标签:
在web开发中,session是个非常重要的概念。在许多动态网站的开发者看来,session就是一个变量,而且其表现像个黑洞,他只需要将东西在合适的时机放进这个洞里,等需要的时候再把东西取出来。这是开发者对session最直观的感受,但是黑洞里的景象或者说session内部到底是怎么工作的呢?当笔者向身边的一些同事或朋友问及相关的更进一步的细节时,很多人往往要么含糊其辞要么主观臆断,所谓知其然而不知其所以然。
笔者由此想到很多开发者,包括我自己,每每都是纠缠于框架甚至二次开发平台之上,而对于其下的核心和基础知之甚少,或者有心无力甚至毫不关心,少了逐本溯源的精神,每忆及此,无不惭愧。曾经实现过一个简单的HttpServer,但当时由于知识储备和时间的问题,没有考虑到session这块,不过近期在工作之余翻看了一些资料,并进行了相关实践,小有所得,本着分享的精神,我将在本文中尽可能全面地将个人对于session的理解展现给读者,同时尽我所能地论及一些相关的知识,以期读者在对session有所了解的同时也能另有所悟,正所谓授人以渔。
Session一般译作会话,牛津词典对其的解释是进行某活动连续的一段时间。从不同的层面看待session,它有着类似但不全然相同的含义。比如,在web应用的用户看来,他打开浏览器访问一个电子商务网站,登录、并完成购物直到关闭浏览器,这是一个会话。而在web应用的开发者开来,用户登录时我需要创建一个数据结构以存储用户的登录信息,这个结构也叫做session。因此在谈论session的时候要注意上下文环境。而本文谈论的是一种基于HTTP协议的用以增强web应用能力的机制或者说一种方案,它不是单指某种特定的动态页面技术,而这种能力就是保持状态,也可以称作保持会话。
谈及session一般是在web应用的背景之下,我们知道web应用是基于HTTP协议的,而HTTP协议恰恰是一种无状态协议。也就是说,用户从A页面跳转到B页面会重新发送一次HTTP请求,而服务端在返回响应的时候是无法获知该用户在请求B页面之前做了什么的。
对于HTTP的无状态性的原因,相关RFC里并没有解释,但联系到HTTP的历史以及应用场景,我们可以推测出一些理由:
1. 设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。那个时候没有动态页面技术,只有纯粹的静态HTML页面,因此根本不需要协议能保持状态;
2. 用户在收到响应时,往往要花一些时间来阅读页面,因此如果保持客户端和服务端之间的连接,那么这个连接在大多数的时间里都将是空闲的,这是一种资源的无端浪费。所以HTTP原始的设计是默认短连接,即客户端和服务端完成一次请求和响应之后就断开TCP连接,服务器因此无法预知客户端的下一个动作,它甚至都不知道这个用户会不会再次访问,因此让HTTP协议来维护用户的访问状态也全然没有必要;
3. 将一部分复杂性转嫁到以HTTP协议为基础的技术之上可以使得HTTP在协议这个层面上显得相对简单,而这种简单也赋予了HTTP更强的扩展能力。事实上,session技术从本质上来讲也是对HTTP协议的一种扩展。
总而言之,HTTP的无状态是由其历史使命而决定的。但随着网络技术的蓬勃发展,人们再也不满足于死板乏味的静态HTML,他们希望web应用能动起来,于是客户端出现了脚本和DOM技术,HTML里增加了表单,而服务端出现了CGI等等动态技术。
而正是这种web动态化的需求,给HTTP协议提出了一个难题:一个无状态的协议怎样才能关联两次连续的请求呢?也就是说无状态的协议怎样才能满足有状态的需求呢?
此时有状态是必然趋势而协议的无状态性也是木已成舟,因此我们需要一些方案来解决这个矛盾,来保持HTTP连接状态,于是出现了cookie和session。
对于此部分内容,读者或许会有一些疑问,笔者在此先谈两点:
1. 无状态性和长连接
可能有人会问,现在被广泛使用的HTTP1.1默认使用长连接,它还是无状态的吗?
