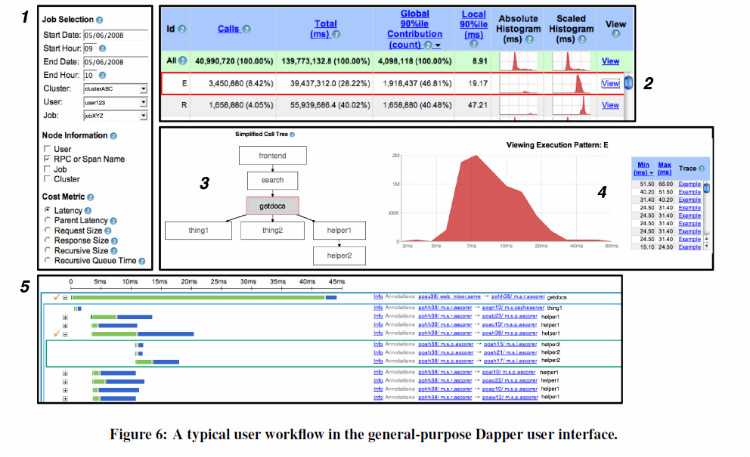
Google 的 Dapper 是淘宝鹰眼、点评CAT、京东Hydra、eBay CAL、Twitter Zipkin、窝窝Tracing的鼻祖。很多年前,Google 说,大部分用户都是通过这么个控制台来使用 Dapper 的,典型流程如下图所示:
- 用户输入他感兴趣的服务和时间窗口,选择相应跟踪模式(这里是 span 名称),以及他最关心的某个度量参数(这里是服务延迟)。
- 页面上会展示一个指定服务的所有分布式执行过程的性能摘要,用户可能会对这些执行过程根据需要进行排序,然后选择其中一个看详情。
- 一旦用户选定了某个执行过程后,将会有一个关于该执行过程的图形化描述展现出来,用户可以点击选择自己关心的那个过程。
- 系统根据用户在1中选择的度量参数,以及3中选择的具体过程,显示一个直方图。在这里显示的是有关 getdocs 的延迟分布的直方图,用户可以点击右侧的 example,选择具体的一个执行过程进行查看。
- 显示关于该执行过程的具体信息,上方是一个时间轴,下方用户可以进行展开或折叠,查看该执行过程各个组成部分的开销,其中绿色代表处理时间,蓝色代表花在网络上的时间(注:即我们说的调用链瀑布图)。
这就是 Google 从宏观一路看到微观的操作模式。即,服务(对应于一个或一串集群)的度量指标是宏观,真实的调用链是微观,在图形界面上即可从宏观杀入微观。
0x01,天机系统里如何从宏观看到微观
窝窝也致力于从某个工程的度量指标开始看起,选择自己关心的时段,最终一路点击后,找到可疑的调用链,看到它的瀑布图。下面逐个步骤讲解一下。
Step 1.找到感兴趣的工程
