526.html