标签:
正则表达式是用来检验和操作字符串的强大工具。简单的理解正则表达式可以认为是一种特殊的验证字符串。正则表达式常见运用是验证用户输入信息格式,比如上面的那组“\w{1,}@\w{1,}\.\w{1”,实际上就是验证邮件地址是否合法的;当然正则表达式不仅仅是用于验证,可以说只要运用字符串的地方都可以使用正则表达式;
正则表达式在英文中写作(Regular Expression),根据正则表达式的使用范围和单词意思,.NET将其命名空间设置为System.Text.RegularExpressions;
在该命名空间内包括了8个基本的类:Capture、CaptureCollection、Group、GroupCollection、Match、MatchCollection、Regex和RegexCompilationInfo如图1所示;
 |
| 图1 MSDN Library中正则表达式命名空间 |
|---|
| Capture | 用于单个表达式捕获结果 |
| CaptureCollection | 用于一个序列进行字符串捕获 |
| Group | 表示单个捕获的结果 |
| GroupCollection | 表示捕获组的集会 |
| Match | 表示匹配单个正则表达式结果 |
| MatchCollection | 表示通过迭代方式应用正则表达式到字符串中 |
| Regex | 表示不可变的正则表达式 |
| RegexCompilationInfo | 将编译正则表达式需要提供信息 |
[注意]
本文属于初学正则表达式的入门文章,对于高级的分组(Group)及其涉及语法等在这里不做介绍;
在正则表达式中拥有一套自己的语法规则,常见语法包括;字符匹配、重复匹配、字符定位、转义匹配和其他高级语法(字符分组、字符替换和字符决策);
字符匹配语法:
| 字符语法 | 语法解释 | 语法例子 |
|---|---|---|
| \d | 匹配数字(0~9) | ‘\d’匹配8,不匹配12; |
| \D | 匹配非数字 | ‘\D’匹配c,不匹配3; |
| \w | 匹配任意单字符 | ‘\w\w’ 匹配A3,不匹配@3; |
| \W | 匹配非单字符 | ‘\W’匹配@,不匹配c; |
| \s | 匹配空白字符 | ‘\d\s\d’匹配3 d,不匹配abc; |
| \S | 匹配非空字符 | ‘\S\S\S’匹配A#4,不匹配3 d; |
| . | 匹配任意字符 | ‘....’匹配A$ 5,不匹配换行; |
| […] | 匹配括号中任意字符 | [b-d]匹配b、c、d, 不匹配e; |
| [^…] | 匹配非括号字符 | [^b-z]匹配a,不匹配b-z的字符; |
重复匹配语法:
| 重复语法 | 语法解释 | 语法例子 |
|---|---|---|
| {n} | 匹配n次字符 | \d{3}匹配\d\d\d,不匹配\d\d或\d\d\d\d |
| {n,} | 匹配n次和n次以上 | \w{2}匹配\w\w和\w\w\w以上,不匹配\w |
| {n,m} | 匹配n次上m次下 | \s{1,3}匹配\s,\s\s,\s\s\s,不匹配\s\s\s\s |
| ? | 匹配0或1次 | 5?匹配5或0,不匹配非5和0 |
| + | 匹配一次或多次 | \S+匹配一个以上\S,不匹配非一个以上\S |
| * | 匹配0次以上 | \W*匹配0以上\W,不匹配非N*\W |
字符定位语法:
| 重复语法 | 语法解释 | 语法例子 |
|---|---|---|
| ^ | 定位后面模式开始位置 | |
| $ | 前面模式位于字符串末端 | |
| \A | 前面模式开始位置 | |
| \z | 前面模式结束位置 | |
| \Z | 前面模式结束位置(换行前) | |
| \b | 匹配一个单词边界 | |
| \B | 匹配一个非单词边界 |
转义匹配语法:
| 转义语法 | 涉及字符(语法解释) | 语法例子 |
|---|---|---|
| “\”+实际字符 | \ . * + ? | ( ) { }^ $ | 例如:\\匹配字符“\” |
| \n | 匹配换行 | |
| \r | 匹配回车 | |
| \t | 匹配水平制表符 | |
