标签:
一.链表
学习数据结构链表的时候,就有区分 带头结点的链表和不带头结点的链表
当时写完带头结点的链表的基本操作算法后,又写了一遍不带头结点的链表的基本操作。
发现是否带头结点的区别主要体现在2个操作的算法上:插入和删除
不带头结点的链表的插入和删除操作因为涉及对第一个结点插入删除,会改变头指针的值,需要对第一个结点单独分析,链表头指针形参上也因此上加入引用或者指针。
所以相对带头结点的链表操作上不带头结点的链表会更加麻烦。
插入算法上的差异:
1 //带头结点的链表 2 int insert(LINK H,int pos,STU x)/*插入*/ 3 { 4 LINK p,s;int k = 0; 5 p = H; 6 while(p != NULL && k < pos-1) 7 { 8 p = p->next; 9 k++; 10 } 11 if(p==NULL || k > pos-1) 12 { 13 printf("the position is illegal...insert fained\n"); 14 return 0; 15 } 16 s = new NODE; 17 s->data = x; 18 s->next = p->next; 19 p->next = s; 20 printf("Insert finished...\n"); 21 return 1; 22 } 23 //不带头结点的链表 24 int insert(LINK &H,int pos,STU x)//插入 25 { 26 LINK p = H,s; 27 int k=1; 28 if(pos == 1)//插入pos是1的情况 29 { 30 s = new NODE; 31 s->data = x; 32 s->next = H; 33 H = s; 34 return 1; 35 } 36 while(p != NULL && k < pos-1) 37 { 38 p = p->next; 39 k++; 40 } 41 if(p == NULL || k > pos-1) 42 { 43 printf("the position is illegal,insert failed....\n"); 44 return 0; 45 } 46 s = new NODE; 47 s->data = x; 48 s->next = p->next; 49 p->next = s; 50 return 1; 51 }
从上面的代码可以清晰的看到不带头结点的链表的插入算法的区别:
1.形参上头结点使用了引用,插入位置为第一个位置时需要对头指针的值进行修改。
2.插入需要对第一个结点进行单独分析,相比带头结点的算法多了这段代码:
28 if(pos == 1)//插入pos是1的情况
29 {
30 s = new NODE;
31 s->data = x;
32 s->next = H;
33 H = s;
34 return 1;
35 }
删除算法上的差异:
1 //带头结点的链表的删除算法 2 int deletenode(LINK H,int pos)/*删除*/ 3 { 4 LINK p,q;int k = 0; 5 p = H; 6 if(H == NULL || H->next == NULL) 7 { 8 printf("链表为空,请先创建链表...\n"); 9 return 0; 10 } 11 while(p->next != NULL && k < pos-1) 12 { 13 p = p->next; 14 k++; 15 } 16 if(p->next == NULL || k > pos-1) 17 { 18 printf("位置不合法,删除失败...\n"); 19 return 0; 20 } 21 q = p->next; 22 p->next = q->next; 23 free(q); 24 printf("删除完成....\n"); 25 return 1; 26 } 27 //不带头结点的删除算法 28 int deletenode(LINK &H,int pos)//删除 29 { 30 LINK p = H,q;int k = 1; 31 if(H == NULL) //空链表不执行删除操作 32 { 33 printf("this is an empty link list,can not execute the delete function\n"); 34 return 0; 35 } 36 if(pos == 1) 37 { 38 H = H->next; 39 delete p; 40 return 1; 41 } 42 while(p->next !=NULL && k < pos-1) 43 { 44 p = p->next; 45 k++; 46 } 47 if(p->next == NULL || k > pos-1) 48 { 49 printf("the position is illegal,delete failed...\n"); 50 return 0; 51 } 52 q = p->next; 53 p = q->next; 54 delete q; 55 return 1; 56 } 57 //以两个算法的区别和插入算法类似,都是因为第一个结点特殊考虑导致
差异原因类似插入算法,此处不再赘述。
二:栈和队列
链栈:实际上就是链表的一种特殊形式,对插入和删除结点进行了约束和明文规定,先进后出,既插入和删除都只能在栈顶完成,栈底不允许操作。
链队列:也是一种链表的特殊形式,与链栈不同的是,队列要求入队只能在队尾,出队只能在队头,也是对插入和删除进行了约束。
还记得上林老师得数据结构这课时,老师只是说了链栈不带头结点,链队列要带头结点,当时有些迷惑,不太明白,只是按部就班的码代码时按要求做了。
后来百度了一下为什么,发现百度上没有相关的东西,只是说到链栈就是不带头结点,链队列就得带头结点。
下面的是一些自己的思考,正确性尚待考证,但是估计八九不离十吧。
首先链栈,因为链栈只涉及到栈顶的操作,既相当于插入和删除都是在栈顶,所以带不带头结点都无所谓,算法都只需要对第一个结点的情况进行考虑
但是出于空间的考虑,所以链栈不带头结点,并且认为链表头为栈顶,入栈就是链表的头插,出栈就是删除头结点。
图为入栈示意图:
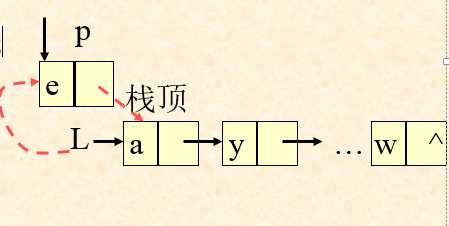
嗯,也正是为了方便,所以链栈里面的插入操作都是头插
然后链队列,链队列一般有两种存储结构:
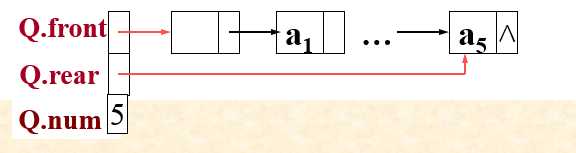
1.双头不循环链队列
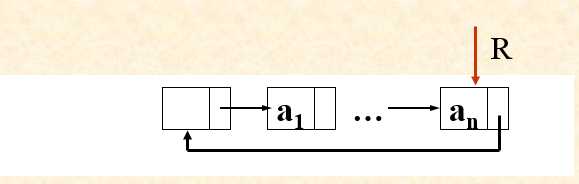
2.带尾指针的循环队列
无论链队列是那种存储结构,每插入和删除一个结点都需要对头指针进行修改,并且都需要带上头结点。
链队列带上头结点是为了操作方便,否则当不带头结点之后,可以想象每当处理第一个结点时,操作会变得相当的复杂,并且头指针还得赋值为NULL。
比如:第一种双头不循环的队列,出队列时,当队列里面只有一个结点时,Q.front,Q.rear都会和之前的出队列操作不同。
同理尾指针的循环队列也是。
总的来说,既带头结点可以避免以为因为第一个结点的操作而带来的特殊情况,方便编程。
嗯嗯,所以在不同的实际需求情况下,数据结构需要灵活变化,有时候会是几种数据结构的组合,具体情况要具体分析,体会到是否带头结点的差异。
才能构造出好的结构,写出好的程序。

标签:
原文地址:http://www.cnblogs.com/ecizep/p/4676846.html