标签:style blog http color 使用 strong
二.LZ77算法
1977年,Jacob Ziv和Abraham Lempel描述了一种基于滑动窗口缓存的技术,该缓存用于保存最近刚刚处理的文本(J. Ziv and A. Lempel, “A Universal Algorithm for Sequential Data Compression”, IEEE Transaction on Information Theory, May 1977)。这个算法一般称为IZ77。
LZ77和它的变体发现,在正文流中词汇和短语(GIF中的图像模式)很可能会出现重复。当出现一个重复时,重复的序列可以用一个短的编码来代替。压缩程序扫描这样的重复,同时生成编码来代替重复序列。随着时间的过去,编码可以重用来捕获新的序列。算法必须设计成解压程序能够在编码和原始数据序列推导出当前的映射。
在研究LZ77的细节之前,先看一个简单的例子(J. Weiss and D. Schremp, “Putting Data on a Diet”, IEEE Spectrum, August 1993)。考虑这样一句话:
the brown fox jumped over the brown foxy jumping frog
这个短语的长度总共是53个八位组 = 424 bit。算法从左向右处理这个文本。初始时,每个字符被映射成9 bit的编码,二进制的1跟着该字符的8 bit ASCII码。在处理进行时,算法查找重复的序列。当碰到一个重复时,算法继续扫描直到该重复序列终止。换句话说,每次出现一个重复时,算法包括尽可能多的字符。碰到的第一个这样的序列是the brown fox。这个序列被替换成指向前一个序列的指针和序列的长度。在这种情况下,前一个序列的the brown fox出现在26个字符之前,序列的长度是13个字符。对于这个例子,假定存在两种编码选项:8 bit的指针和4 bit的长度,或者12 bit的指针和6 bit的长度。使用2 bit的首部来指示选择了哪种选项,00表示第一种选项,01表示第二种选项。因此,the brown fox的第二次出现被编码为 <00b><26d><13 d >,或者00 00011010 1101。
压缩报文的剩余部分是字母y;序列<00b><27d><5 d >替换了由一个空格跟着jump组成的序列,以及字符序列ing frog。
图03-05-3演示了压缩映射的过程。压缩过的报文由35个9 bit字符和两个编码组成,总长度为35 x 9 + 2 x 14 = 343比特。和原来未压缩的长度为424比特的报文相比,压缩比为1.24。
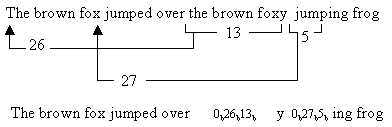
图03-05-3 LZ77模式例
(一)压缩算法说明
LZ77(及其变体)的压缩算法使用了两个缓存。滑动历史缓存包含了前面处理过的N个源字符,前向缓存包含了将要处理的下面L个字符(图03-05-4(a))。算法尝试将前向缓存开始的两个或多个字符与滑动历史缓存中的字符串相匹配。如果没有发现匹配,前向缓存的第一个字符作为9 bit的字符输出并且移入滑动窗口,滑动窗口中最久的字符被移出。如果找到匹配,算法继续扫描以找出最长的匹配。然后匹配字符串作为三元组输出(指示标记、指针和长度)。对于K个字符的字符串,滑动窗口中最久的K个字符被移出,并且被编码的K个字符被移入窗口。
图03-05-4(b)显示了这种模式对于我们的例子的运行情况。这里假定了39个字符的滑动窗口和13个字符的前向缓存。在这个例子的上半部分,已经处理了前面的40个字符,滑动窗口中是未压缩的最近的39个字符。剩下的源字符串在前向窗口中。压缩算法确定了下一个匹配,从前向窗口将5个字符移入到滑动窗口中,并且输出了这个匹配字符串的编码。经过这些操作的缓存的状态显示在这个例子的下半部分。
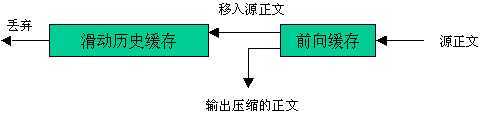
(a)通用结构

(b)例子
图03-05-4 LZ77模式
尽管LZ77是有效的,对于当前的输入情况也是合适的,但是存在一些不足。算法使用了有限的窗口在以前的文本中查找匹配,对于相对于窗口大小来说非常长的文本块,很多可能的匹配就会被丢掉。窗口大小可以增加,但这会带来两个损失:(1)算法的处理时间会增加,因为它必须为滑动窗口的每个位置进行一次与前向缓存的字符串匹配的工作;(2)<指针>字段必须更长,以允许更长的跳转。
(二)压缩算法描述
为了更好地说明LZ77算法的原理,首先介绍算法中用到的几个术语:
输入数据流(input stream):待压缩处理的字符序列。 | |
字符(character):输入数据流中的基本单元。 | |
编码位置(coding position):输入数据流中当前要编码的字符位置,指前向缓冲器中的开始字符。 | |
前向缓冲器(lookahead buffer):存放从编码位置到输入数据流结束的字符序列的存储器。 | |
窗口(Window):指包含W个字符的窗口,字符是从编码位置开始向后数也就是最后处理的字符数。 | |
指针(Pointer):指向窗口中的匹配串且含长度的指针。 |
LZ77编码算法的核心是查找从前向缓冲器开始的最长的匹配串。算法的具体执行步骤如下:
把编码位置设置到输入数据流的开始位置。 | |
查找窗口中最长的匹配串。 | |
输出(Pointer, Length) Characters,其中Pointer是指向窗口中匹配串的指针,Length表示匹配字符的长度,Characters是前向缓冲器中的第1个不匹配的字符。 | |
如果前向缓冲器不是空的,则把编码位置和窗口向前移Length+1个字符,然后返回到步骤2。 |
例:待编码的数据流如表03-05-1所示,编码过程如表03-05-2所示。现作如下说明:
“步骤”栏表示编码步骤。 | |
“位置”栏表示编码位置,输入数据流中的第1个字符为编码位置1。 | |
“匹配”栏表示窗口中找到的最长的匹配串。 | |
“字符”栏表示匹配之后在前向缓冲存储器中的第1个字符。 | |
“输出”栏以(Back_chars, Chars_length) Explicit_character格式输出。其中(Back_chars,Chars_length)是指指向匹配串的指针,告诉译码器“在这个窗口中向后退Back_chars个字符然后拷贝Chars_length个字符到输出”,Explicit_character是真实字符。例如,表3-13中的输出“(5,2) C”告诉译码器回退5个字符,然后拷贝2个字符“AB” |
表03-05-1 待编码的数据流
位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
字符 | A | A | B | C | B | B | A | B | C |
表03-05-2 编码过程
步骤 | 位置 | 匹配串 | 字符 | 输出 |
1 | 1 | -- | A | (0,0) A |
2 | 2 | A | B | (1,1) B |
3 | 4 | -- | C | (0,0) C |
4 | 5 | B | B | (2,1) B |
5 | 7 | A B | C | (5,2) C |
(三)解压算法
对于LZ77压缩文本的解压很简单。解压算法必须保存解压输出的最后N个字符。当碰到编码字符串时,解压算法使用<指针>,和<长度>,字段将编码替换成实际的正文字符串。
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/sqtds/p/3826308.html