标签:
要求:抓取博客的粉丝数、关注数、圆龄、文章数、阅读数、评论数、积分、排名、推荐数、反对数等数据。
首先,来看下标准的博客界面,博客首页含有昵称、圆龄、粉丝、关注以及随笔、文章、评论等数据。
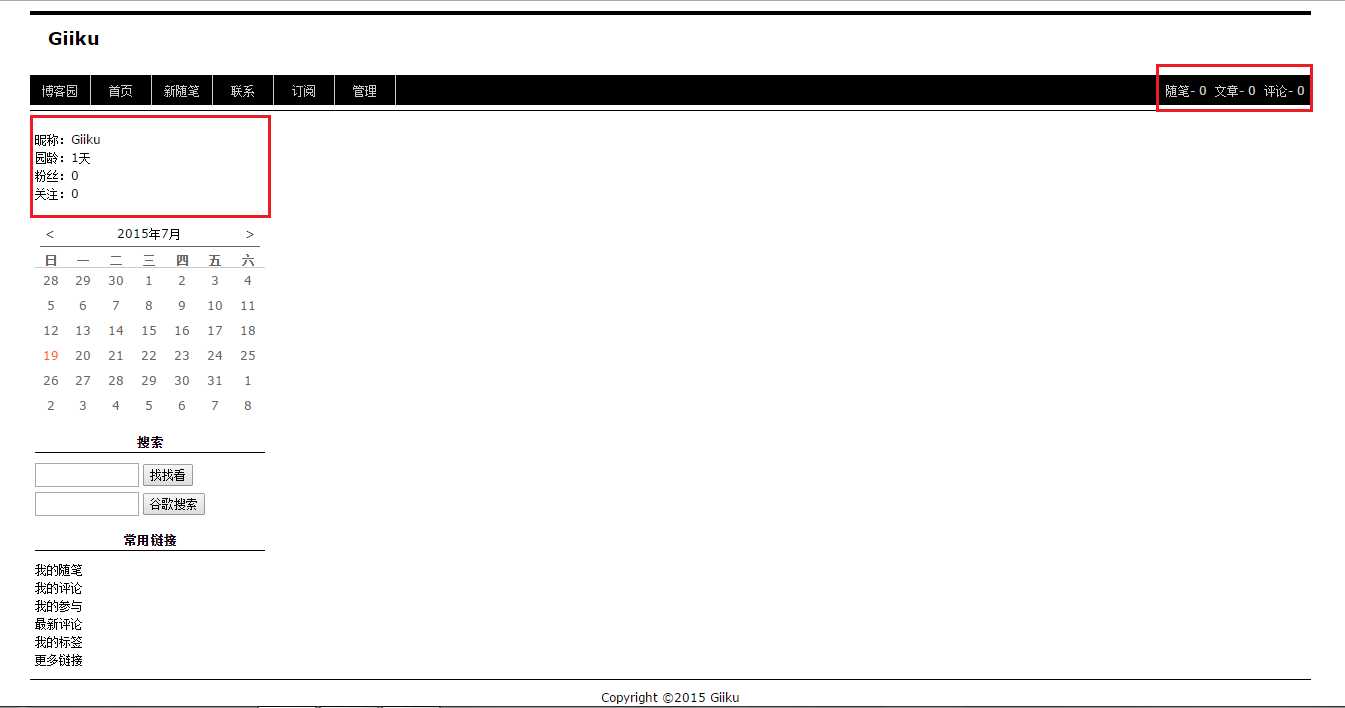
右键页面,审查元素,可以看到以下HTML代码。
1 <div id="blog-news">
2 <div id="profile_block">
3 昵称:<a href="http://home.cnblogs.com/u/giiku/">Giiku</a><br>
4 园龄:<a href="http://home.cnblogs.com/u/giiku/" title="入园时间:2015-07-18">1天</a><br>
5 粉丝:<a href="http://home.cnblogs.com/u/giiku/followers/">0</a><br>
6 关注:<a href="http://home.cnblogs.com/u/giiku/followees/">0</a>
7 <div id="p_b_follow"></div>
8 </div>
9 </div>
那么既然可以从HTML里面看到页面的数据,那么是否我们只要获取该页面的HTML文本,就可以抓取这些数据呢?
