1.前言
作为世界上最强大的互联网服务提供商之一,Google一直在推动着业界技术的发展,最知名的当属其在分布式计算领域的领先成果和领导地位。而随着Google的网络技术领域的领导人Amin Vahdat在2015年6月召开的Open Networking Summit (ONS,开放网络峰会)上首次发布了Google网络技术的演进路径并重点对其数据中心网络技术进行阐述,Google在网络领域的技术创新才被揭开了神秘的面纱,并迅速在业界引起极大的反响。

本文以Amin的演讲内容为主要素材来源,并添加了作者对相关内容的理解和说明,希望能够帮助读者对Amin讲授的Google网络技术有更深入的认识。
2.Google网络技术演进路线
Google的网络技术进展,特别是其在SDN(Software Defined Networking,软件定义网络)领域的实践,一直以来都是业界关注的重点,最典型的就是其于2013年解密的B4网络被视作迄今最成功的SDN案例。而Amin在ONS 2015峰会上描绘的Google网络技术的演进路径(如图1所示),无疑为业界提供了探知Google网络技术发展脉络的重要线索。
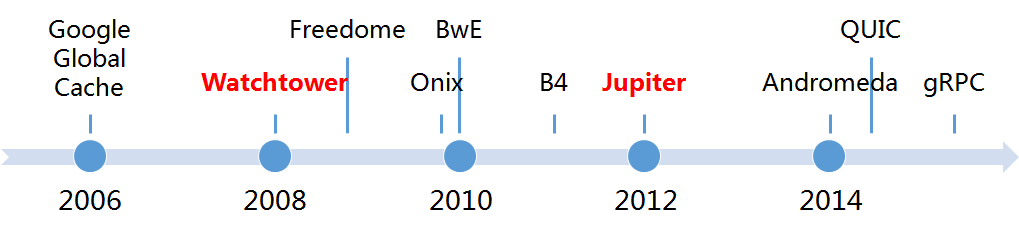
图1 Google网络技术演进路线
如图1所示,在过去的近十年间,Google建立的网络技术体系不但全面覆盖了众多的网络业务场景,并且还在随着Google业务的开展持续优化。与图1所示的各项网络技术相对应的网络业务场景如表1所示。
表1 Google网络创新技术的运用场景

如表1所示,Google的网络技术体系在当前已经非常完备。其中,既有其用于广域网互连的B4、Andromeda,又有其用于园区网互连的Freedome及其用于数据中心内部互连的Watchtower、Jupiter,还有其在网络业务层面的创新研发,例如QUIC、gRPC。
在上述的各项技术中,gRPC技术已经通过开源的方式全面公开,Onix、B4也有相关的学术论文揭示其核心原理,Andromeda则由Amin在去年的ONS峰会上做过介绍,其余的技术,诸如Freedome等,则仍然保持着神秘。在本次ONS峰会上,Amin为业界展示了Google数据中心网络的核心技术,并将它视作支撑Google云平台的重要基础。
3.Google数据中心网络技术概述
