1. 预备知识:
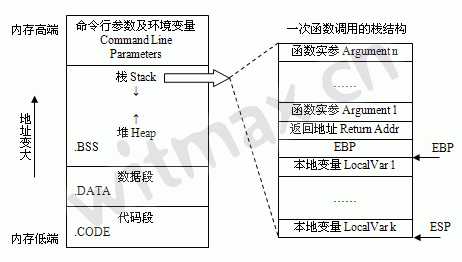

当发生函数调用的时候,栈空间中存放的数据是这样的:
1、调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中,即:从右向左依次把被调函数所需要的参数压入栈;
2、调用者函数使用call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中(这个压栈操作隐含在call指令中);
3、在被调函数中,被调函数会先保存调用者函数的栈底地址(push ebp),然后再保存调用者函数的栈顶地址,即:当前被调函数的栈底地址(mov ebp,esp);
4、在被调函数中,从ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小,即:这些变量的地址是按照栈的延伸方向排列的,先定义的变量先入栈,后定义的变量后入栈;
所以,发生函数调用时,入栈的顺序为:
参数N
参数N-1
.....
参数2
参数1
函数返回地址
上一层调用函数的EBP/BP
局部变量1
局部变量2
....
局部变量N
函数调用栈如下图所示:

#include <stdio.h>
#include <string.h>
struct C
{
int a;
int b;
int c;
};
int test2(int x, int y, int z)
{
printf("hello,test2\n");
return 0;
}
int test(int x, int y, int z)
{
int a = 1;
int b = 2;
int c = 3;
struct C st;
printf("addr x = %u\n",(unsigned int)(&x));
printf("addr y = %u\n",(unsigned int)(&y));
printf("addr z = %u\n",(unsigned int)(&z));
printf("addr a = %u\n",(unsigned int)(&a));
printf("addr b = %u\n",(unsigned int)(&b));
printf("addr c = %u\n",(unsigned int)(&c));
printf("addr st = %u\n",(unsigned int)(&st));
printf("addr st.a = %u\n",(unsigned int)(&st.a));
printf("addr st.b = %u\n",(unsigned int)(&st.b));
printf("addr st.c = %u\n",(unsigned int)(&st.c));
return 0;
}
int main(int argc, char** argv)
{
int x = 1;
int y = 2;
int z = 3;
test(x,y,z);
printf("x = %d; y = %d; z = %d;\n", x,y,z);
memset(&y, 0, 8);
printf("x = %d; y = %d; z = %d;\n", x,y,z);
return 0;
}
打印输出如下:
addr x = 4288282272
addr y = 4288282276
addr z = 4288282280
addr a = 4288282260
addr b = 4288282256
addr c = 4288282252
addr st = 4288282240
addr st.a = 4288282240
addr st.b = 4288282244
addr st.c = 4288282248
a = 1; b = 2; c = 3;
a = 0; b = 0; c = 3;示例效果图:


关于堆栈空间利用最核心的一点就是:函数调用栈。而要深入理解函数调用栈,最重要的两点就是:栈的结构变化,ebp寄存器的作用。
首先要认识到这样两个事实:
1. 一个函数调用动作可分解为:零到多个push指令(用于参数入栈),一个call指令。call指令内部其实还暗含了一个将eip返回地址(即call指令下一条指令的地址)压栈的动作。
2. 几乎所有本地编译器都会在每个函数体之前插入类似的指令:push %ebp,mov %esp %ebp。
因此,在程序执行到一个函数的真正函数体的时候,已经有以下数据压入到堆栈中:零到多个参数,返回地址eip,ebp。
由此得到如下的栈结构(其中参数入栈顺序跟调用方式有关,这里以C语言默认的CDECL为例):