通过URL,先读取一下http://www.cnblogs.com/giiku/的html文本。
//打开URL
URL myURL = new URL(url);
URLConnection conn = myURL.openConnection();
//获取输入流
InputStream in = (InputStream) conn.getContent();
BufferedReader buf = new BufferedReader(new InputStreamReader(in,
"UTF-8"));
String line = "";
StringBuilder html = new StringBuilder();
//获取html文本
while ((line = buf.readLine()) != null) {
html.append(line);
}

<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="utf-8"/>
<title>Giiku - 博客园</title>
<link type="text/css" rel="stylesheet" href="/bundles/blog-common.css?v=VDh8zSH1vx51MDqRT7hK220akQ58FjlaaeGuWBPhfOA1"/>
<link id="MainCss" type="text/css" rel="stylesheet" href="/skins/Custom/bundle-Custom.css?v=Z683z9azGWin6jOfOyAHK6FgPVxm_nmCnl3EFztc2eE1"/>
<link title="RSS" type="application/rss+xml" rel="alternate" href="http://www.cnblogs.com/giiku/rss"/>
<link title="RSD" type="application/rsd+xml" rel="EditURI" href="http://www.cnblogs.com/giiku/rsd.xml"/>
<link type="application/wlwmanifest+xml" rel="wlwmanifest" href="http://www.cnblogs.com/giiku/wlwmanifest.xml"/>
<script src="http://common.cnblogs.com/script/jquery.js" type="text/javascript"></script>
<script type="text/javascript">var currentBlogApp = ‘giiku‘, cb_enable_mathjax=false;</script>
<script src="/bundles/blog-common.js?v=FPlxjK7DBkhdjUge-xvpcctYZfiyO32cepQZO-j3WJk1" type="text/javascript"></script>
</head>
<body>
<a name="top"></a>
<!--done-->
<div id="home">
<div id="header">
<div id="blogTitle">
<a id="lnkBlogLogo" href="http://www.cnblogs.com/giiku/"><img id="blogLogo" src="/Skins/custom/images/logo.gif" alt="返回主页" /></a>
<!--done-->
<h1><a id="Header1_HeaderTitle" class="headermaintitle" href="http://www.cnblogs.com/giiku/">Giiku</a></h1>
<h2></h2>
</div><!--end: blogTitle 博客的标题和副标题 -->
<div id="navigator">
<ul id="navList">
<li><a id="MyLinks1_HomeLink" class="menu" href="http://www.cnblogs.com/">博客园</a></li>