众所周知,计算、存储、网络是构成数据中心的三大要素。而在此前的技术进展中,计算和存储已经遭遇瓶颈,主要体现在:计算方面,随着半导体技术面临的物理障碍不可逾越,摩尔定律失效的时限日益临近,因此单个计算节点的性能提升有限,从而必须依赖于分布式计算技术,而分布式集群中节点间的网络将成为影响集群工作效率的关键;存储方面,支持管理机制和存储空间分离的分布式存储技术已经解决了存储容量的问题,但是存储I/O仍是瓶颈(高性能的Flash当前仍旧停留在缓存的范畴),因此存储性能的改进也非常依赖于网络能力的增强。因此,网络已经成为了提升大规模数据中心运行性能的关键点,是维持数据中心资源效率平衡的关键。
与其它的网络环境相比较,数据中心网络拥有的特征如图2所示。在这些特征中,最关键的一点在于数据中心的建设和管理都可以由同一个组织完成并具有单独的管理域,使得数据中心的网络边界相对清晰,并且其对外部网络的影响可控,这也是业界普遍将数据中心作为SDN引入首选场景的重要原因之一。另外,数据中心网络的带宽普遍有保障,而对延迟的要求更高,特别是Google数据中心中大量运行着分布式计算平台,这种场景下对tail latency的要求更加严格,即计算过程中由响应最慢节点返回结果时产生的延迟,这块“短木板”将是影响整个分布式系统计算性能的关键。
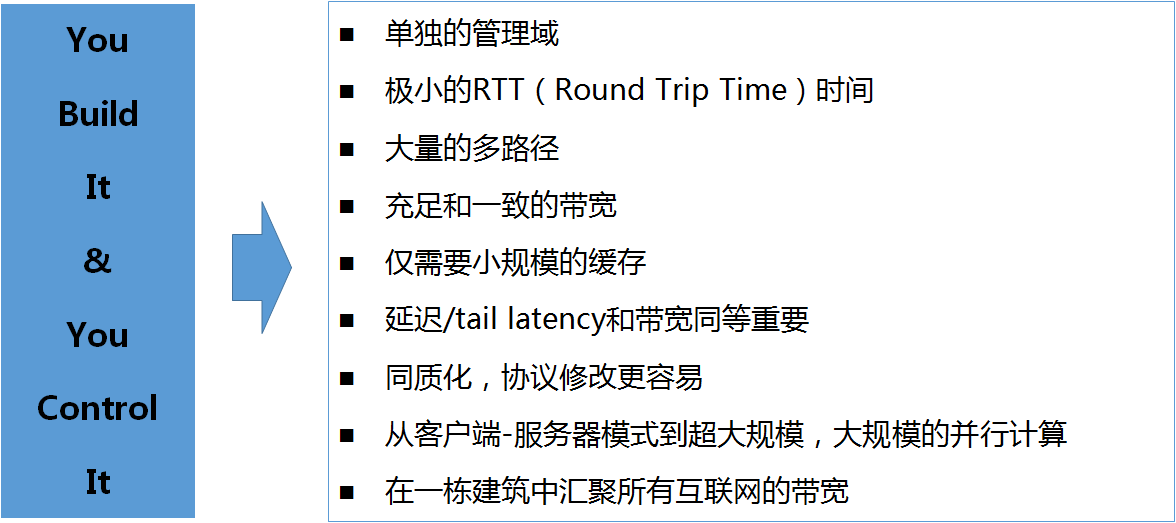
图2 数据中心网络特征
基于上述特征,数据中心网络产生了其独特的需求,特别是对于拥有海量服务器的大规模数据中心而言,其对网络的带宽、延迟、可用性等三方面的指标要求更是严格。以如图3所示的典型的数据中心资源环境为例,相应的性能指标需求的分析如下:
- 网络带宽:遵循Amdahl定律(并行计算环境中,每1MHz的计算将导致1Mbps的I/O需求),一台拥有64颗2.5GHz CPU的服务器的网络I/O需求将达到100Gbps的量级。如果数据中心中有50000台这样的服务器同时通信,那么相应网络带宽总需求将达到5Pbps。即使考虑到有10倍的超配比率,那么也至少需要500Tbps的网络带宽。同时,如前所述,不同网络分区之间的带宽(即bisection bandwidth)相对一致的特点使得整个数据中心网络都需要达到极高的网络带宽。
- 网络延迟:尽管Flash已经成当前高性能存储领域的主流技术,但是在Google看来,Flash在IOPS和访问延迟等方面还存在不足,而另一类高速存储技术NVM(Non-Volatile Memory),则能够达到十倍于Flash的吞吐率以及不及其十分之一的访问延迟,从而更好地提升存储访问性能。因此,一旦数据中心存储系统决定引入NVM,那么就意味着相应的网络延迟必须也要在10微秒的量级,否则的话网络将成为系统的瓶颈,造成计算、存储资源的空转,从而导致巨大的浪费。
- 网络可用性:在数据中心场景中,存在着大量的软硬件设备的运维工作。其中,新服务器的上架和旧服务器的下架,都会引起网络规模和组网拓扑的变动;同时,数据中心网络从1G 到10G 到40G再到 100G乃至今后可能的更高速网络技术的演进,也会导致相应网络环境的调整。在这种情形下,如何确保数据中心服务的持续不间断,是数据中心网络可用性提升面临的一个难题。
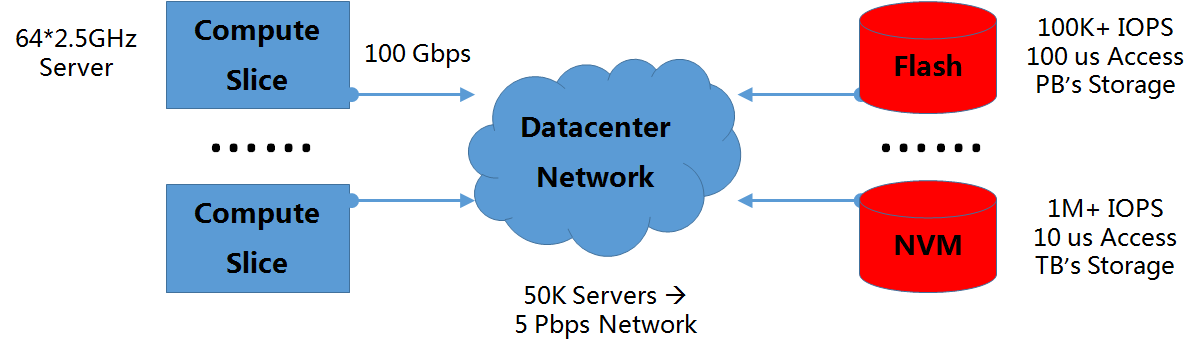
图3 数据中心资源环境及网络性能需求分析
上述的高性能网络指标对于维持Google数据中心网络的运行顺畅至关重要,而传统的“以设备盒子为中心(box-centric)”的网络技术体系无论是在性能方面还是在管理复杂度方面都已经难以满足实际需求。鉴于厂商产品不能跟上Google数据中心网络发展的步伐,Google在该领域进行了自主的研发和创新。总体而言,Google数据中心网络的设计与实现引入了以下三条策略:
- 基于Clos网络。Clos网络来自传统的电路交换领域,它于上世纪五十年代就被提出。其核心理念是无阻塞的多级交换技术,其中每一级的每个单元与下一级的设备都是全相连,其最大的优势在于能够提供海量的东西向流量传输支持。
- 使用商用晶片(Merchant Silicon)。商用晶片的优势之一是降低成本,避免了传统网络设备采用厂商定制ASIC带来的的高昂成本;同时,Google在运用商用晶片时还有额外的要求,最典型是要其支持Google对网络协议的自主创新。
- 建立统一控制。逻辑上集中的控制是SDN的核心理念,通过拥有全局网络视图的控制器统一控制网络传输通路,使得全网数以千计的网络转发设备能够像一台能力强大的网络设备一样工作,提升资源利用率,降低管理复杂度。
遵循上述策略,Google数据中心基于Clos网络拓扑和商用晶片自主研发了具备强大网络吞吐能力的转发层设备集群,同时基于统一控制的理念自主研发了网络控制层技术及配套的控制协议。
4.Google数据中心网络转发层技术
众所周知,Google数据中心每时每刻都在承担着海量的来自互联网的数据访问。而在当前,Google数据中心内部的网络流量已经超出了其数据中心与外部互联网之间的流量。为了应对如此之大的数据流量压力,Google数据中心网络一直在持续提升其网络转发层的性能,相关的数据如表2所示。
表2 Google数据中心网络演进
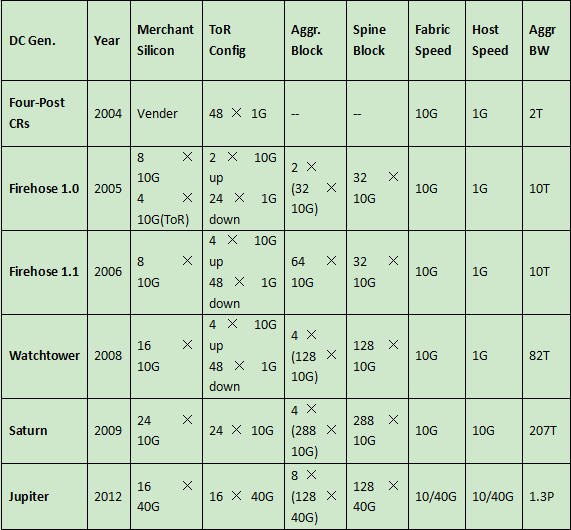
