标签:style blog width 2014 http 文件
之前在写MR job的时候,由于要在云梯,或者一淘的开发集群上运行;所以处理方法是,在本地打成jar包,然后scp到客户端网关机上,然后在提交job运行。这样的问题时,有时候如果遇到一些逻辑上的问题,job跑挂了。必须在本地修改程序,然后重新打包,scp,再运行,这样比较麻烦;询问了一圈,觉得采用MRUnit在本地做好一些逻辑测试。这样可以在一定程度上提高开发效率,避免重复劳动,并且写好的testcase可以用作回归之用;
MRUnit
基本原理是JUnit和EasyMock,其核心的单元测试依赖于JUnit,并且MRUnit实现了一套Mock对象来控制MapReduce框架的输入和输出;语法也比较简单,使用的时候需要从官网http://mrunit.apache.org/下载jar包;下面上代码,为了演示简便,测试的类是hadoop examples中自带的WordCount。
代码:
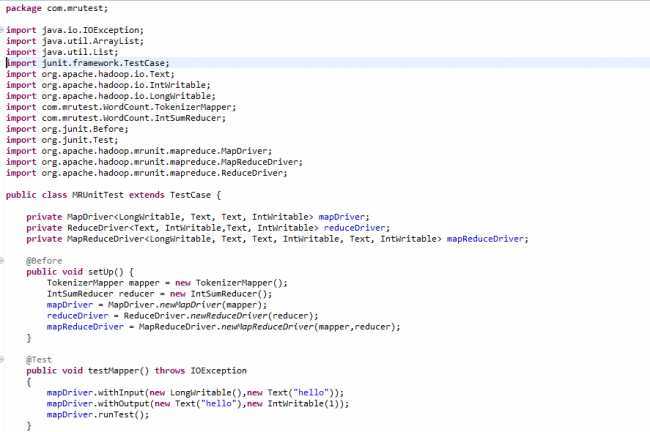

如果有若干个连续的MR job需要测试,MRUnit框架中还有PipelineMapReduceDriver可用,
在下一章中,将研究一些MRUnit更深的特性和使用 文件 作为测试用例输入集的做法;
Hadoop MRUnit使用(一),布布扣,bubuko.com
标签:style blog width 2014 http 文件
原文地址:http://www.cnblogs.com/yuhan-TB/p/3705628.html