标签:
第一节:集合框架
一、集合类的由来:
对象用于封装特有数据,对象多了需要存储;如果对象的个数不确定,就使用集合容器进行存储。
二、集合类特点:
1. 用于存储对象的容器。
2. 长度是可变的。
3. 不可以存储基本数据类型值。
集合容器因为内部的数据结构不同,有多种具体容器。
不断的向上抽取,就形成了集合框架。
三、数组和集合类同是容器,有何不同?
数组虽然也可以存储对象,但长度是固定的;集合长度是可变的。
数组中可以存储基本数据类型,集合只能存储对象。
第二节 Collection
Collection接口位于框架顶层:
Collection的常见方法:
1、添加:
boolean add(Object obj);
boolean addAll(Collection coll);
2、删除:
boolean remove(Object obj);
boolean removeAll(Collection coll);
void clear();
3、判断:
boolean contains(Object obj);
boolean containsAll(Collection coll);
boolean isEmpty();判断集合中是否有元素。
4、获取:
int size();
Iterator iterator();
取出元素的方式:迭代器。
该对象必须依赖于具体容器,因为每一个容器的数据结构都不同,所以该迭代器对象是在容器中进行内部实现的,也就是iterator方法在每个容器中的实现方式是不同的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,也就是iterator方法。
Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
5、其他:
boolean retainAll(Collection coll);取交集
Object toArray();将集合转成数组
import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; public class IteratorDemo{ public static void main(String[] args){ Collection coll = new ArrayList(); coll.add( "abc1"); coll.add( "abc2"); coll.add( "abc3"); coll.add( "abc4"); System.out.println(coll); //使用了Collection中的iterator()方法。调用集合中的迭代器方法,是为了获取集合中的迭代器对象。 Iterator it1 = coll.iterator(); while(it1.hasNext()){ System.out.println(it1.next()); } //for循环结束,Iterator变量内存释放,更高效 for(Iterator it2 = coll.iterator();it2.hasNext();){ System.out.println(it2.next()); } } }
第三节 List
List:元素是有序的,元素可以重复。因为该集合体系有索引。
|--ArrayList:底层的数据结构使用的是数组结构。特点:查询速度很快。但是增删稍慢。线程不同步。
|--LinkedList:底层使用的是链表数据结构。特点:增删速度很快,查询稍慢。
|--Vector:底层是数组数据结构。线程同步。被ArrayList替代了。
特有方法:
1、增
addFirst();
addLast();
2、获取
//获取元素,但不删除元素。如果集合中没有元素,会出现NoSuchElementException
getFirst();
getLast();
3、删
//获取元素,并删除元素。如果集合中没有元素,会出现NoSuchElementException
removeFirst();
removeLast();
在JDK1.6以后,出现了替代方法。
1、增
offFirst();
offLast();
2、获取
//获取元素,但是不删除。如果集合中没有元素,会返回null。
peekFirst();
peekLast();
3、删
//获取元素,并删除元素。如果集合中没有元素,会返回null。
pollFirst();
pollLast();
示例:
import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class ListDemo{ public static void main(String[] args){ List list = new ArrayList(); list.add( "abc1"); list.add( "abc2"); list.add( "abc3"); System.out.println( "list:" + list); Iterator it = list.iterator(); while(it.hasNext()){ Object obj = it.next(); if(obj.equals("abc2" )){ list.add( "abc9"); } else{ System.out.println( "next:" + obj); } System.out.println(list); } } }
结果:

注意: 在迭代器过程中,不要使用集合操作元素,容易出现异常:java.util.ConcurrentModificationException。
可以使用Iterator接口的子接口ListIterator来完成在迭代中对元素进行更多的操作。