如表2所示,在2005年以前,Google还是需要依赖设备厂商提供的产品建设其数据中心网络。但是随着厂商设备不能满足Google数据中心高速发展的需求,Google在2005年开始自主研发,迄今已经演进了五代。其中,第一代Firehose 1.0貌似只是停留在设计阶段,并没有实际的设备产出,而第二代Fierhose 1.1则是真正部署在了Google数据中心的网络中。为了稳妥起见,Firehose 1.1还是采用了与传统的厂商设备网络并肩运行的方式,直到2008年,第三代数据中心网络技术Watchtower出现并全面替代了厂商设备,使得Google数据中心开始完全采用其自主研发的技术和设备。在第四代Saturn中,10G网络已经成为Google数据中心中各计算节点的标配,这也证明了Google网络技术的前瞻性。
Jupiter是Google最新一代的数据中心网络,它引入了SDN技术并且使用了OpenFlow,其支持的网络带宽已经达到Pbps量级,满足了前文所述的大规模数据中心对网络带宽的需求。如Amin所言,Pbps的网络速度意味着网络能够在十分之一秒内就完成美国国会图书馆藏书所有扫描内容的数据传输,达到这一量级的Google数据中心网络则可以同时支持100000台计算节点以10Gbps的网络速度通信,这个规模是非常惊人的。
从表2所示的数据中可以看出,与第一代相比,Google的第五代数据中心网络带宽已经扩展了100余倍。而Amin在演讲中则有提及,在从2008年7月到2014年11月的短短几年间,Google数据中心内部的服务器产生的汇聚层流量已经增长近50倍。因此,不难看出,正是Google业务的蓬勃发展驱动了其数据中心网络技术的持续演进。
Jupiter的主要构建模块和最终的设备形态分别如图4和图5所示。虽然仅仅在图中还不能完全看出相关的设计和实现细节,同时其显示的产品规格也与表2所示的相关信息不能完全关联,但是它已经把Google在其数据中心网络中引入的采用Clos拓扑、商用晶片等核心设计理念展露无遗。同时,关于Jupiter的更多信息会在 “Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network”(将在2015年8月举办的SIGCOMM上发表)一文中被详尽阐述。
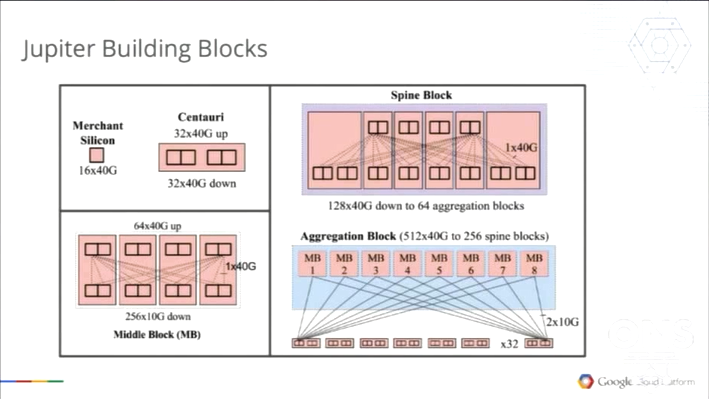
图4 Jupiter设备构建模块示意

图5 Jupiter设备最终形态展示
5.Google数据中心网络控制层技术
作为网络的“大脑”,控制层在Google数据中心网络中承担了非常重要的角色。虽然在本次ONS峰会上,Amin没有对其做更为详尽的解读,但是从他的演讲内容中已经初见端倪,可以看到Goolge在该领域的研发思路。
