标签:
t:代表特征,|C|:代表类别总数,ci 代表第i个类别
CF[i][j]:代表term class frequency,即表示在第j个类别的文档中出现了第i个term的文档数
DF[i]:代表term document frequency,即表示样本集中出现了该term的文档数
docsPerClass[i]:代表属于第i个类别的文档数
docs:代表训练文档总数
注意以上CF[i][j]、DF[i]、docsPersClass[i]的值都是文档数
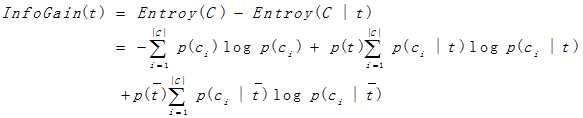
P(ci)为文档集中出现类别ci的概率;P(t)为特征出现在文档集中的概率;P(ci |t)表示当t出现在文档集中,文档属于类ci的概率;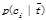 表示当t不出现在文档集中时,文档属于类ci的概率。
表示当t不出现在文档集中时,文档属于类ci的概率。
具体计算方式如下:
为了计算上的便利,当前特征t等价于第i个特征ti

与信息增益不同的是,互信息是计算特征与某个类别的互信息,而信息增益是计算特征与所有类别的信息增益,在具体的应用当中,可以选取互信息的期望或则选取特征与某个类别互信息最大的那个值作为该特征的互信息的值。
计算公式如下:
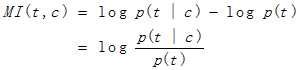
其中P(t)为特征出现在文档集中的概率,P(t|c)表示类别c中,包含特征t的文档数。具体计算方式如下:
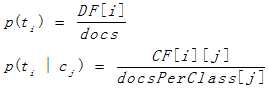
在具体的应用当中,常选取特征与某个类别卡方统计量最大的那个值作为该特征的卡方统计量的值。
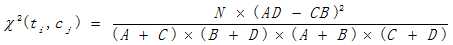
其中N为文档总数,A:文档集中出现特征t和属于类c的文档数;B:特征t出现而类c不出现的文档数;C:特征t不出现而类C出现的文档数;D:特征t和类c都不出现的文档数。具体计算公式如下:

4、期望交叉熵
?
?
?
????
标签:
原文地址:http://www.cnblogs.com/tugh/p/4642949.html