import java.util.ArrayList; import java.util.List; import java.util.ListIterator; public class ListDemo{ public static void main(String[] args){ List list = new ArrayList(); list.add( "abc1"); list.add( "abc2"); list.add( "abc3"); System.out.println( "list:" + list); ListIterator it = list.listIterator(); //获取列表迭代器对象 //它可以实现在迭代过程中完成对元素的增删改查。 //注意:只有list集合具备该迭代功能。 while(it.hasNext()){ Object obj = it.next(); if(obj.equals("abc3" )){ it.add( "abc9"); } } System.out.println( "hasNext:" + it.hasNext()); System.out.println( "hasPrevious:" + it.hasPrevious()); while(it.hasPrevious()){ System.out.println( "previous:" + it.previous()); } System.out.println( "list:" + list); } }
/* 使用LinkedList模拟一个堆栈或者队列数据结构。 堆栈:先进后出 如同一个杯子。 队列:先进先出 First in First out FIFO 如同一个水管。 */ import java.util.*; class LinkedListTest { public static void main(String[] args) { LinkedList l=new LinkedList(); l.addFirst("java01"); l.addFirst("java02"); l.addFirst("java03"); l.addFirst("java04"); l.addFirst("java05"); //堆栈输出 //stack(l); //队列输出 queue(l); } //堆栈 public static void stack(LinkedList l) { while (!l.isEmpty()) { sop(l.removeFirst()); } } //队列 public static void queue(LinkedList l) { while(!l.isEmpty()) { sop(l.removeLast()); } } //输出 public static void sop(Object obj) { System.out.println(obj); } }
第四节 Set
一、概述
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
|--HashSet:底层数据结构是哈希表。线程不同步。 保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true。
|--TreeSet:可以对Set集合中的元素进行排序。默认按照字母的自然排序。底层数据结构是二叉树。保证元素唯一性的依据:compareTo方法return 0。
Set集合的功能和Collection是一致的。
二、HashSet
HashSet:线程不安全,存取速度快。
可以通过元素的两个方法,hashCode和equals来完成保证元素唯一性。如果元素的HashCode值相同,才会判断equals是否为true。如果元素的hashCode值不同,不会调用equals。
注意:HashSet对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashCode和equals方法。
示例:
/* 往hashSet集合中存入自定对象 姓名和年龄相同为同一个人,重复元素。去除重复元素 思路:1、对人描述,将人的一些属性等封装进对象 2、定义一个HashSet容器,存储人对象 3、取出 */ import java.util.*; //人描述 class Person { private String name; private int age; Person(String name,int age) { this.name=name; this.age=age; } public String getName() { return name; } public int getAge() { return age; } public boolean equals(Object obj) { if(!(obj instanceof Person)) return false; Person p=(Person)obj; return this.name.equals(p.name)&&this.age==p.age; } public int hashCode() { return this.name.hashCode()+this.age; } } class HashSetTest { public static void main(String[] args) { HashSet h=new HashSet(); h.add(new Person("shenm",10)); h.add(new Person("shenm2",6)); h.add(new Person("shenm1",30)); h.add(new Person("shenm0",10)); h.add(new Person("shenm0",10)); getOut(h); } //取出元素 public static void getOut(HashSet h) { for (Iterator it=h.iterator(); it.hasNext(); ) { Person p=(Person)it.next(); sop(p.getName()+"..."+p.getAge()); } } //打印 public static void sop(Object obj) { System.out.println(obj); } }
三、TreeSet
1、特点
a、底层的数据结构为二叉树结构(红黑树结构)
b)可对Set集合中的元素进行排序,是因为:TreeSet类实现了Comparable接口,该接口强制让增加到集合中的对象进行了比较,需要复写compareTo方法,才能让对象按指定需求(如人的年龄大小比较等)进行排序,并加入集合。
java中的很多类都具备比较性,其实就是实现了Comparable接口。