“push %ebp”“mov %esp %ebp”这两条指令实在是太有深意了:首先将ebp入栈,然后将栈顶指针esp赋值给ebp。“mov %esp %ebp”这条指令表面上看是用esp把ebp原来的值覆盖了,其实不然,因为在给ebp赋值之前,原ebp值已经被压栈(位于栈顶),esp赋值给ebp后,ebp恰好指向栈顶(即被压栈的原esp的位置)。
此时,ebp寄存器就处在一个非常重要的地位,该寄存器中存储着栈中的一个地址(原ebp入栈后的栈顶),以该地址为基准,向上(栈底方向)能获取返回地址,函数调用参数值;向下(栈顶方向)能获取函数局部变量值;而该地址处又存储着上一层函数调用时的ebp值!!一般而言,ss:[ebp+4]处为返回地址,ss:[ebp+8]处为第一个参数值(最后一个入栈的参数值,此处假设其占用4字节内存),ss:[ebp-4]处为第一个局部变量,ss:[ebp]处为上一层ebp值。
由于ebp中的地址总是“上一层函数调用时的ebp值”,而在每一层函数调用中,都能通过当时的ebp值“向上(栈底方向)能获取返回地址、函数调用参数,向下(栈顶方向)能获取函数局部变量值”。如此形成递归,直至到达栈底。这就是函数调用栈。由此看见,编译器对于ebp寄存器的使用实在是太精妙了。
此外,从当前ebp出发,逐层向上找到所有的ebp是非常容易的
在此之前,我对C中函数调用过程中栈的变化,仅限于了解有好几种参数的入栈顺序,其中的按照形参逆序入栈是比较常见的,也仅限于了解到这个程度,但到底在一个函数A里面,调用另一个函数B的过程中,函数A的栈是怎么变化的,实参是怎么传给函数B的,函数B又是怎么给函数A返回值的,这些问题都不能很明白的一步一步解释出来。下面,便是用一个小例子来解释这个过程,主要回答的问题是如下几个:
1、函数A在执行到调用函数B的语句之前,栈的结构是什么样子?
2、函数A执行调用函数B这一条语句的过程中,A的栈是怎样的?
3、在执行调用函数B语句时,实参是调用函数A来传入栈,还是被调函数B来进行入栈?
4、实参的入栈顺序是怎样的?
5、执行调用函数B的过程中,函数A的栈又是怎样的,B的呢?
6、函数B执行完之后,发生了什么事情,怎样把结果传给了函数A中的调用语句处的参数(比如:A中int c = B_fun(...)这样的语句)?
7、调用函数的语句结束后,怎样继续执行A中之后的语句?
大概的问题也就这些,其实也就是整个过程中一些自己认为比较重要的步骤。接下来详细描述这个过程,以下先给出自己的C测试代码,和对应的反汇编代码。
C测试代码如下:(代码中自己关注的几个地方是L14 15 16 17)