| \v | 匹配垂直制表符 | |
| \f | 匹配换页 | |
| \nnn | 匹配一个8进制ASCII | |
| \xnn | 匹配一个16进制ASCII | |
| \unnnn | 匹配4个16进制的Uniode | |
| \c+大写字母 | 匹配Ctrl-大写字母 | 例如:\cS-匹配Ctrl+S |
构造正则表达式需要涉及Regex类,在Regex类中包括:IsMatch()、Replace()、Split()和Match的类;
(1) IsMatch()方法;
IsMatch()方法实际上是一个返回Bool值得方法,如果测试字符满足正则表达式返回True否则返回False;
例1;判断是非成都地区电话号码合法; 分析:成都地区电话号码组成028********,前面为固定区号028,后面满足8位数字; 设计正则表达式:028\d{8}(解释:028区号固定,后面为8个数字\d组成); 程序代码,如图2所示: |
 |
| 图2 “例1” IsMatch方法是用例 |
|---|
(2) Replace()方法;
Replace()方法实际上是一种替换的方法,替换匹配正则表达式匹配模式;
例2:在发布带有公开电子邮件地址的文章时,替换@位AT避免产生垃圾邮件; 分析:首先需要判断文章中电子邮箱地址,然后执行替换 设计正则表达式:判断电子邮箱表达式”\w{1,}@w{1,}\\.”; 程序代码:如图3所示; |
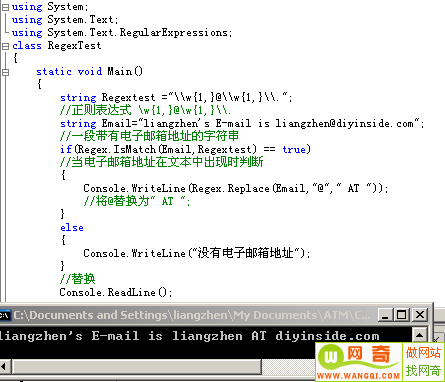 |
| 图3 “例2”Replace方法是用例 |
|---|
(3) Split()方法;
Split()方法实际上是拆分的方法,根据匹配正则表达式进行拆分储存在字符串数组中;
例3:从群发邮件地址中读取所有邮件地址; 分析:群发邮件采用“;”作为分割符,需要通过“;”进行拆分 程序代码:如图4所示; |
 |
| 图4 “例3”Split方法是用例 |
|---|
构造Regex对象的构造函数包括两个重载,一个是不含参数的构造、另外一个是含有参数的构造函数;
补充:RegexOptions属于枚举类型,包括IgnoreCase(忽略大小写)、ReghtToLeft(从右向左)、None(默认)、CultureInvariant(忽略区域)、Multline(多行模式)和SingleLine(单行模式);
例4,建立一个合法ISBN验证格式; 分析:ISBN格式为X-XXXXX-XXX-X; 正则表达式格式:\d-\d{5}-\d{3}-\d 构造该正则表达式函数Regex ISBNRegex = new Regex(表达式,参数为空) 详细代码:如图5所示; |
 |
| 图5 “例4”构造验证函数是用例 |
|---|
为了方便自己在学习正则表达式和快速检验自己编写表达式语句是否正确,下面提供一个IsMatch()方法正则表达式验证器编写;
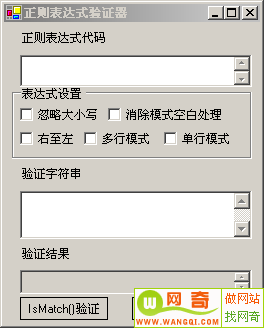 |
| 图6 正则表达式IsMatch方法验证器 |
|---|
 |
| 图7私有验证参数判断方法 |
|---|
 |
| 图8 IsMatch验证判断按钮方法 |
|---|
全面剖析c#正则表达式:
|
到目前为止,许多的编程语言和工具都包含对正则表达式的支持,当然.NET也不例外,.NET基础类库中包含有一个名称空间和一系列可以充分发挥规则表达式威力的类。
正则表达式的知识可能是不少编程人员最烦恼的事儿了。如果你还没有规则表达式方面的知识的话,建议从正则表达式的基础知识入手。前参见正则表达式语法。 下面就来研究C#中的正则表达式,C#中的正则表达式包含在.NET基础雷库的一个名称空间下,这个名称空间就是System.Text.RegularExpressions。该名称空间包括8个类,1个枚举,1个委托。他们分别是: Capture: 包含一次匹配的结果; CaptureCollection: Capture的序列; Group: 一次组记录的结果,由Capture继承而来; GroupCollection:表示捕获组的集合 Match: 一次表达式的匹配结果,由Group继承而来; MatchCollection: Match的一个序列; MatchEvaluator: 执行替换操作时使用的委托; Regex:编译后的表达式的实例。 