注意:排序时,当主要条件相同时,按次要条件排序。
import java.util.Iterator; import java.util.TreeSet; class Person implements Comparable{ private String name; private int age; public Person(){ } public Person(String name,int age){ this.name = name; this.age = age; } public void setName(String name){ this.name = name; } public String getName(){ return this .name; } public void setAge(int age){ this.age = age; } public int getAge(){ return this .age; } public int hashCode(){ return name.hashCode() + age * 39; } public boolean equals(Object obj){ if(this == obj) return true ; if(!(obj instanceof Person)) throw new ClassCastException("类型错误"); Person p = (Person)obj; return this .name.equals(p.name) && this.age == p.age; } public int compareTo(Object o){ Person p = (Person)o; //先按照年龄排序,再按照年龄排序,以免年龄相同的人,没有存进去。 int temp = this.age - p.age; return temp == 0?this.name.compareTo(p.name):temp; } } public class TreeSetDemo{ public static void main(String[] args){ TreeSet ts = new TreeSet(); //以Person对象年龄进行从小到大的排序 ts.add( new Person("alex" ,28)); ts.add( new Person("wendy" ,23)); ts.add( new Person("laura" ,21)); ts.add( new Person("zoe" ,29)); ts.add( new Person("hans" ,25)); Iterator it = ts.iterator(); while(it.hasNext()){ Person p = (Person)it.next(); System.out.println(p.getName() + ":" + p.getAge()); } } }
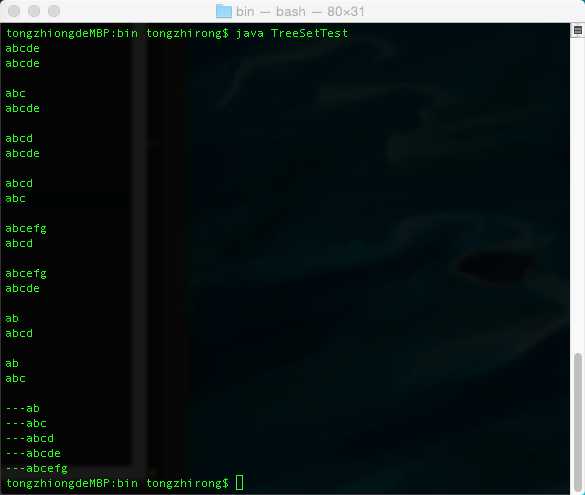
import java.util.Comparator; import java.util.Iterator; import java.util.TreeSet; public class TreeSetTest { public static void main(String[] args) { TreeSet ts = new TreeSet(new ComparatorByLen()); ts.add("abcde"); ts.add("abc"); ts.add("abcd"); ts.add("abcefg"); ts.add("ab"); Iterator it = ts.iterator(); while (it.hasNext()) System.out.println("---"+it.next()); } } class ComparatorByLen implements Comparator{ public int compare(Object o1,Object o2) { String s1 = (String)o1; String s2 = (String)o2; int temp = s1.length()-s2.length(); System.out.println(s1); System.out.println(s2+"\r\n"); return temp == 0?s1.compareTo(s2):temp; } }
第五节 Map
一、Map、HashMap、TreeMap
Map:一次添加一对元素,Collection一次添加一个元素。
Map也称为双列集合,Collection集合称为单列集合。
其实Map集合中存储的就是键值对。
map集合中必须保证键的唯一性。
常用方法:
1、添加
value put(key,value):返回前一个和key关联的值,如果没有返回null。
2、删除
void clear():清空map集合。
value remove(Object key):根据指定的key删除这个键值对。
3、判断
boolean containsKey(key);
boolean containsValue(value);
boolean isEmpty();
4、获取
value get(key):通过键获取值,如果没有该键返回null。
当然可以通过返回null,来判断是否包含指定键。
int size():获取键值对个数。
Map元素取出方式有两种:
Map集合的取出原理:将Map集合转成Set集合。再通过迭代器取出。
1、Set<K> keySet():将Map中所以的键存入到Set集合。因为Set具备迭代器。所以可以通过迭代方式取出所以键的值,再通过get方法。获取每一个键对应的值。
1 import java.util.HashMap; 2 import java.util.Iterator; 3 import java.util.concurrent.ConcurrentHashMap.KeySetView; 4 5 class Student implements Comparable<Student> 6 { 7 private String name; 8 private int age; 9 Student(String name,int age) 10 { 11 this.name = name; 12 this.age = age; 13 } 14 public int getAge() { 15 return age; 16 } 17 public String getName() { 18 return name; 19 } 20 //覆写hashcode 21 @Override 22 public int hashCode() { 23 //System.out.println(name+"---"); 24 return 22; 25 //return name.hashCode()+age*22; 26 } 27 //覆写equals,比较对象内容 28 @Override 29 public boolean equals(Object obj) { 30 System.out.println(obj+"eq"); 31 if(!(obj instanceof Student)) 32 throw new ClassCastException("传入类型不匹配!"); 33 Student s = (Student)obj; 34 return this.name.equals(s.name)&&this.age == s.age; 35 } 36 //覆写compareTo,以年龄为主 37 @Override 38 public int compareTo(Student o) { 39 // TODO Auto-generated method stub 40 int num = new Integer(this.age).compareTo(new Integer(o.age)); 41 if (num==0) 42 return this.name.compareTo(o.name); 43 return num; 44 } 45 public String toString() 46 { 47 return name+"..."+age; 48 } 49 } 50 51 class HashMapDemo 52 { 53 public static void main(String[] args) throws Exception 54 { 55 HashMap<Student, String> hm = new HashMap<Student,String>(); 56 hm.put(new Student("a",12),"beijing"); 57 hm.put(new Student("b",32),"shanghai"); 58 hm.put(new Student("c",22),"changsha"); 59 hm.put(new Student("d",62),"guangzhou"); 60 hm.put(new Student("e",12),"tianjing"); 61 keyset(hm); 62 } 63 public static void keyset(HashMap<Student,String> hm) 64 { 65 Iterator<Student> it=hm.keySet().iterator(); 66 67 while(it.hasNext()) 68 { 69 Student s=it.next(); 70 String addr=hm.get(s); 71 System.out.println(s+":"+addr); 72 } 73 } 74 75 }
2、Set<Map.Entry<K,V>> entrySet():将Map集合中的映射关系存入到Set集合中,而这个关系的数据类型就是:Map.Entry
其实,Entry也是一个接口,它是Map接口中的一个内部接口。
1 interface Map 2 { 3 public static interface Entry 4 { 5 public abstract Object getKey(); 6 public abstract Object getValue(); 7 } 8 }
1 class HashMapDemo 2 { 3 public static void main(String[] args) throws Exception 4 { 5 HashMap<Student, String> hm = new HashMap<Student,String>(); 6 hm.put(new Student("a",12),"beijing"); 7 hm.put(new Student("b",32),"shanghai"); 8 hm.put(new Student("c",22),"changsha"); 9 hm.put(new Student("d",62),"guangzhou"); 10 hm.put(new Student("e",12),"tianjing"); 11 //keyset(hm); 12 entryset(hm); 13 } 14 public static void entryset(HashMap<Student,String> hm) 15 { 16 Iterator<Map.Entry<Student, String>> it = hm.entrySet().iterator(); 17 while(it.hasNext()) 18 { 19 Map.Entry<Student, String> me = it.next(); 20 Student s = me.getKey(); 21 String addr = me.getValue(); 22 System.out.println(s+"...."+addr); 23 } 24 } 25 }
Map是一个接口,其实,Entry也是一个接口,它是Map的子接口中的一个内部接口,就相当于是类中有内部类一样。为何要定义在其内部呢?
原因:a、Map集合中村的是映射关系这样的两个数据,是先有Map这个集合,才可有映射关系的存在,而且此类关系是集合的内部事务。
b、并且这个映射关系可以直接访问Map集合中的内部成员,所以定义在内部。
标签:
原文地址:http://www.cnblogs.com/tozr/p/4631569.html