连接方式和有无状态是完全没有关系的两回事。因为状态从某种意义上来讲就是数据,而连接方式只是决定了数据的传输方式,而不能决定数据。长连接是随着计算机性能的提高和网络环境的改善所采取的一种合理的性能上的优化,一般情况下,web服务器会对长连接的数量进行限制,以免资源的过度消耗。
2. 无状态性和session
Session是有状态的,而HTTP协议是无状态的,二者是否矛盾呢?
Session和HTTP协议属于不同层面的事物,后者属于ISO七层模型的最高层应用层,前者不属于后者,前者是具体的动态页面技术来实现的,但同时它又是基于后者的。在下文中笔者会分析Servlet/Jsp技术中的session机制,这会使你对此有更深刻的理解。
上面提到解决HTTP协议自身无状态的方式有cookie和session。二者都能记录状态,前者是将状态数据保存在客户端,后者则保存在服务端。
首先看一下cookie的工作原理,这需要有基本的HTTP协议基础。
cookie是在RFC2109(已废弃,被RFC2965取代)里初次被描述的,每个客户端最多保持三百个cookie,每个域名下最多20个Cookie(实际上一般浏览器现在都比这个多,如Firefox是50个),而每个cookie的大小为最多4K,不过不同的浏览器都有各自的实现。对于cookie的使用,最重要的就是要控制cookie的大小,不要放入无用的信息,也不要放入过多信息。
无论使用何种服务端技术,只要发送回的HTTP响应中包含如下形式的头,则视为服务器要求设置一个cookie:
Set-cookie:name=name;expires=date;path=path;domain=domain
支持cookie的浏览器都会对此作出反应,即创建cookie文件并保存(也可能是内存cookie),用户以后在每次发出请求时,浏览器都要判断当前所有的cookie中有没有没失效(根据expires属性判断)并且匹配了path属性的cookie信息,如果有的话,会以下面的形式加入到请求头中发回服务端:
Cookie: name="zj"; Path="/linkage"
服务端的动态脚本会对其进行分析,并做出相应的处理,当然也可以选择直接忽略。
这里牵扯到一个规范(或协议)与实现的问题,简单来讲就是规范规定了做成什么样子,那么实现就必须依据规范来做,这样才能互相兼容,但是各个实现所使用的方式却不受约束,也可以在实现了规范的基础上超出规范,这就称之为扩展了。无论哪种浏览器,只要想提供cookie的功能,那就必须依照相应的RFC规范来实现。所以这里服务器只管发Set-cookie头域,这也是HTTP协议无状态性的一种体现。
需要注意的是,出于安全性的考虑,cookie可以被浏览器禁用。
再看一下session的原理:
笔者没有找到相关的RFC,因为session本就不是协议层面的事物。它的基本原理是服务端为每一个session维护一份会话信息数据,而客户端和服务端依靠一个全局唯一的标识来访问会话信息数据。用户访问web应用时,服务端程序决定何时创建session,创建session可以概括为三个步骤:
1. 生成全局唯一标识符(sessionid);
2. 开辟数据存储空间。一般会在内存中创建相应的数据结构,但这种情况下,系统一旦掉电,所有的会话数据就会丢失,如果是电子商务网站,这种事故会造成严重的后果。不过也可以写到文件里甚至存储在数据库中,这样虽然会增加I/O开销,但session可以实现某种程度的持久化,而且更有利于session的共享;
3. 将session的全局唯一标示符发送给客户端。
问题的关键就在服务端如何发送这个session的唯一标识上。联系到HTTP协议,数据无非可以放到请求行、头域或Body里,基于此,一般来说会有两种常用的方式:cookie和URL重写。
1. Cookie
读者应该想到了,对,服务端只要设置Set-cookie头就可以将session的标识符传送到客户端,而客户端此后的每一次请求都会带上这个标识符,由于cookie可以设置失效时间,所以一般包含session信息的cookie会设置失效时间为0,即浏览器进程有效时间。至于浏览器怎么处理这个0,每个浏览器都有自己的方案,但差别都不会太大(一般体现在新建浏览器窗口的时候);
2. URL重写
所谓URL重写,顾名思义就是重写URL。试想,在返回用户请求的页面之前,将页面内所有的URL后面全部以get参数的方式加上session标识符(或者加在path info部分等等),这样用户在收到响应之后,无论点击哪个链接或提交表单,都会在再带上session的标识符,从而就实现了会话的保持。读者可能会觉得这种做法比较麻烦,确实是这样,但是,如果客户端禁用了cookie的话,URL重写将会是首选。