1 int 2 fun(int *x, int *y) 3 { 4 int temp = *x; 5 *x = *y; 6 *y = temp; 7 8 return *x + *y; 9 } 10 11 int 12 main(void) 13 { 14 int a = 5; 15 int b = 9; 16 int c = 3; 17 c = fun(&a, &b); 18 a = 7; 19 b = 17; 20 return 0; 21 }
主要关注的地方是:
1、main中定义int变量 a b c 时,是怎样的定义顺序?
2、L17 的过程。
3、进入fun之后,的整个栈的结构。
1 080483b4 <fun>: 2 80483b4: 55 push %ebp 3 80483b5: 89 e5 mov %esp,%ebp 4 80483b7: 83 ec 10 sub $0x10,%esp 5 80483ba: 8b 45 08 mov 0x8(%ebp),%eax 6 80483bd: 8b 00 mov (%eax),%eax 7 80483bf: 89 45 fc mov %eax,-0x4(%ebp) 8 80483c2: 8b 45 0c mov 0xc(%ebp),%eax 9 80483c5: 8b 10 mov (%eax),%edx 10 80483c7: 8b 45 08 mov 0x8(%ebp),%eax 11 80483ca: 89 10 mov %edx,(%eax) 12 80483cc: 8b 45 0c mov 0xc(%ebp),%eax 13 80483cf: 8b 55 fc mov -0x4(%ebp),%edx 14 80483d2: 89 10 mov %edx,(%eax) 15 80483d4: 8b 45 08 mov 0x8(%ebp),%eax 16 80483d7: 8b 10 mov (%eax),%edx 17 80483d9: 8b 45 0c mov 0xc(%ebp),%eax 18 80483dc: 8b 00 mov (%eax),%eax 19 80483de: 01 d0 add %edx,%eax 20 80483e0: c9 leave 21 80483e1: c3 ret 22 23 080483e2 <main>: 24 80483e2: 55 push %ebp 25 80483e3: 89 e5 mov %esp,%ebp 26 80483e5: 83 ec 18 sub $0x18,%esp 27 80483e8: c7 45 f4 05 00 00 00 movl $0x5,-0xc(%ebp) 28 80483ef: c7 45 f8 09 00 00 00 movl $0x9,-0x8(%ebp) 29 80483f6: c7 45 fc 03 00 00 00 movl $0x3,-0x4(%ebp) 30 80483fd: 8d 45 f8 lea -0x8(%ebp),%eax 31 8048400: 89 44 24 04 mov %eax,0x4(%esp) 32 8048404: 8d 45 f4 lea -0xc(%ebp),%eax 33 8048407: 89 04 24 mov %eax,(%esp) 34 804840a: e8 a5 ff ff ff call 80483b4 <fun> 35 804840f: 89 45 fc mov %eax,-0x4(%ebp) 36 8048412: c7 45 f4 07 00 00 00 movl $0x7,-0xc(%ebp) 37 8048419: c7 45 f8 11 00 00 00 movl $0x11,-0x8(%ebp) 38 8048420: b8 00 00 00 00 mov $0x0,%eax 39 8048425: c9 leave 40 8048426: c3 ret
1、L24 执行push %ebp:main函数先保存之前函数(在执行到main之前的初始化函数,具体的细节可以参考程序员的自我修养这本书有讲整个程序执行的流程)的帧指针%ebp。此时,即进入了main函数的栈,图标描述如下
描述 | 内容 | 注释 |
main:%esp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
2、L25 执行mov %esp,%ebp:步骤1已经保存了之前函数的%ebp,接下来需要修改函数main的栈帧指针,指示main栈的开始,即修改%ebp,使其内容为寄存器%esp的内容(C描述为:%ebp = %esp),此时栈结构如下:
描述 | 内容 | 注释 |
main:%esp(%ebp) | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
3、L26 执行sub $0x18,%esp:此处即修改main函数栈的大小。由于linux里,栈增长的方向是从大到小,所以这里是%esp = %esp - $0x18;关于为什么减去$0x18,即十进制的24,深入理解计算机系统一书P154这样描述:“GCC坚持一个x86编程指导方针,也就是一个函数使用的所有栈空间必须是16字节的整数倍。包括保存%ebp值的4个字节和返回值的4个字节,采用这个规则是为了保证访问数据的严格对齐。”,所以这里main函数栈的大小 = 24 + 4 + 4 = 32(分配的24,保存%ebp的4,保存返回值的4)。此时栈结构如下:
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| %esp |