<li><a id="MyLinks1_MyHomeLink" class="menu" href="http://www.cnblogs.com/giiku/">首页</a></li>
<li><a id="MyLinks1_NewPostLink" class="menu" rel="nofollow" href="http://i.cnblogs.com/EditPosts.aspx?opt=1">新随笔</a></li>
<li><a id="MyLinks1_ContactLink" class="menu" rel="nofollow" href="http://msg.cnblogs.com/send/Giiku">联系</a></li>
<li><a id="MyLinks1_Syndication" class="menu" href="http://www.cnblogs.com/giiku/rss">订阅</a>
<!--<a id="MyLinks1_XMLLink" class="aHeaderXML" href="http://www.cnblogs.com/giiku/rss"><img src="http://www.cnblogs.com/images/xml.gif" alt="订阅" /></a>--></li>
<li><a id="MyLinks1_Admin" class="menu" rel="nofollow" href="http://i.cnblogs.com/">管理</a></li>
</ul>
<div class="blogStats">
<!--done-->
随笔- 0
文章- 0
评论- 0
</div><!--end: blogStats -->
</div><!--end: navigator 博客导航栏 -->
</div><!--end: header 头部 -->
<div id="main">
<div id="mainContent">
<div class="forFlow">
<!--done-->
</div><!--end: forFlow -->
</div><!--end: mainContent 主体内容容器-->
<div id="sideBar">
<div id="sideBarMain">
<!--done-->
<div class="newsItem">
<h3 class="catListTitle">公告</h3>
<div id="blog-news"></div><script type="text/javascript">loadBlogNews();</script>
</div>
<div id="blog-calendar" style="display:none"></div><script type="text/javascript">loadBlogDefaultCalendar();</script>
<div id="leftcontentcontainer">
<div id="blog-sidecolumn"></div><script type="text/javascript">loadBlogSideColumn();</script>
</div>
</div><!--end: sideBarMain -->
</div><!--end: sideBar 侧边栏容器 -->
<div class="clear"></div>
</div><!--end: main -->
<div class="clear"></div>
<div id="footer">
<!--done-->
Copyright ©2015 Giiku
</div><!--end: footer -->
</div><!--end: home 自定义的最大容器 -->
</body>
</html>
通过读取的html文本发现,访问该URL,服务器反馈给我们的信息,只有一部分数据,根本不存在圆龄、粉丝、关注等数据。原因在于这些数据是通过异步加载的方式读取的,所以只需要知道对应加载的URL链接,就可以获取这些数据。使用谷歌浏览器,右键审查元素,点击Network,就可以看到访问博客首页时,对资源的请求情况。
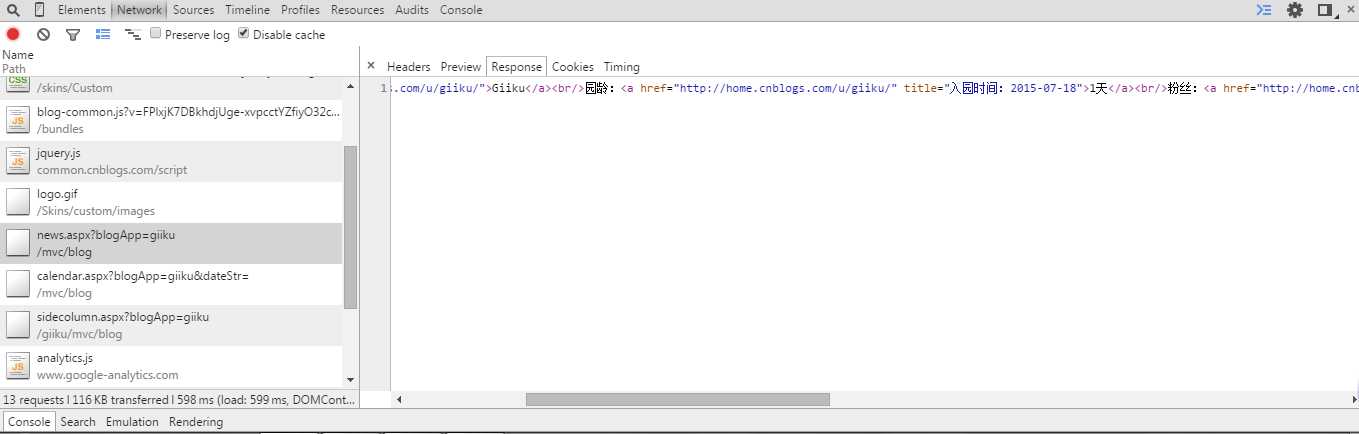
