标签:
按照《Hadoop权威指南(第2版)》来说,hadoop的单机模式又叫做独立模式(standalone或者local mode),无需运行任何守护进程(daemon),所有程序都在单个JVM上执行,由于在本机模式下测试和调试MapReduce程序比较方便,因此该模式适宜用在开发阶段
JDK1.7
Hadoop-2.6.0
Ubuntu server 14.04
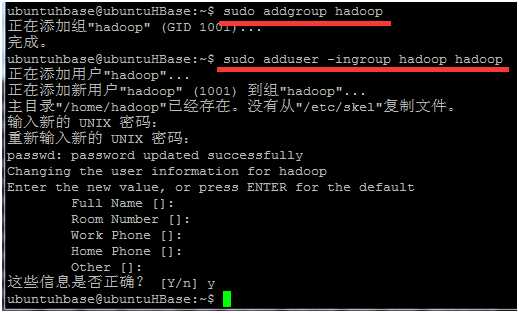
*图中出现的“/home/hadoop已经存在。没有从/etc/skel复制文件”是因为我之前已经建立过一次hadoop账户,所以不会自动生成hadoop的home目录
编辑/etc/sudoers文件
sudo vi /etc/sudoers
在“root ALL=(ALL:ALL) ALL”下面添加
hadoop ALL=(ALL:ALL) ALL
然后保存,此时有可能会提示保存不成功,需要添加!强制执行,强制执行即可
切换到hadoop帐号登录
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start
设置免密码登录
生成私钥和公钥
ssh-keygen -t rsa -P ""
执行完命令时候,会提示“Enter file which to save the key”,直接回车即可
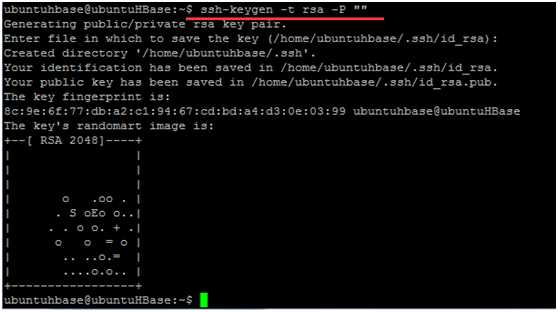
这时候在/home/hadoop/.ssh目录下会有一个.ssh文件生成id_rsa和id_rsa.pub两个密钥文件

然后将公钥追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试ssh 无密码登录
ssh localhost
出现如下图所示即为成功
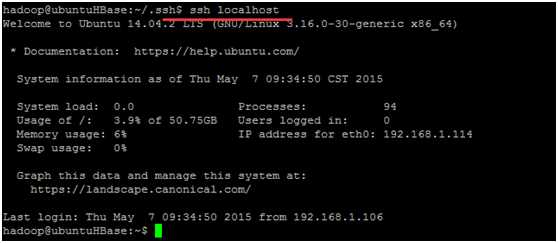
exit退出ssh登录
sudo tar -zxvf hadoop-2.6.0.tar.gz
sudo mv hadoop-2.6.0/ /opt/hadoop2.6
sudo chmod 777 /opt/hadoop2.6
sudo vi ~/.bashrc
在文件末端添加如下代码并保存
export HADOOP_INSTALL=/opt/hadoop2.6 export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
使环境变量生效
source ~/.bashrc
使用hadoop自带的wordcount来验证是否安装成功
1.在/home/hadoop下创建test文件夹
2.在test下创建文件一个文本文件,里面写上若干内容,最好字数多一些(可以将hadoop目录下的README.TXT复制过去)
3进入/opt/hadoop目录下,执行命令
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-sources.jar org.apache.hadoop.examples.WordCount /home/hadoop/test /home/hadoop/output
执行如图所示
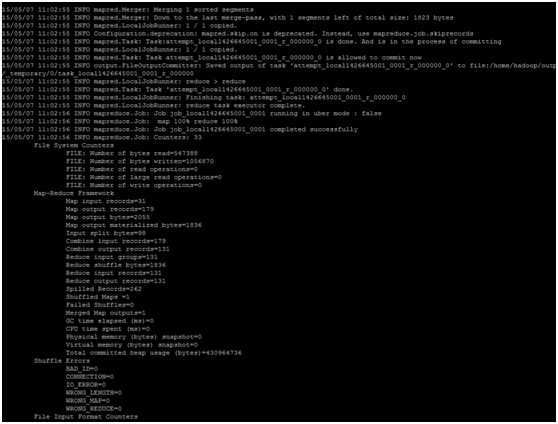
并且在 /home/hadoop/下生成了output文件夹
至此,hadoop单机模式已经安装成功!
参考自:
http://www.cnblogs.com/kinglau/p/3794433.html
http://www.cnblogs.com/luwikes/archive/2011/11/03/2234739.html
http://www.powerxing.com/install-hadoop/
《hadoop权威指南 第二版》
标签:
原文地址:http://www.cnblogs.com/xs104/p/4484268.html