标签:style blog class code java color
awk 中除了函数的参数列表(Argument List)上的参数(Arguments)外,所有变量不管于何处出现,全被视为全局变量。其生命持续至程序结束——该变量不论在function外或 function内皆可使用,只要变量名称相同所使用的就是同一个变量,直到程序结束。因递归函数内部的变量,会因它调用子函数(本身)而重复使用,故编写该类函数时应特别留心。
例如:执行

awk ‘ BEGIN { x = 35 y = 45 test_variable( x ) printf("Return to main : arg1= %d, x= %d, y= %d, z= %d\n", arg1, x, y, z) } function test_variable( arg1 ) { arg1++ # arg1 为参数列上的参数, 是local variable. 离开此函数后将消失. y++ # 会改变主式中的变量 y z = 55 # z 为该函数中新使用的变量, 主程序中变量 z 仍可被使用. printf("Inside the function: arg1=%d, x=%d, y=%d, z=%d\n", arg1, x, y, z) } ‘
结果屏幕打印出
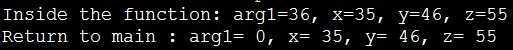
由上可知:
此特性优劣参半,最大的坏处是程序中的变量不易被保护,特别是递归调用本身,执行子函数时会破坏父函数内的变量。
一个变通的方法是:在函数的参数列中虚列一些参数。函数执行中使用这些虚列的参数来记录不想被破坏的数据,如此执行子函数时就不会破坏到这些数据。此外awk 并不会检查调用函数时所传递的参数个数是否一致。
例如:定义递归函数如下:
function demo( arg1 ) { # 最常见的错误例子 ........ for(i=1; i< 20 ; i++){ demo(x) # 又调用本身. 因为 i 是 global variable, 故执行完该子函数后 # 原函数中的 i 已经被坏, 故本函数无法正确执行. ....... } .......... }
可将上列函数中的 i 虚列在该函数的参数列上,如此 i 便是一个局部变量,不会因执行子函数而被破坏。
将上列函数修改如下:
function demo( arg1, i ) { ...... for(i=1; i< 20; i++) { demo(x) #awk不会检查呼叫函数时, 所传递的参数个数是否一致 ..... } }
$0, $1,.., NF, NR,..也都是 global variable,读者于递归函数中若有使用这些内置变量,也应另外设立一些局部变量来保存,以免被破坏。
范例:以下是一个常见的递归调用范例。它要求使用者输入一串元素(各元素间用空白隔开) 然后打印出这些元素所有可能的排列。
编辑如下的awk程序,取名为 permu
awk ‘ BEGIN { print "请输入排列的元素,各元素间请用空白隔开" getline permutation($0, "") printf("\n共 %d 种排列方式\n", counter) } function permutation( main_lst, buffer, new_main_lst, nf, i, j ) { $0 = main_lst # 把main_lst指定给$0之后awk将自动进行字段分割. nf = NF # 故可用 NF 表示 main_lst 上存在的元素个数. # BASE CASE : 当main_lst只有一个元素时. if( nf == 1){ print buffer main_lst #buffer的内容再加上main_lst就是完成一次排列的结果 counter++ return } # General Case : 每次从 main_lst 中取出一个元素放到buffer中 # 再用 main_lst 中剩下的元素 (new_main_lst) 往下进行排列 else for( i=1; i<=nf ;i++) { $0 = main_lst # $0为全局变量已被破坏, 故重新把main_lst赋给$0,令awk再做一次字段分割 new_main_lst = "" for(j=1; j<=nf; j++) # 连接 new_main_lst if( j != i ) new_main_lst = new_main_lst " " $j permutation( new_main_lst, buffer " " $i ) } } ‘ $*
执行
$ ./permu
屏幕上出现提示信息,若输入 1 2 3 回车,结果打印出:

说明:
1. 有些较旧版的awk,并不容许使用者指定$0的值。此时可改用gawk 或 nawk。否则也可自行使用 split() 函数来分割 main_lst。
2. 为避免执行子函数时破坏 new_main_lst, nf, i, j 故把这些变量也列于参数列上。如此,new_main_lst, nf, i, j 将被当成局部变量,而不会受到子函数中同名的变量影响。读者声明函数时,参数列上不妨将这些 "虚列的参数" 与真正用于传递信息的参数间以较长的空白隔开,以便于区别。
3. awk 中欲将字符串concatenation(连接)时,直接将两字符串并置即可(Implicit Operator)。
例如:
awk ‘ BEGIN{ A = "This " B = "is a " C = A B "key." # 变量A与B之间应留空白,否则"AB"将代表另一新变量. print C } ‘
结果将印出

4. awk使用者所编写的函数可再重用,并不需要每个awk式中都重新编写。
将函数部分单独编写于一文件中,当需要用到该函数时再以下列方式include进来。
$ awk -f 函数文件名 -f awk主程序文件名 数据文件文件名
【译】 AWK教程指南 11递归程序,布布扣,bubuko.com
标签:style blog class code java color
原文地址:http://www.cnblogs.com/qieerbushejinshikelou/p/3705541.html