从上图,可以发现访问http://www.cnblogs.com/mvc/blog/news.aspx?blogApp=giiku该地址,服务器将会提供园龄、粉丝、关注等数据。现在分析下该URL,该URL是由"http://www.cnblogs.com/mvc/blog/news.aspx?blogApp="以及用户账号组合而成的。那么相当于只要我们知道用户的账号,我们就可以获取这部分数据。
假设已经获取到该页面的文本了,那么现在开始对文本数据进行处理,提取出需要的数据。
1 <div id="blog-news">
2 <div id="profile_block">
3 昵称:<a href="http://home.cnblogs.com/u/giiku/">Giiku</a><br>
4 园龄:<a href="http://home.cnblogs.com/u/giiku/" title="入园时间:2015-07-18">1天</a><br>
5 粉丝:<a href="http://home.cnblogs.com/u/giiku/followers/">0</a><br>
6 关注:<a href="http://home.cnblogs.com/u/giiku/followees/">0</a>
7 <div id="p_b_follow"></div>
8 </div>
9 </div>
先需要设置几个关键字,来定位下数据的大概位置以及判断是否存在该数据。这里选取“入园时间”、“followers”、“followees”作为关键字。
通过关键字定位到大概位置,再找到开口<a>的结束位置以及闭合</a>的位置,这样就可以获取到标签a的文本内容了。
public String getAContent(String html, String keyword){
int index = html.indexOf(keyword);
index = html.indexOf(">", index);
html = html.substring(index+1, html.indexOf("</a>", index));
return html;
}
现在我们来获取文章数、阅读数、评论数、积分、排名、推荐数、反对数等数据。
关于文章数,刚才上文在也看到了,博客首页是有显示文章数的,是可以直接抓取下来的。但是存在一个问题,由于大家的BLOG页面布局都不同,在你的BLOG里可能显示文章-0,而在他的BLOG里可能就Article-0。对于“文章”这一名词有很多的表示方法,所以如何确定关键字就成了一个问题。同时阅读数、评论数、推荐数及反对数需要我们到具体的文章里面去查看,然后进行总计。那么我们就必须要准备一个List来存放该博客所有的文章的链接,然后通过访问每一个链接,获取数据。这里我们新建一个实体类Article,存放文章的URL、文章的阅读数、评论数、推荐数、反对数。
现在来考虑下如何获取所有文章的链接?这里获取的方式有很多种,我来介绍一下,我发现的一种。
随便打开一个博客,进入首页,你会发现首页会陈列最新的几篇博文,如果博主博文比较多的话,提供了一个分页的机制。点击“下一页”,然后在第二页里就会显示该博主共有几页博文。现在看下该URL:http://www.cnblogs.com/huxiao-tee/default.html?page=2。page=2表示了现在查看的是第二页,现在改下数据,改成page=1。相当于回到了首页,也不显示共几页博文了。那么我们知道了,在博文的第二页,我们可以看到博主共有几页博文。如果该博主只有一页博文呢?我们令page=2会怎样的?通过实践观察发现,如果指定的page页数大于实际存在的页面,那么显示的页面就是博文的第一页。然后博文第一页是没有显示博主共几页的博文的。通过这一发现,我们可以访问每个博客第二页的URL,如果能获取到“共x页”的数据,那么就获得了所有文章的页数了。如果不能获取该数据,说明文章只有一页(甚至连一页也没有,当然也包括在一页的情况中)。
//获取页数
public int getPages(String html){
int index = html.indexOf(PAGES);
System.out.println(index);
if(index == -1){
return 1;//不一定是0 可能是1
}