由于所有的 Java 工程都接入了 Dubbo,所以有了服务的注册与发现,也因此天机系统自然而然知道某个工程有多少个节点提供服务。
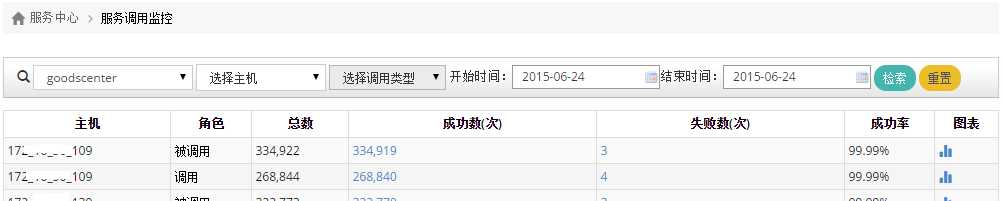
所以,我们可以在天机的服务调用监控里找到感兴趣的工程。
选择好时间段,我们可以看到这个工程的所有节点调用和被调用情况,如下图所示:
图2 商品中心的调用和被调用情况
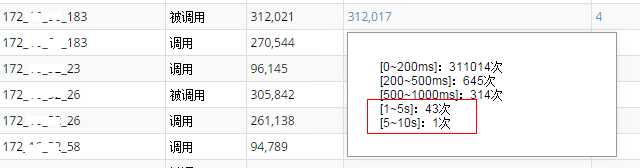
Step 2.关注接口响应时长
工程接口的响应时长被我们细分为不同区间:
- 0~200毫秒
- 200~500毫秒
- 500~1秒
- 1~5秒
- 5~10秒
那么,我们优先关注响应时长在 1~5秒 之间的接口,如下图所示:
图3 工程接口被调用时的响应时长统计
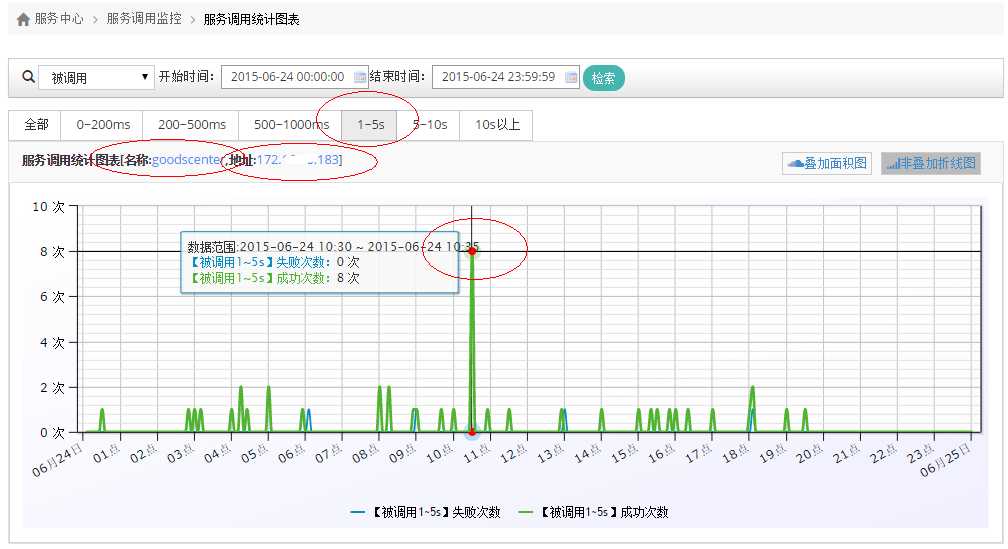
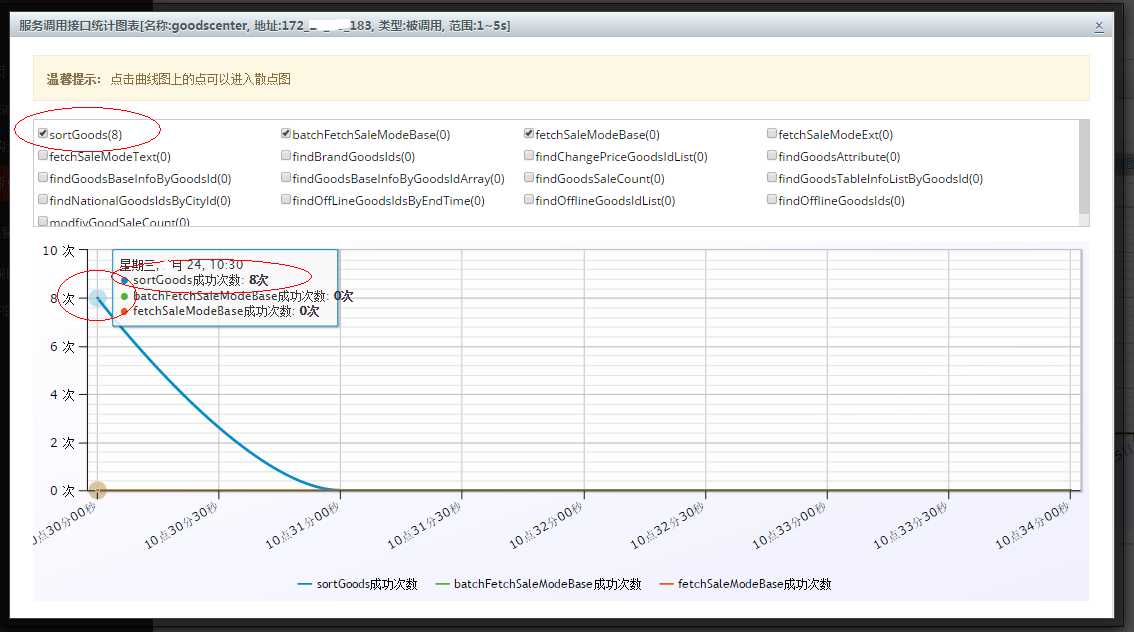
Step 3.看 时间-次数 曲线
点击对应的"图表"链接,我们进入服务调用统计图表页面。我们随后选择"1-5s"Tab页,如下图所示,可以看到商品中心 183 节点在6月24日里,接口响应时间在 1秒~5秒 之间的情况:
图4 调用统计图表
看到这里,我们只是知道某个时间点,商品中心有点不正常,但还不知道是哪一个接口不正常。
Step 4.看 时间-次数 曲线
点击上图中的那个红点,从而进入 10点30~10点35 之间接口响应时间在 1秒~5秒 之间的分接口曲线图:
图5 分接口曲线图
这样,我们发现,原来全是 sortGoods 这个方法引发的。
但这还不够。我们还是不知道为什么慢。