RegexCompilationInfo:提供编译器用于将正则表达式编译为独立程序集的信息 RegexOptions 提供用于设置正则表达式的枚举值 Regex类中还包含一些静态的方法: Escape: 对字符串中的regex中的转义符进行转义; IsMatch: 如果表达式在字符串中匹配,该方法返回一个布尔值; Match: 返回Match的实例; Matches: 返回一系列的Match的方法; Replace: 用替换字符串替换匹配的表达式; Split: 返回一系列由表达式决定的字符串; Unescape:不对字符串中的转义字符转义。 下面介绍他们的用途: 先看一个简单的匹配例子,我们首先从使用Regex、Match类的简单表达式开始学习。 Match m = Regex.Match("abracadabra", "(a|b|r)+"); 我们现在有了一个可以用于测试的Match类的实例,例如:if (m.Success){},如果想使用匹配的字符串,可以把它转换成一个字符串: MesaageBox.Show("Match="+m.ToString()); 这个例子可以得到如下的输出: Match=abra。这就是匹配的字符串了。 Regex 类表示只读正则表达式类。它还包含各种静态方法(在下面的实例中将逐一介绍),允许在不显式创建其他类的实例的情况下使用其他正则表达式类。 以下代码示例创建了 Regex 类的实例并在初始化对象时定义一个简单的正则表达式。声明一个Regex对象变量:Regex objAlphaPatt;,接着创建Regex对象的一个实例,并定义其规则:objAlphaPatt=new Regex("[^a-zA-Z]"); IsMatch方法指示 Regex 构造函数中指定的正则表达式在输入字符串中是否找到匹配项。这是我们使用C#正则表达式时最常用的方法之一。下面的例子说明了IsMatch方法的使用: if( !objAlphaPatt.IsMatch("testisMatchMethod")) lblMsg.Text = "匹配成功"; else lblMsg.Text = "匹配不成功"; 这段代码执行的结果是“匹配成功” if( ! objAlphaPatt.IsMatch("testisMatchMethod7654298")) lblMsg.Text = "匹配成功"; else lblMsg.Text = "匹配不成功"; 这段代码执行的结果是“匹配不成功” Escape方法表示把转义字符作为字符本身使用,而不再具有转义作用,最小的元字符集(\、*、+、?、|、{、[、(、)、^、$、.、# 和空白)。Replace方法则是用指定的替换字符串替换由正则表达式定义的字符模式的所有匹配项。看下面的例子,还是使用上面定义的Regex对象:objAlphaPatt.Replace("this [test] ** replace and escape" ,Regex.Escape("()"));他的返回结果是:this\(\)\(\)test\(\)\(\)\(\)\(\)\(\)replace\(\)and\(\)escape,如果不是Escape的话,则返回结果是:this()()test()()()()()replace()and()escape,Unescape 反转由 Escape 执行的转换,但是,Escape 无法完全反转 Unescape。 Split方法是把由正则表达式匹配项定义的位置将输入字符串拆分为一个子字符串数组。例如: Regex r = new Regex("-"); // Split on hyphens. string[] s = r.Split("first-second-third"); for(int i=0;i<s.Length;i++) { Response.Write(s[i]+"<br>"); } 执行的结果是: 看上去和String的Split方法一样,但string的Split方法在由正则表达式而不是一组字符确定的分隔符处拆分字符串。 该事例运行结果是: |
标签:
原文地址:http://www.cnblogs.com/Alex80/p/4644988.html