4、 L27 movl $0x5,-0xc(%ebp);L28 movl $0x9,-0x8(%ebp);L29 movl $0x3,-0x4(%ebp)这三行是定义的变量a b c。此时栈结构如下,可以看出来,变量的定义顺序不是按照在main里面声明的顺序定义的,这个我不是很懂,求指导。
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| %ebp - 0x4 | 3 | c = 3 |
| %ebp - 0x8 | 9 | b = 9 |
| %ebp - 0xc | 5 | a = 5 |
| %esp |
5、L30 lea -0x8(%ebp),%eax; L31 mov %eax,0x4(%esp)这两行是把变量b的地址赋值到%esp + 4,栈结构如下:
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| %ebp - 0x4 | 3 | c = 3 |
| %ebp - 0x8 | 9 | b = 9 |
| %ebp - 0xc | 5 | a = 5 |
| %esp + 0x4 | &b | 变量b的地址 |
| %esp |
6、L32 lea -0xc(%ebp),%eax; L33 mov%eax,(%esp)这两行是把变量a的地址赋值到%esp,栈结构如下:
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| %ebp - 0x4 | 3 | c = 3 |
| %ebp - 0x8 | 9 | b = 9 |
| %ebp - 0xc | 5 | a = 5 |
| %esp + 0x4 | &b | 变量b的地址 |
| %esp | &a | 变量a的地址 |
7、L34 call 80483b4 <fun>;可以看出这一行,即调用的是fun(int *, int *)函数,而且也从第6步知道实参是调用函数传入栈,且是逆序传入。这里call指令会把之后指令的地址压入栈,即L35的指令地址804840f。(从汇编代码看不出来这一步压栈的过程,但根据后续分析,这样是正确的,书上也是这么描述call指令的,怎样能直观的看到栈的变化,我不懂,哪位知道可以留言告诉我)此时栈的结构如下:
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| %ebp - 0x4 | 3 | c = 3 |
| %ebp - 0x8 | 9 | b = 9 |
| %ebp - 0xc | 5 | a = 5 |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| %esp | 804840f | 返回地址 |
到这一步,关于main函数栈的情况分析就到这里,接下来进入fun函数进行分析。
1、L2 push%ebp:同main函数第一步一样,先保存之前函数的栈帧,即保存main函数的帧指针%ebp,此时栈情况如下:
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| %ebp - 0x4 | 3 | c = 3 |
| %ebp - 0x8 | 9 | b = 9 |
| %ebp - 0xc | 5 | a = 5 |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| fun栈开始 | 被保存的main函数的%ebp |
2、L3 mov %esp,%ebp:同上述main描述里面步骤2,修改寄存器%ebp。栈如下:
| 描述 | 内容 | 注释 |
| main: | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 9 | b = 9 | |
| 5 | a = 5 | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| fun栈开始(%esp与%ebp) | 被保存的main函数的%ebp |
3、L4 sub $0x10,%esp:同上述main描述步骤3,修改函数fun的栈大小,(不明白的是这里怎么修改的大小为十进制16,这样加上其他的最后不是16的整数倍?)此时栈如下:
| 描述 | 内容 | 注释 |
| main: | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 9 | b = 9 | |
| 5 | a = 5 | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| fun栈开始(%ebp) | 被保存的main函数的%ebp | |
| %esp |
4、L5 mov 0x8(%ebp),%eax;L6 mov (%eax),%eax ;L7 mov%eax,-0x4(%ebp):这三行功能分别是把%eax = &a; %eax = a; %ebp - 0x4 = a;对应的是fun函数语句int temp = *a;其中,L7会改变栈的情况,此时栈如下:
| 描述 | 内容 | 注释 |
| main: | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 9 | b = 9 | |
| 5 | a = 5 | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| fun:%ebp | 被保存的main函数的%ebp | |
