标签:
两周前,做的一个项目需要模拟一批用户评价数据,如果想让数据看着真实点,那就得使用随机的用户昵称和头像啊。要是头像或者昵称全都差不多,那别人一看就看出来这是做的数据了。
于是乎我就写了个从我QQ空间开始的蜘蛛网式的爬虫程序,程序断断续续的运行了两周。总共爬到了腾讯3000万QQ数据,其中有300万包含用户(QQ号,昵称,空间名称,会员级别,头像,最新一条说说内容,最新说说的发表时间,空间简介,性别,生日,所在省份,城市,婚姻状况)的详细数据。
目前已经爬到我的第7圈好友(depth=7)3000万数据,目前的瓶颈在家里的网速和电脑的配置上。 最快的时候爬取速度达到一天500W新Q数据。
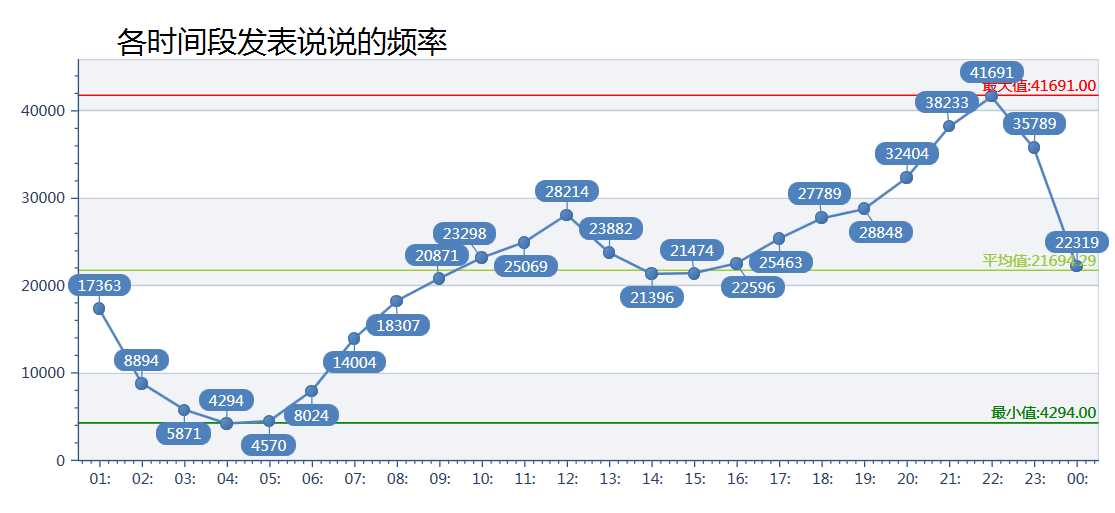
我写了个小程序拿了腾讯3000万QQ用户数据,出了一份很有趣的数据报告
标签:
原文地址:http://www.cnblogs.com/cinser/p/4656386.html