标签:
目录: 一、 针对这次装B 的解释
四、 查询
四、 查询
1. 查询的官网的文档
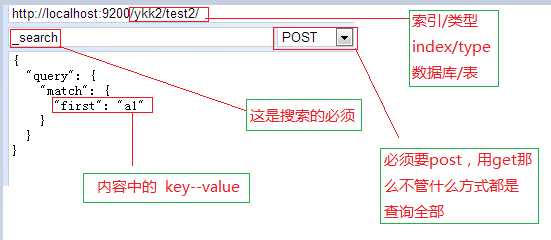
- took —— Elasticsearch执行这个搜索的耗时,以毫秒为单位- timed_out —— 指明这个搜索是否超时
- _shards —— 指出多少个分片被搜索了,同时也指出了成功/失败的被搜索的shards的数量
- hits —— 搜索结果
- hits.total —— 能够匹配我们查询标准的文档的总数目
- hits.hits —— 真正的搜索结果数据(默认只显示前10个文档)- _score和max_score —— 现在先忽略这些字段
"query":{"match":{"UserName":"BWH-PC"}}
{"query": {"match": {"text": "quick fox"}}}相当于{"query": {"bool": {"should": [{"term": { "text": "quick" }},{"term": { "text": "fox" }}]}}}
{"query": {"multi_match": {"query": "bbc0641345dd8224ce81bbc79218a16f","operator": "or","fields": ["*.machine"]}}}
{"bool": {"must": { "match": { "title": "how to make millions" }},"must_not": { "match": { "tag": "spam" }},"should": [{ "match": { "tag": "starred" }},{ "range": { "date": { "gte": "2014-01-01" }}}]}}
"term": {"CapabilityDescriptions": "aa"}
{"query": {"bool": {"should": [{ "constant_score": {"query": { "match": { "description": "wifi" }}}},{ "constant_score": {"query": { "match": { "description": "garden" }}}},{ "constant_score": {"boost": 2"query": { "match": { "description": "pool" }}}}]}}}
missing相当于is null【没查到的是null】
"query": {"filtered": {"query": { "match": { "email": "business opportunity" }},"filter": { "term": { "folder": "inbox" }}}}}
{"query": {"filtered": {"filter": {"bool": {"must": { "term": { "folder": "inbox" }},"must_not": {"query": {"match": { "email": "urgent business proposal" }}}}}}}}
"range" : {"price" : {"gt" : 20,"lt" : 40}}--------------------------{"query" : {"filtered" : {"filter" : {"range" : {"price" : {"gte" : 20,"lt" : 40}}}}}}----------------------"range" : {"timestamp" : {"gt" : "2014-01-01 00:00:00","lt" : "2014-01-07 00:00:00"}}到所有最近一个小时的文档:"range" : {"timestamp" : {"gt" : "now-1h"}}
后置过滤--post_filter元素是一个顶层元素,只会对搜索结果进行过滤。警告:性能考量只有当你需要对搜索结果和聚合使用不同的过滤方式时才考虑使用post_filter。有时一些用户会直接在常规搜索中使用post_filter。不要这样做!post_filter会在查询之后才会被执行,因此会失去过滤在性能上帮助(比如缓存)。post_filter应该只和聚合一起使用,并且仅当你使用了不同的过滤条件时。
eg:查询machine是bbc0641345dd8224ce81bbc79218a16f,不管是否被字段包,都需要过滤出来{"query": {"query_string": {"query": "*"}},"post_filter": {"bool": {"should":{"query": {"bool": {"should": [{"match": {"machine": "bbc0641345dd8224ce81bbc79218a16f"}},{"match": {"machine": "bbc0641345dd8224ce81bbc79218a16f"}}]}}}}}}当然,在里面的每一个should中,可以去做很多变形,但是should多个子类时,必须用[]{"query": {"query_string": {"query": "*"}},"post_filter": {"bool": {"should": [{"query": {"bool": {"must": [{"multi_match": {"query": "bbc0641345dd8224ce81bbc79218a16f","operator": "or","fields": ["*.machine",""]}},{"multi_match": {"query": "10.10.185.99","operator": "or","fields": ["*.IPAddress",""]}}]}}},{"query": {"bool": {"must": [{"match": {"machine": "bbc0641345dd8224ce81bbc79218a16f"}},{"match": {"IPAddress": "10.10.11.11"}}]}}}]}}}


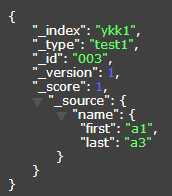
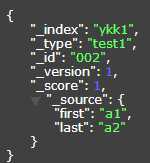
{"query": {"filtered": {"query": {"query_string": {"query": "*"}},"filter": {"bool": {"should": {"query": {"bool": {"should": [{"multi_match": {"query": "a2","operator": "or","fields": ["*.last"]}},{"match": {"last": "a2"}}]}}}}}}}}
标签:
原文地址:http://www.cnblogs.com/ykkBlog/p/4667857.html