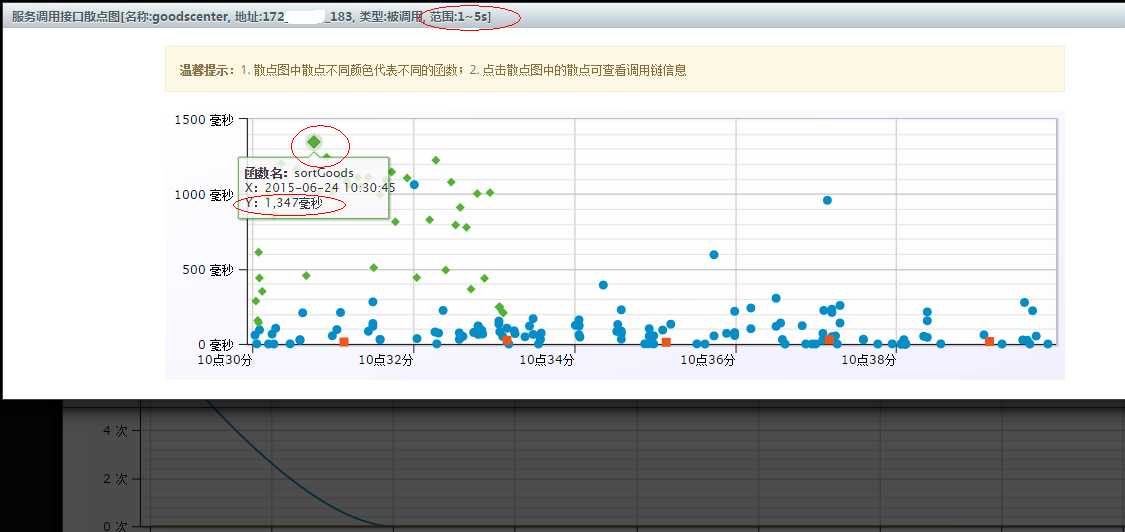
Step 5.看散点图
点上图中的那个蓝点,进入 10点30 左右的真实调用散点图,图上的每一个点都代表一个真实的调用:
图6 散点图
从上图可以看出,sortGoods 接口方法其实大多数响应时间在 500毫秒以下,最大响应时间也不超过 1.5秒。我们选中响应时间最大的那个点,点击一下。
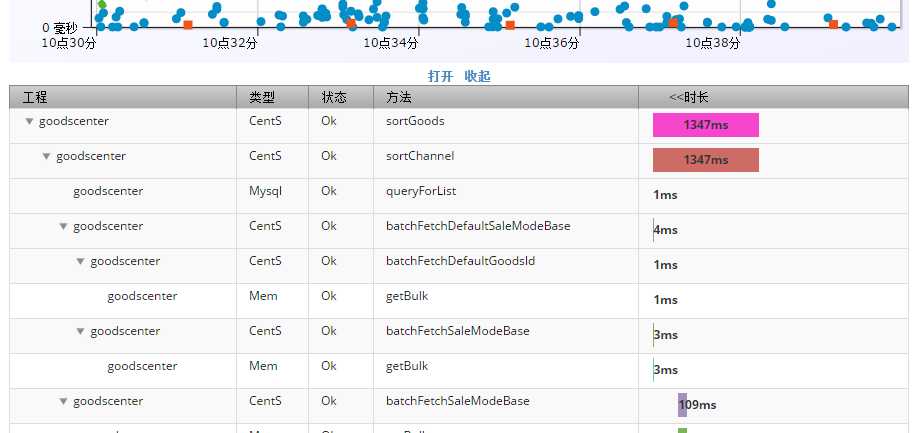
Step 6.看瀑布图
点响应时间最大的那个点,进入 10点30 左右、sortGoods 方法响应时间为 1.347 秒的真实调用链的瀑布图:
图7 瀑布图
瀑布图一般都很长。它可视化地绘制了每一层调用,包括进程内调用,包括跨进程调用,包括对缓存、对数据库的请求。
每一层调用,都可以看到具体参数,如 HostIP、RequestIP、输入参数、SQL语句(假如访问了DB的话)、对缓存是GET还是SET,如果有异常抛出,还能看到堆栈信息。
假如是对 memcached 批量获取,还可以看到具体的 keys 数组,如下图所示:
图8 keys也可以展示
最终,我们找到了 sortGoods 这次调用花了1秒多的原因:
图9 有一个 update 接口操作花了 540 毫秒
那么接下来分析这个方法的代码即可。
如上所示,经过刘奎等同学的努力,天机与鹰眼联手,在没有部门经理、研发经理、工程师的帮助下,我自己就能通过天机系统从宏观看到微观,并最终明确某个性能瓶颈的 Root Cause(当然还不够接触本质)。
这还不够。
还有其他的调用路径分析和调用去向分析场景。以后再讲。
-EOF-
辅助阅读:
延伸阅读: