标签:
安装hadoop要先做以下准备:
1.jdk,安装教程在
http://www.cnblogs.com/stardjyeah/p/4640917.html
2.ssh无密码验证,配置教程在
http://www.cnblogs.com/stardjyeah/p/4641524.html
3.linux静态ip配置,教程在
http://www.cnblogs.com/stardjyeah/p/4640691.html
准备好以后就可以进行hadoop 2.5.0安装和配置了
1) 解压hadoop到自己的hadoop目录
2) 2.X版本较1.X版本改动很大,主要是用Hadoop MapReduceV2(Yarn) 框架代替了一代的架构,其中JobTracker 和 TaskTracker 不见了,取而代之的是 ResourceManager, ApplicationMaster 与 NodeManager 三个部分,而具体的配置文件位置与内容也都有了相应变化,具体的可参考文献:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
3) hadoop/etc/hadoop/hadoop-env.sh 与 hadoop/etc/hadoop/yarn-env.sh来配置两个文件里的JAVA_HOME
4) 配置etc/hadoop/core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/tmp</value> </property> </configuration>
5) 配置etc/hadoop/hdfs-site.xml (注意:这里需要自己手动用mkdir创建name和data文件夹,具体位置也可以自己选择,其中dfs.replication的值建议配置为与分布式 cluster 中实际的 DataNode 主机数一致。)
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/hdfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/hdfs/data</value> <final>true</final> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.rpc-address</name> <value>localhost:9000</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>localhost:50090</value> </property> </configuration>
6) 配置etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>localhost:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>localhost:19888</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/mr-history/tmp</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/mr-history/done</value> </property> </configuration>
7) 配置etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>localhost:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>localhost:18030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>localhost:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>localhost:18041</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>localhost:8088</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/mynode/my</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/home/hadoop/hadoop/hadoop-2.5.0/mynode/logs</value> </property> <property> <name>yarn.nodemanager.log.retain-seconds</name> <value>10800</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/logs</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir-suffix</name> <value>logs</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>-1</value> </property> <property> <name>yarn.log-aggregation.retain-check-interval-seconds</name> <value>-1</value> </property> </configuration>
8) 启动测试
先格式化namenode:bin/hdfs dfs namenode –format
如果没有报错则表示成功
启动hdfs: sbin/start-dfs.sh
Jps查看是否启动了namenode,datanode, SecondaryNameNode
启动yarn:start-yarn.sh
Jps查看是否启动了NodeManager, ResourceManager
然后登陆8088端口看是否会出现如下页面:
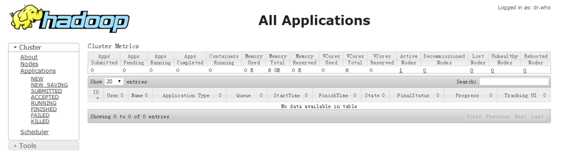
登陆50070看是否会出现如下页面:
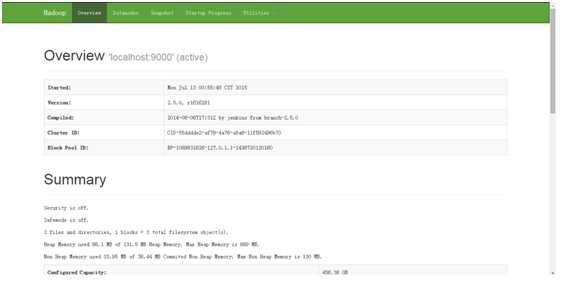
登陆50090看是否会出现如下页面:
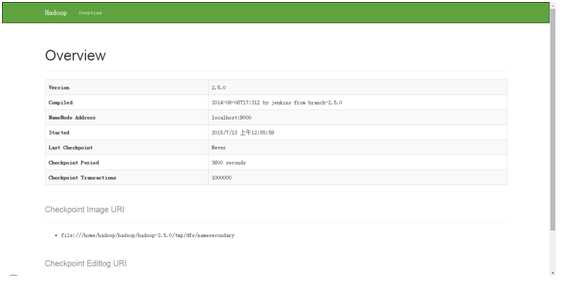
如果页面都出现,则表示hadoop安装成功!
下面测试一下hdfs文件系统
建立一个目录:bin/hdfs dfs -mkdir /TestDir/
上传一个文件:bin/hdfs dfs -put ./test.txt /TestDir/
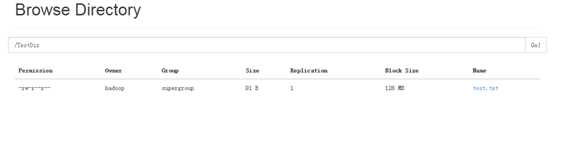
上传成功,下面进行wordcount测试
1.dfs上创建input目录
$bin/hadoop fs -mkdir -p input
2.把hadoop目录下的test.txt拷贝到dfs新建的input里
$bin/hadoop fs -copyFromLocal test.txt input
3.运行WordCount
$bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.0-sources.jar
org.apache.hadoop.examples.WordCount input output
4.运行完毕后,查看单词统计结果
$bin/hadoop fs -cat output/*
假如程序的输出路径为output,如果该文件夹已经存在,先删除
$bin/hadoop dfs -rmr output
查看wordcount结果如下:

标签:
原文地址:http://www.cnblogs.com/stardjyeah/p/4641554.html