标签:
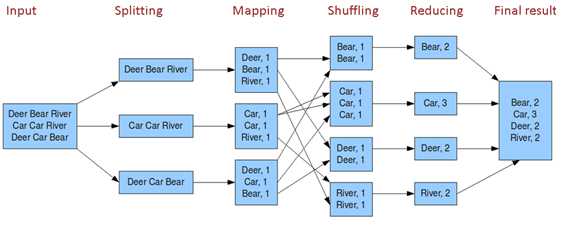
MapReduce原理图:
MapReduce具体执行过程图:
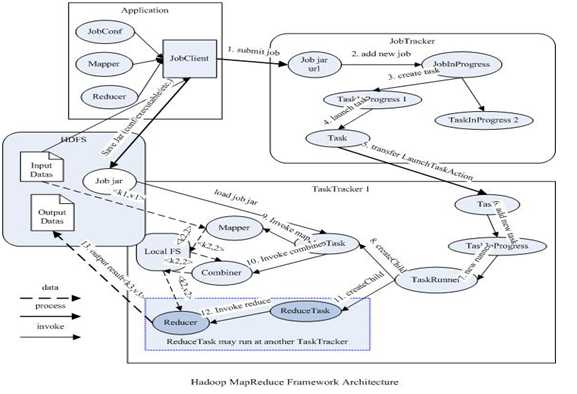
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值,接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员程序本身有bug,mapreduce错误处理机制都能保证提交的job能正常完成。
下面,我们来实现一个mapreduce的demo,wordcount
public class WordCountMapReduce extends Configured implements Tool { // Mapper Class public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /* * key是偏移量,value是一行一行的值 首先分割单词,组成key/value对进行输出 */ private Text mapOutputKey = new Text(); private final static IntWritable mapOutputValue = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // todo String line = value.toString().trim(); //segment StringTokenizer strToken = new StringTokenizer(line); while(strToken.hasMoreTokens()){ String word = strToken.nextToken(); mapOutputKey.set(word); context.write(mapOutputKey, mapOutputValue); } } } // Reducer public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable reduceOutputValue = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // todo int sum = 0; //reduce for(IntWritable value : values){ sum+=value.get(); } reduceOutputValue.set(sum); context.write(key, reduceOutputValue); } } public int run(String[] args) throws Exception { // set Conf env Configuration conf = new Configuration(); // conf.set("mapreduce.map.output.compress", true); // get job by conf Job job = Job.getInstance(super.getConf(), WordCountMapReduce.class.getSimpleName()); job.setJarByClass(WordCountMapReduce.class); // set job // step 1 : map phase job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // step 2 :reduce phase job.setCombinerClass(MyReducer.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // submit // job.submit(); boolean isSucceed = job.waitForCompletion(true); return isSucceed ? 1 : 0; } // Driver public static void main(String[] args) throws Exception { args = new String[] { "hdfs://192.168.1.109:8020/home/test/test.txt", "hdfs://192.168.1.109:8020/home/test/ouput2" }; int status = ToolRunner.run(new WordCountMapReduce(), args); System.out.println(status); } }
运行结果如下:

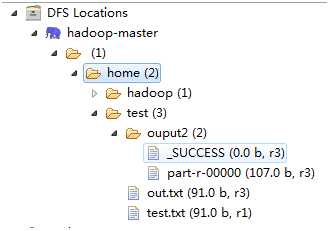
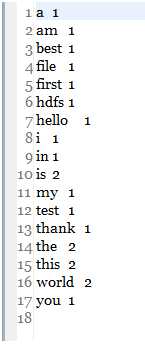
运行成功!
标签:
原文地址:http://www.cnblogs.com/stardjyeah/p/4643628.html