到这里,读者应该明白我前面为什么说session也算作是对HTTP的一种扩展了吧。如下两幅图是笔者在Firefox的Firebug插件中的截图,可以看到,当我第一次访问index.jsp时,响应头里包含了Set-cookie头,而请求头中没有。当我再次刷新页面时,图二显示在响应中不在有Set-cookie头,而在请求头中却有了Cookie头。注意一下Cookie的名字:jsessionid,顾名思义,就是session的标识符,另外可以看到两幅图中的jsessionid的值是相同的,原因笔者就不再多解释了。另外读者可能在一些网站上见过在最后附加了一段形如jsessionid=xxx的URL,这就是采用URL重写来实现的session。
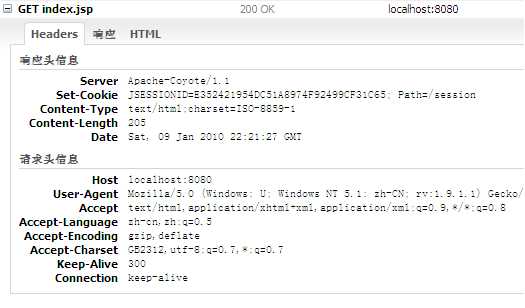
(图一,首次请求index.jsp)
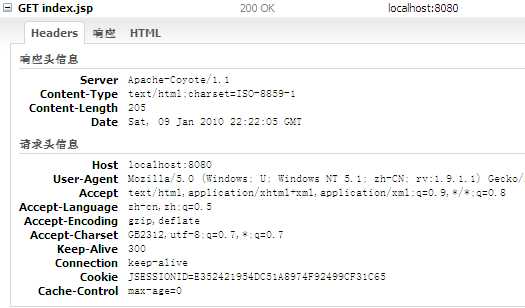
(图二,再次请求index.jsp)
Cookie和session由于实现手段不同,因此也各有优缺点和各自的应用场景:
1. 应用场景
Cookie的典型应用场景是Remember Me服务,即用户的账户信息通过cookie的形式保存在客户端,当用户再次请求匹配的URL的时候,账户信息会被传送到服务端,交由相应的程序完成自动登录等功能。当然也可以保存一些客户端信息,比如页面布局以及搜索历史等等。
Session的典型应用场景是用户登录某网站之后,将其登录信息放入session,在以后的每次请求中查询相应的登录信息以确保该用户合法。当然还是有购物车等等经典场景;
2. 安全性
cookie将信息保存在客户端,如果不进行加密的话,无疑会暴露一些隐私信息,安全性很差,一般情况下敏感信息是经过加密后存储在cookie中,但很容易就会被窃取。而session只会将信息存储在服务端,如果存储在文件或数据库中,也有被窃取的可能,只是可能性比cookie小了太多。
Session安全性方面比较突出的是存在会话劫持的问题,这是一种安全威胁,这在下文会进行更详细的说明。总体来讲,session的安全性要高于cookie;
3. 性能
Cookie存储在客户端,消耗的是客户端的I/O和内存,而session存储在服务端,消耗的是服务端的资源。但是session对服务器造成的压力比较集中,而cookie很好地分散了资源消耗,就这点来说,cookie是要优于session的;
4. 时效性
Cookie可以通过设置有效期使其较长时间内存在于客户端,而session一般只有比较短的有效期(用户主动销毁session或关闭浏览器后引发超时);
5. 其他
Cookie的处理在开发中没有session方便。而且cookie在客户端是有数量和大小的限制的,而session的大小却只以硬件为限制,能存储的数据无疑大了太多。
通过上述的讲解,读者应该对session有了一个大体的认识,但是具体到某种动态页面技术,又是怎么实现session的呢?下面笔者将结合session的生命周期(lifecycle),从源代码的层次来具体分析一下在servlet/jsp技术中,session是怎么实现的。代码部分以tomcat6.0.20作为参考。
在我问过的一些从事java web开发的人中,对于session的创建时机大都这么回答:当我请求某个页面的时候,session就被创建了。这句话其实很含糊,因为要创建session请求的发送是必不可少的,但是无论何种请求都会创建session吗?错。我们来看一个例子。
众所周知,jsp技术是servlet技术的反转,在开发阶段,我们看到的是jsp页面,但真正到运行时阶段,jsp页面是会被“翻译”为servlet类来执行的,例如我们有如下jsp页面:
|
<%@ page language="java" pageEncoding="ISO-8859-1" session="true"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>index.jsp</title> </head> <body> This is index.jsp page. <br> </body> </html> |
在我们初次请求该页面后,在对应的work目录可以找到该页面对应的java类,考虑到篇幅的原因,在此只摘录比较重要的一部分,有兴趣的读者可以亲自试一下:
|