首先,Google数据中心网络控制层借鉴了其在分布式计算领域的先进理念。Google研发的分布式计算技术,例如GFS、MapReduce、BigTable、Spanner等,其架构中普遍在控制层采用了逻辑上集中化部署的管控节点,用于管理分布式部署的计算/存储节点并控制相关任务的实现流程,而具体的处理工作则由相应的计算/存储节点并行完成。这种架构的最大优点在于管控节点的集中化管理有效降低了管理复杂度,同时带外管控的方式又不影响分布式系统的性能。类似的理念在Google网络技术中也已经多有引入,例如B4、Andromeda。
其次,Google数据中心网络控制平面协议采用了自主研发的思路。这主要是因为数据中心网络性能的提升需要破除对多路径转发的限制,所以大量的传统协议将不再适用。同时Google不希望在这方面过分依赖于厂商专有设备,又苦于没有合适的开源项目支持,使得自主研发成为了最好的途径。Google自主研发的数据中心网络控制平面协议能够支持大规模网络的广播协议扩展,以及具备对各台网络设备独立配置的网管能力,从而满足大规模数据中心网络的集中化管理的需求。
以上述思路为指导,Google在其数据中心网络中研发和部署了FirePath协议,相应的控制层架构和工作方式如图6所示。其中,逻辑上集中化的Master节点通过Firepath协议从分布式部署的Client节点上采集网络中所有网络设备的连接状态,并将其在Master节点集群中散布,最终把计算得到的网络数据转发表项统一下发给各台设备。
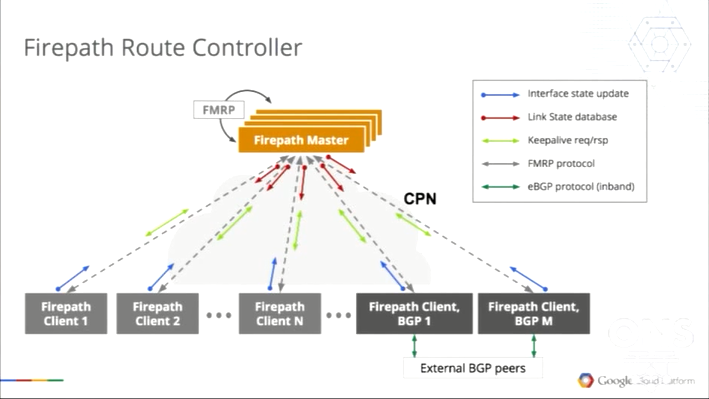
图6 Google Firepath Route Controller工作示意
据Amin介绍,FirePath协议主要是在早期的Google数据中心网络(Firehose、Watchtower)中被使用,其中的技术细节也将在相关的学术论文上作披露。而在Jupiter网络中,是否有新的网络控制层技术被提出,目前尚不得而知,但是有理由相信其核心原理和架构设计一定也是会遵从Google一贯的分布式系统理念。
6.小结
Amin在ONS 2015上透露的信息让业界得以有机会感受到Google在网络领域的强大创新。依托其在分布式计算领域的先进优势,Google在数据中心网络中强调网络设备的同质化,进而通过组建分布式集群的方式改进整个网络的性能、扩展性、可用性,并以逻辑上的集中控制提升网络的管控效率。就在业界还在纷纷攘攘讨论SDN的概念含义的时候,Google已经以实际行动开展了相关的实践,从而再次成为网络领域的领先者。
不夸张地说,Google的今天就是广大互联网服务提供商、基础网络运营商的明天和后天,因此其技术路径和研发思路具有非常重要的参考价值。同时,围绕“商用器件+Linux+自有协议”的网络软硬件设备的自主研发理念也势必会对整个网络产业的发展产生巨大影响。
作者简介:王峰:中国电信研究院高级研究员,中国科学技术大学计算机科学与技术专业博士,高级工程师。