outbust speech recognition, feature compensation, model compensation
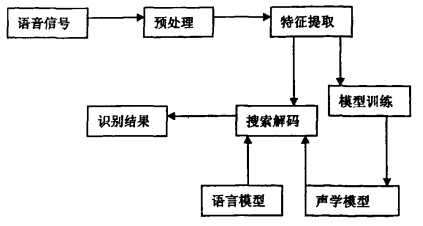
语音识别系统:语音的声学模型(训练学习)、模式匹配(识别算法)| 语言模型 语言处理
声学模型:动态时间归整模型 (DTW)、
隐马尔可夫模型(HMM)、人工神经网络模型(ANN)目前研究的难点主要表现在:(1)语音识别系统的适应性差。主要体现在对环境依赖性强。(2)高噪声环境下语音识别进展困难,因为此时人的发音变化很大,像声音变高,语速变慢,音调及共振峰变化等等,必须寻找新的信号分析处理方法。(3)如何把语言学、生理学、心理学方面知识量化、建模并有效用于语音识别,目前也是一个难点。(4)由于我们对人类的听觉理解、知识积累和学习机制以及大脑神经系统的控制机理等方面的认识还很不清楚,这必将阻碍语音识别的进一步发展。
目前语音识别领域的研究热点包括:稳健语音识别(识别的鲁棒性)、语音输入设备研究、声学HMM模型的细化、说话人自适应技术、大词汇量关键词识别、高效的识别(搜索)算法研究、可信度评测算法研究、ANN的应用、语言模型及深层次的自然语言理解。
说话人自适应技术 (Speaker Adaptation ,SA);非特定人 (Speaker Independent ,SI);特定人 (Speaker Dependent ,SD) 『SA+SI』music search, search engine, mobile internet, music retrieval, audio information retrieval, Adaptive music retrieval ,Music information retrieval
text classification、maximum entropy model
最大熵:它反映了人类认识世界的一个朴素原则,即在对某个事件一无所知的情况下,选择一个模型使它的分布应该尽可能均匀
raw audio
NLP: Natural Language Processing
词类区分(POS: Part-of-Speech tagging)
word accuracy, hit and miss rates, response time,efficiency, precision and system compatibility
WIKI:
Document Retrieval / text retrieval : form based『suffix tree』 content based 『inverted index』
Full text Research / free-text : a search engine examines all of the words in every stored document " Text retrieval is a critical area of study today, since it is the fundamental basis of all internet search engines." String Searching : string matching
Indexing
When dealing with a small number of documents, it is possible for the full-text-search engine to directly scan the contents of the documents with each query, a strategy called "serial scanning." This is what some tools, such as grep, do when searching.
However, when the number of documents to search is potentially large, or the quantity of search queries to perform is substantial, the problem of full-text search is often divided into two tasks: indexing and searching. The indexing stage will scan the text of all the documents and build a list of search terms (often called an index, but more correctly named a concordance). In the search stage, when performing a specific query, only the index is referenced, rather than the text of the original documents.
The indexer will make an entry in the index for each term or word found in a document, and possibly note its relative position within the document. Usually the indexer will ignore stop words (such as "the" and "and") that are both common and insufficiently meaningful to be useful in searching. Some indexers also employ language-specific stemming on the words being indexed. For example, the words "drives", "drove", and "driven" will be recorded in the index under the single concept word "drive."
Music Information Retrieval:
Track separation and instrument recognition
Automatic music transcription : converting an audio recording into symbolic notation
"multi-pitch detection, onset detection, duration estimation, instrument identification, and the extraction of rhythmic information" Automatic categorization
Music generation