...... response.setContentType("text/html;charset=ISO-8859-1"); pageContext = _jspxFactory.getPageContext(this, request, response, null, true, 8192, true); _jspx_page_context = pageContext; application = pageContext.getServletContext(); config = pageContext.getServletConfig(); session = pageContext.getSession(); out = pageContext.getOut(); _jspx_out = out;
out.write("\r\n"); out.write("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">\r\n"); out.write("<html>\r\n"); ...... |
可以看到有一句显式创建session的语句,它是怎么来的呢?我们再看一下对应的jsp页面,在jsp的page指令中加入了session="true",意思是在该页面启用session,其实作为动态技术,这个参数是默认为true的,这很合理,在此显示写出来只是做一下强调。很显然二者有着必然的联系。笔者在jsp/servlet的翻译器(org.apache.jasper.compiler)的源码中找到了相关证据:
|
...... if (pageInfo.isSession()) out.printil("session = pageContext.getSession();"); out.printil("out = pageContext.getOut();"); out.printil("_jspx_out = out;"); ...... |
上面的代码片段的意思是如果页面中定义了session="true",就在生成的servlet源码中加入session的获取语句。这只能够说明session创建的条件,显然还不能说明session是如何创建的,本着逐本溯源的精神,我们继续往下探索。
有过servlet开发经验的应该记得我们是通过HttpServletRequest的getSession方法来获取当前的session对象的:
|
public HttpSession getSession(boolean create); public HttpSession getSession(); |
二者的区别只是无参的getSession将create默认设置为true而已。即:
|
public HttpSession getSession() { return (getSession(true)); } |
那么这个参数到底意味着什么呢?通过层层跟踪,笔者终于理清了其中的脉络,由于函数之间的关系比较复杂,如果想更详细地了解内部机制,建议去独立阅读tomcat相关部分的源代码。这里我将其中的大致流程叙述一下:
1. 用户请求某jsp页面,该页面设置了session="true";
2. Servlet/jsp容器将其翻译为servlet,并加载、执行该servlet;
3. Servlet/jsp容器在封装HttpServletRequest对象时根据cookie或者url中是否存在jsessionid来决定是绑定当前的session到HttpRequest还是创建新的session对象(在请求解析阶段发现并记录jsessionid,在Request对象创建阶段将session绑定);
4. 程序按需操作session,存取数据;
5. 如果是新创建的session,在结果响应时,容器会加入Set-cookie头,以提醒浏览器要保持该会话(或者采用URL重写方式将新的链接呈现给用户)。
通过上面的叙述读者应该了解了session是何时创建的,这里再从servlet这个层面总结一下:当用户请求的servlet调用了getSession方法时,都会获取session,至于是否创建新的session取决于当前request是否已绑定session。当客户端在请求中加入了jsessionid标识而servlet容器根据此标识查找到了对应的session对象时,会将此session绑定到此次请求的request对象,客户端请求中不带jsessionid或者此jsessionid对应的session已过期失效时,session的绑定无法完成,此时必须创建新的session。同时发送Set-cookie头通知客户端开始保持新的会话。