| %ebp - 0x4 | 5 | a = 5 |
| %esp |
5、L8 mov 0xc(%ebp),%eax;L9 mov (%eax),%edx;L10 mov 0x8(%ebp),%eax; L11 mov %edx,(%eax)对应功能分别是:get &b; get b; get &a; a = b。其中,只有L11会修改栈内容,栈内容如下:
| 描述 | 内容 | 注释 |
| main: | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 9 | b = 9 | |
| 9 | a = 9(修改了a的值) | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| fun:%ebp | 被保存的main函数的%ebp | |
| %ebp - 0x4 | 5 | a = 5 |
| %esp |
6、L12 mov 0xc(%ebp),%eax; L13 mov-0x4(%ebp),%edx;L14 mov %edx, (%eax):功能分别对应get &b; %edx = temp;b = a。其中L13会修改栈内容,具体栈情况更改如下:
| 描述 | 内容 | 注释 |
| main: | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 5 | b = 5(修改了b的值) | |
| 9 | a = 9(修改了a的值) | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| fun:%ebp | 被保存的main函数的%ebp | |
| %ebp - 0x4 | 5 | a = 5 |
| %esp |
7、然后就是L15,L16,L17,L18这4行分别得到&a, a, &b, b。这些都不会造成栈内容的变化。
L19 add %edx, %eax会计算出a + b的值,并把结果保存在寄存器%eax,也即返回值在%eax(这里大家都清楚,函数如果有返回值,一般都是保存在%eax)
8、L10 leave:深入理解计算机系统一书P151这样描述leave指令:
movl %ebp, %esp
popl %ebp
以下分两步来描述:
即先把寄存器%ebp赋值给%esp,其中%ebp保存的是之前main函数的%ebp,这一步修改了%esp的内容,即栈情况会发生变化。这一步之后栈情况为:
| 描述 | 内容 | 注释 |
| main: | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 5 | b = 5 | |
| 9 | a = 9 | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| %esp | 被保存的main函数的%ebp |
然后是popl %ebp,即把%ebp的内容恢复为之前main函数的帧指针,经过这一步之后%ebp指向了main栈的开始处:如下表示
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 5 | b = 5 | |
| 9 | a = 9 | |
| &b | 变量b的地址 | |
| &a | 变量a的地址 | |
| 804840f | 返回地址 | |
| %esp(%ebp) | 被保存的main函数的%ebp |
9、L21 ret:从栈中弹出地址,并跳转到这个位置。栈即如下:
| 描述 | 内容 | 注释 |
| main:%ebp | 被保存的start函数的%ebp | 每个函数开始前,先保存之前函数的帧指针%ebp |
| 3 | c = 3 | |
| 5 | b = 5 | |
| 9 | a = 9 | |
| &b | 变量b的地址 | |
| %esp | &a | 变量a的地址 |
到这里fun函数即执行完,然后又跳转到main函数开始执行后续指令。后续L35行用到的%eax即之前fun函数的返回值,L35 L36 L37都用到了%ebp,此时%ebp已经指向了main函数的帧指针,后面已经没有什么可以描述的了,最后还会修改变量a b c 的值,只需要相应的修改栈中内容即可,没有什么可说的了。
foo函数部分汇编:

foo函数push ebp, mov ebp, esp后
保存原ebp,设定新的ebp为当前esp位置

sub esp, 0E4h
给局部变量分配足够大的栈空间

保存原先的一些寄存器值,每次push,esp继续向下移

为局部变量a数组赋值

调用goo前Push两个参数,esp继续下移

call goo函数时,cpu自动push下一条指令地址,esp继续下移

在goo函数中,同样保存foo函数中的ebp值,设定新的ebp,esp等

在执行玩goo函数最后几句指令时,edi, esi, ebx恢复,esp同时也编程goo中ebp的位置,ebp恢复至foo函数原来的位置(pop ebp)
下一条指令也装入IP(ret指令),esp继续向上一步

foo函数中的add esp, 8将esp值继续往上(清除函数参数)
清除函数参数的工作也可通过ret X在goo函数返回时设定(这样的话不必在每次调用点上加上add esp, X指令缩短了编译出来的文件大小,但在子函数中清除将不能做到printf等的可变参数个数功能,因为子函数不知道具体有多少要参数进入了,只有调用处才知道)
版权声明:本文为【借你一秒】原创文章,转载请标明出处。
原文地址:http://blog.csdn.net/u013467442/article/details/47056881