int begin = html.indexOf("共", index);
int end = html.indexOf("页", begin);
System.out.println(html);
String str = html.substring(begin+1, end);
return Integer.parseInt(str);
}
现在知道了页数这个数据了该如何利用呢?首先这个URL:http://www.cnblogs.com/huxiao-tee/default.html?page=2的变量是页数,如果我们知道了总页数,就可以获取第一页到最后一页的URL的数据。通过这些URL,就可以抓取每一页文章的链接了,然后就可以获得所有文章的链接,相当于也知道了文章的数量。这里怎么抓取文章链接,具体做法跟上面差不多,根据关键字定位,获取相应的数据。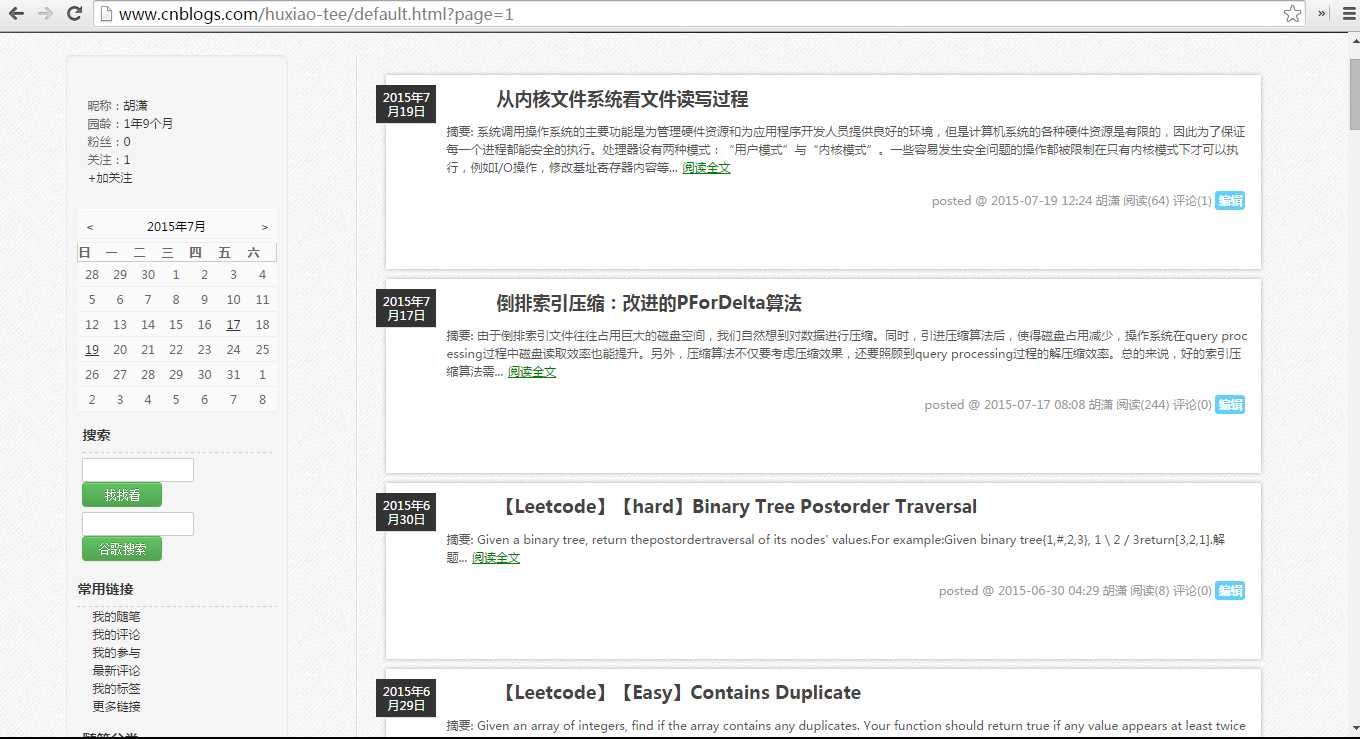
现在来讲下,如果获取文章的阅读数、评论数、推荐数、反对数的数据。
通过读取文章的URL,获取文本的html发现,这部分数据也是通过异步加载的。直接读取文章的URL,是获得不了这部分数据的。到谷歌浏览器的控制台里查看,发现
http://www.cnblogs.com/mvc/blog/ViewCountCommentCout.aspx?postId=4590118 返回了阅读数
http://www.cnblogs.com/mvc/blog/GetComments.aspx?postId=4590118&blogApp=huxiao-tee&pageIndex=0&anchorCommentId=0&_=1437286041334 返回了关于评论的json其中包括评论数
http://www.cnblogs.com/mvc/blog/BlogPostInfo.aspx?blogId=166017&postId=4590118&blogApp=huxiao-tee&blogUserGuid=63156ca7-762b-e311-8d02-90b11c0b17d6&_=1437286041383 返回了包含推荐数、反对数信息的页面
URL都是常量和变量组合而成的,变量相当于请求参数。我们只要知道这些请求参数,就可以获取这些数据。通过观察URL,我们需要postId(文章编号)、blogApp(用户名)、blogUserGuid(用户唯一标识)、blogId(博客编号)。第二个URL中包含pageIndex=0&anchorCommentId=0这两个参数,这里仅仅获取评论数的话,都默认为0就可以了。然后还有一个变量时没有名字,第二个URL中是_=1437286041334,第三个URL中是_=1437286041383,那么这个数据是什么呢?其实是一个long类型的时间,表示当前请求数据的时间 ,以便返回最新的数据。所以我们总共需要postId、blogApp、blogUserGuid 、time这4项数据。time的话,可以通过new Date()然后转换成long类型来获取。postId、blogApp、BlogUserGuid可以通过文章的URL中获取,其中blogApp、BlogUserGuid只需要获取一次,因为一个博客里面他们是唯一的。
任意一篇文章中都包含以下JS,其中包括了cb_blogId、cb_blogApp、cb_blogUserGuid、cb_entryId变量。通过发现比较就可以知道cb_entryId就是postId,文章的URL中其实也包含了postId。那么这些请求参数,我们都知道了。现在就可以通过编码,获取这些参数,然后再根据参数构建URL,到指定的页面中抓取数据。
<script type="text/javascript">var allowComments=true,isLogined=true,cb_blogId=166017,cb_entryId=4590118,cb_blogApp=currentBlogApp,cb_blogUserGuid=‘63156ca7-762b-e311-8d02-90b11c0b17d6‘,cb_entryCreatedDate=‘2015/6/20 4:04:00‘;loadViewCount(cb_entryId);</script>
标签:
原文地址:http://www.cnblogs.com/giiku/p/4658500.html