理解了session的创建,就很好理解会话是如何在客户端和服务端之间保持的了。当首次创建了session后,客户端会在后续的请求中将session的标识符带到服务端,服务端程序只要在需要session的时候调用getSession,服务端就可以将对应的session绑定到当前请求,从而实现状态的保持。当然这需要客户端的支持,如果禁用了cookie而又不采用url重写的话,session是无法保持的。
如果几次请求之间有一个servlet未调用getSession(或者干脆请求一个静态页面)会不会使得会话中断呢?这个不会发生的,因为客户端只会将合法的cookie值传送给服务端,至于服务端拿cookie做什么事它是不会关心的,当然也无法关心。Session建立之后,客户端会一直将session的标识符传送到服务器,无论请求的页面是动态的、静态的,甚至是一副图片。
此处谈到的销毁是指会话的废弃,至于存储会话信息的数据结构是回收被重用还是直接释放内存我们并不关心。Session的销毁有两种情况:超时和手动销毁。
由于HTTP协议的无状态性,服务端无法得知一个session对象何时将再次被使用,可能用户开启了一个session之后再也没有后续的访问,而且session的保持是需要消耗一定的服务端开销的,因此不可能一味地创建session而不去回收无用的session。这里就引入了一个超时机制。Tomcat中的超时在web.xml里做如下配置:
|
<session-config> <session-timeout>30</session-timeout> </session-config> |
上述配置是指session在30分钟没有被再次使用就将其销毁。Tomcat是怎么计算这个30分钟的呢?原来在getSession之后,都要调用它的access方法,修改lastAccessedTime,在销毁session的时候就是判断当前时间和这个lastAccessedTime的差值。
手动销毁是指直接调用其invalidate方法,此方法实际上是调用expire方法来手动将其设置为超时。
当用户手动请求了session的销毁时,客户端是无法知道服务端的session已经被销毁的,它依然会发送先前的session标识符到服务端。而此时如果再次请求了某个调用了getSession的servlet,服务端是无法根据先前的session标识符找到相应的session对象的,这是又要重新创建新的session,分配新的标识符,并告知服务端更新session标识符开始保持新的会话。
在servlet/jsp中,容器是用何种数据结构来存储session相关的变量的呢?我们猜测一下,首先它必须被同步操作,因为在多线程环境下session是线程间共享的,而web服务器一般情况下都是多线程的(为了提高性能还会用到池技术);其次,这个数据结构必须容易操作,最好是传统的键值对的存取方式。
那么我们先具体到单个session对象,它除了存储自身的相关信息,比如id之外,tomcat的session还提供给程序员一个用以存储其他信息的接口(在类org.apache.catalina.session. StandardSession里):
|
public void setAttribute(String name, Object value, boolean notify) |
在这里可以追踪到它到底使用了何种数据:
|
protected Map attributes = new ConcurrentHashMap(); |
这就很明确了,原来tomcat使用了一个ConcurrentHashMap对象存储数据,这是java的concurrent包里的一个类。它刚好满足了我们所猜测的两点需求:同步与易操作性。
那么tomcat又是用什么数据结构来存储所有的session对象呢?果然还是ConcurrentHashMap(在管理session的org.apache.catalina.session. ManagerBase类里):
|
protected Map<String, Session> sessions = new ConcurrentHashMap<String, Session>(); |
具体原因就不必多说了。至于其他web服务器的具体实现也应该考虑到这两点。
Session hijack即会话劫持是一种比较严重的安全威胁,也是一种广泛存在的威胁,在session技术中,客户端和服务端通过传送session的标识符来维护会话,但这个标识符很容易就能被嗅探到,从而被其他人利用,这属于一种中间人攻击。
本部分通过一个实例来说明何为会话劫持,通过这个实例,读者其实更能理解session的本质。
首先,我编写了如下页面:
|
<%@ page language="java" pageEncoding="ISO-8859-1" session="true"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>index.jsp</title> </head> <body> This is index.jsp page. <br> <% Object o = session.getAttribute("counter"); if (o == null) { session.setAttribute("counter", 1); } else { Integer i = Integer.parseInt(o.toString()); session.setAttribute("counter", i + 1); } out.println(session.getAttribute("counter")); %> <a href="<%=response.encodeRedirectURL("index.jsp")%>">index</a> </body> </html> |
页面的功能是在session中放置一个计数器,第一次访问该页面,这个计数器的值初始化为1,以后每一次访问这个页面计数器都加1。计数器的值会被打印到页面。另外,为了比较简单地模拟,笔者禁用了客户端(采用firefox3.0)的cookie,转而改用URL重写方式,因为直接复制链接要比伪造cookie方便多了。
下面,打开firefox访问该页面,我们看到了计数器的值为1:
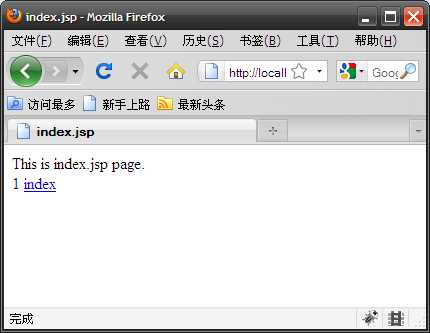
(图三)
然后点击index链接来刷新计数器,注意不要刷新当前页,因为我们没用采用cookie的方式,只能在url后面带上jsessionid,而此时地址栏里的url是无法带上jsessionid的。如图四,我把计数器刷新到了20。
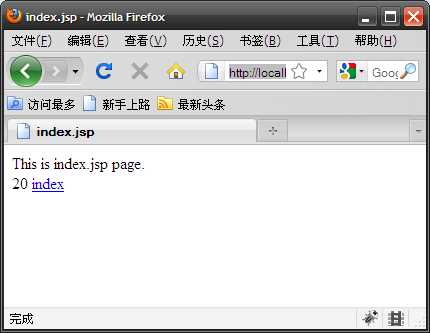
(图四)
下面是最关键的,复制firefox地址栏里的地址(笔者看到的是http://localhost:8080/sessio
n/index.jsp;jsessionid=1380D9F60BCE9C30C3A7CBF59454D0A5),然后打开另一个浏览器,此处不必将其cookie禁用。这里我打开了苹果的safari3浏览器,然后将地址粘贴到其地址栏里,回车后如下图:
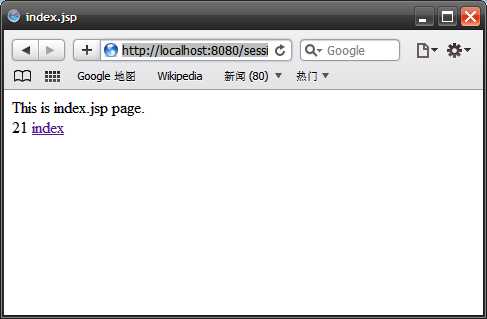
(图五)
很奇怪吧,计数器直接到了21。这个例子笔者是在同一台计算机上做的,不过即使换用两台来做,其结果也是一样的。此时如果交替点击两个浏览器里的index链接你会发现他们其实操纵的是同一个计数器。其实不必惊讶,此处safari盗用了firefox和tomcat之间的维持会话的钥匙,即jsessionid,这属于session hijack的一种。在tomcat看来,safari交给了它一个jsessionid,由于HTTP协议的无状态性,它无法得知这个jsessionid是从firefox那里“劫持”来的,它依然会去查找对应的session,并执行相关计算。而此时firefox也无法得知自己的保持会话已经被“劫持”。
到这里,读者应该对session有了更多的更深层次的了解,不过由于笔者的水平以及视野有限,文中也不乏表述欠妥之处,通篇更多地描述了在servlet/jsp中的session机制,但其他开发平台的机制也都万变不离其宗。只要认真思考,你会发现其实这里林林总总之间,总有一些因果关系存在。在软件规模日益增大的背景下,我们更多的时候接触到的是框架、组件,程序员的双眼被蒙蔽了,在这些框架、组件不断产生以及版本的不断更新中,其实有很多相对不变的东西,那就是规范、协议、模式、算法等等,真正令一个人得到提高的还是那些底层的支撑技术。平时多多思考的话,你就能把类似的探索转化为印证。做技术犹如解牛,知筋知骨方能游刃有余。
转载请保留出处:shoru.cnblogs.com 晋哥哥的私房钱
标签:
原文地址:http://www.cnblogs.com/weixiaole/p/4642410.html